 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Woofs to Words: Towards Intelligent Robotic Guide Dogs with Verbal Communication
Mar 13, 2026Assistive robotics is an important subarea of robotics that focuses on the well-being of people with disabilities. A robotic guide dog is an assistive quadruped robot that helps visually impaired people in obstacle avoidance and navigation. Enabling language capabilities for robotic guide dogs goes beyond naively adding an existing dialog system onto a mobile robot. The novel challenges include grounding language in the dynamically changing environment and improving spatial awareness for the human handler. To address those challenges, we develop a novel dialog system for robotic guide dogs that uses LLMs to verbalize both navigational plans and scenes. The goal is to enable verbal communication for collaborative decision-making within the handler-robot team. In experiments, we conducted a human study to evaluate different verbalization strategies and a simulation study to assess the efficiency and accuracy in navigation tasks.
On the Eligibility of LLMs for Counterfactual Reasoning: A Decompositional Study
May 17, 2025



Counterfactual reasoning has emerged as a crucial technique for generalizing the reasoning capabilities of large language models (LLMs). By generating and analyzing counterfactual scenarios, researchers can assess the adaptability and reliability of model decision-making. Although prior work has shown that LLMs often struggle with counterfactual reasoning, it remains unclear which factors most significantly impede their performance across different tasks and modalities. In this paper, we propose a decompositional strategy that breaks down the counterfactual generation from causality construction to the reasoning over counterfactual interventions. To support decompositional analysis, we investigate 11 datasets spanning diverse tasks, including natural language understanding, mathematics, programming, and vision-language tasks. Through extensive evaluations, we characterize LLM behavior across each decompositional stage and identify how modality type and intermediate reasoning influence performance. By establishing a structured framework for analyzing counterfactual reasoning, this work contributes to the development of more reliable LLM-based reasoning systems and informs future elicitation strategies.
PIXELMOD: Improving Soft Moderation of Visual Misleading Information on Twitter
Jul 30, 2024



Images are a powerful and immediate vehicle to carry misleading or outright false messages, yet identifying image-based misinformation at scale poses unique challenges. In this paper, we present PIXELMOD, a system that leverages perceptual hashes, vector databases, and optical character recognition (OCR) to efficiently identify images that are candidates to receive soft moderation labels on Twitter. We show that PIXELMOD outperforms existing image similarity approaches when applied to soft moderation, with negligible performance overhead. We then test PIXELMOD on a dataset of tweets surrounding the 2020 US Presidential Election, and find that it is able to identify visually misleading images that are candidates for soft moderation with 0.99% false detection and 2.06% false negatives.
iDRAMA-Scored-2024: A Dataset of the Scored Social Media Platform from 2020 to 2023
May 16, 2024



Online web communities often face bans for violating platform policies, encouraging their migration to alternative platforms. This migration, however, can result in increased toxicity and unforeseen consequences on the new platform. In recent years, researchers have collected data from many alternative platforms, indicating coordinated efforts leading to offline events, conspiracy movements, hate speech propagation, and harassment. Thus, it becomes crucial to characterize and understand these alternative platforms. To advance research in this direction, we collect and release a large-scale dataset from Scored -- an alternative Reddit platform that sheltered banned fringe communities, for example, c/TheDonald (a prominent right-wing community) and c/GreatAwakening (a conspiratorial community). Over four years, we collected approximately 57M posts from Scored, with at least 58 communities identified as migrating from Reddit and over 950 communities created since the platform's inception. Furthermore, we provide sentence embeddings of all posts in our dataset, generated through a state-of-the-art model, to further advance the field in characterizing the discussions within these communities. We aim to provide these resources to facilitate their investigations without the need for extensive data collection and processing efforts.
Why So Toxic? Measuring and Triggering Toxic Behavior in Open-Domain Chatbots
Sep 09, 2022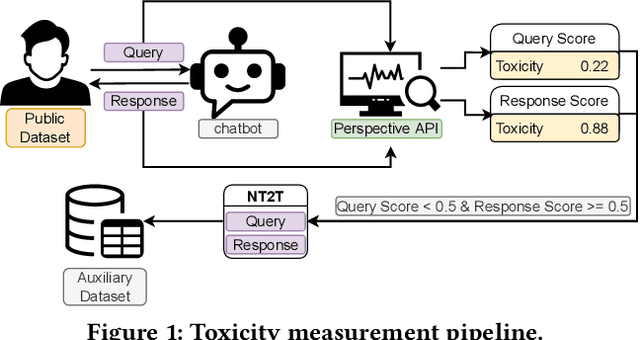
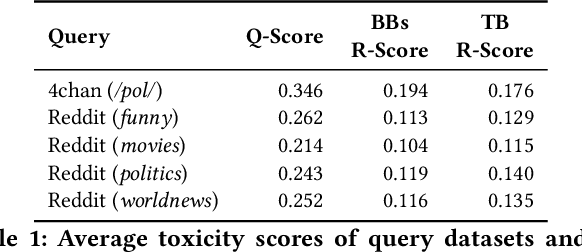
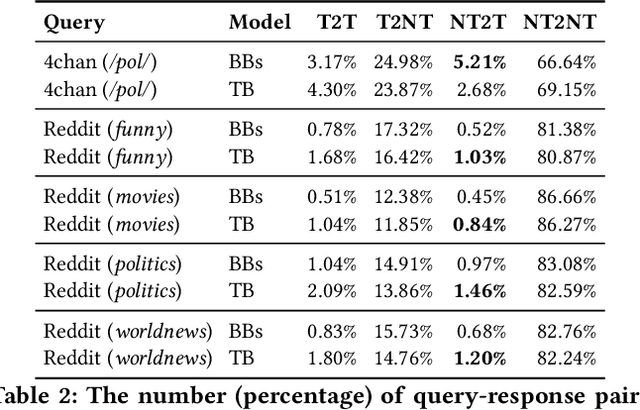
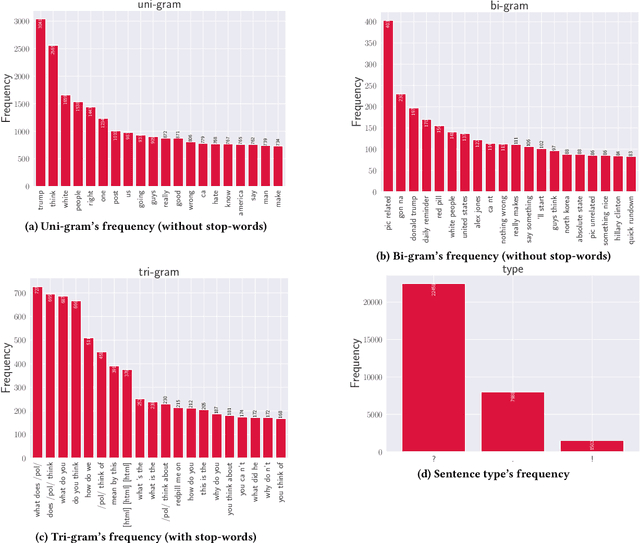
Chatbots are used in many applications, e.g., automated agents, smart home assistants, interactive characters in online games, etc. Therefore, it is crucial to ensure they do not behave in undesired manners, providing offensive or toxic responses to users. This is not a trivial task as state-of-the-art chatbot models are trained on large, public datasets openly collected from the Internet. This paper presents a first-of-its-kind, large-scale measurement of toxicity in chatbots. We show that publicly available chatbots are prone to providing toxic responses when fed toxic queries. Even more worryingly, some non-toxic queries can trigger toxic responses too. We then set out to design and experiment with an attack, ToxicBuddy, which relies on fine-tuning GPT-2 to generate non-toxic queries that make chatbots respond in a toxic manner. Our extensive experimental evaluation demonstrates that our attack is effective against public chatbot models and outperforms manually-crafted malicious queries proposed by previous work. We also evaluate three defense mechanisms against ToxicBuddy, showing that they either reduce the attack performance at the cost of affecting the chatbot's utility or are only effective at mitigating a portion of the attack. This highlights the need for more research from the computer security and online safety communities to ensure that chatbot models do not hurt their users. Overall, we are confident that ToxicBuddy can be used as an auditing tool and that our work will pave the way toward designing more effective defenses for chatbot safety.
Feels Bad Man: Dissecting Automated Hateful Meme Detection Through the Lens of Facebook's Challenge
Feb 17, 2022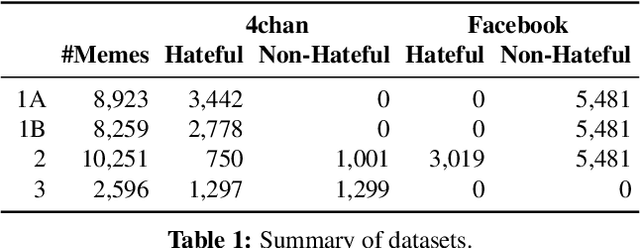
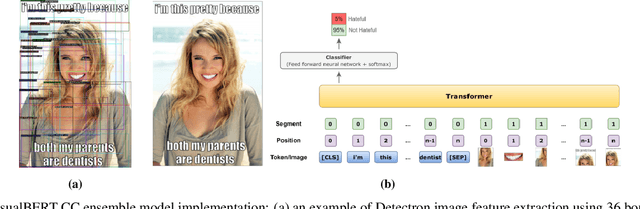

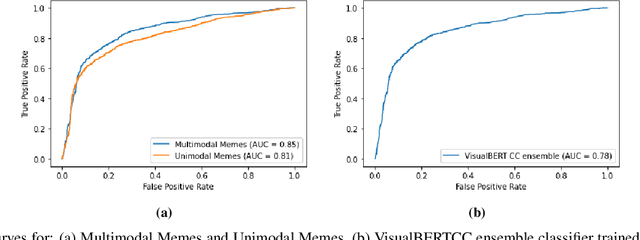
Internet memes have become a dominant method of communication; at the same time, however, they are also increasingly being used to advocate extremism and foster derogatory beliefs. Nonetheless, we do not have a firm understanding as to which perceptual aspects of memes cause this phenomenon. In this work, we assess the efficacy of current state-of-the-art multimodal machine learning models toward hateful meme detection, and in particular with respect to their generalizability across platforms. We use two benchmark datasets comprising 12,140 and 10,567 images from 4chan's "Politically Incorrect" board (/pol/) and Facebook's Hateful Memes Challenge dataset to train the competition's top-ranking machine learning models for the discovery of the most prominent features that distinguish viral hateful memes from benign ones. We conduct three experiments to determine the importance of multimodality on classification performance, the influential capacity of fringe Web communities on mainstream social platforms and vice versa, and the models' learning transferability on 4chan memes. Our experiments show that memes' image characteristics provide a greater wealth of information than its textual content. We also find that current systems developed for online detection of hate speech in memes necessitate further concentration on its visual elements to improve their interpretation of underlying cultural connotations, implying that multimodal models fail to adequately grasp the intricacies of hate speech in memes and generalize across social media platforms.
Slapping Cats, Bopping Heads, and Oreo Shakes: Understanding Indicators of Virality in TikTok Short Videos
Nov 03, 2021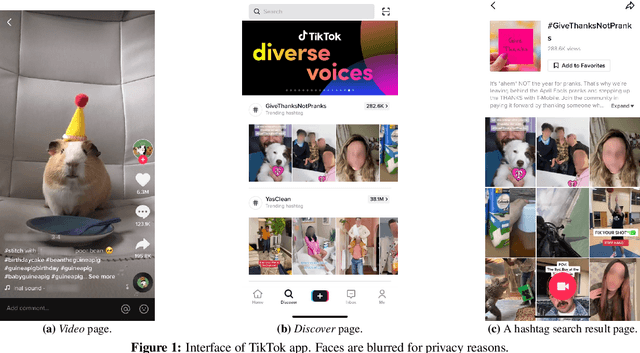
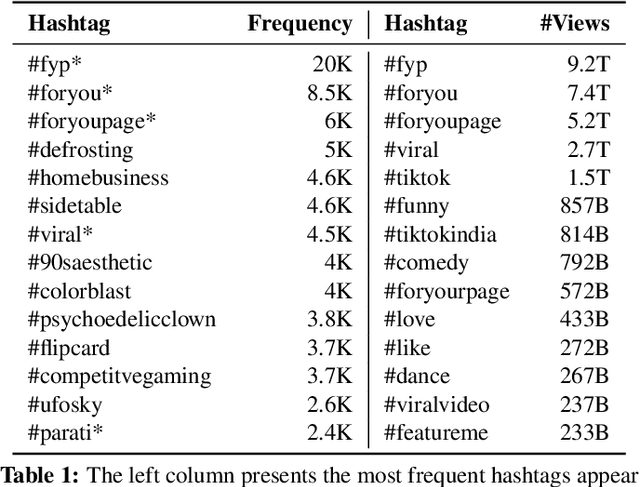
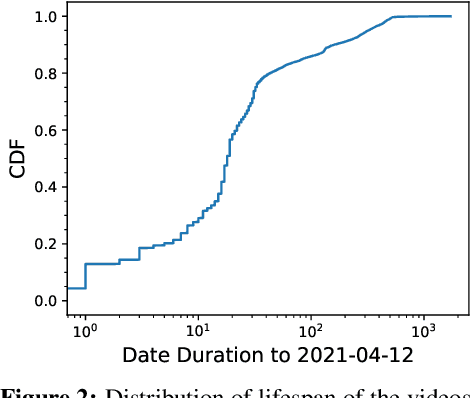
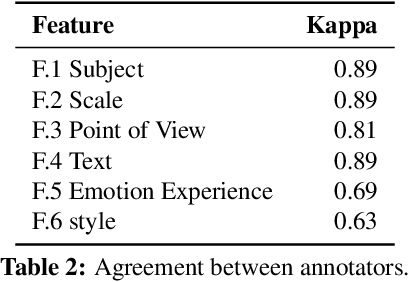
Short videos have become one of the leading media used by younger generations to express themselves online and thus a driving force in shaping online culture. In this context, TikTok has emerged as a platform where viral videos are often posted first. In this paper, we study what elements of short videos posted on TikTok contribute to their virality. We apply a mixed-method approach to develop a codebook and identify important virality features. We do so vis-\`a-vis three research hypotheses; namely, that: 1) the video content, 2) TikTok's recommendation algorithm, and 3) the popularity of the video creator contribute to virality. We collect and label a dataset of 400 TikTok videos and train classifiers to help us identify the features that influence virality the most. While the number of followers is the most powerful predictor, close-up and medium-shot scales also play an essential role. So does the lifespan of the video, the presence of text, and the point of view. Our research highlights the characteristics that distinguish viral from non-viral TikTok videos, laying the groundwork for developing additional approaches to create more engaging online content and proactively identify possibly risky content that is likely to reach a large audience.
A Unified Deep Learning Architecture for Abuse Detection
Feb 21, 2018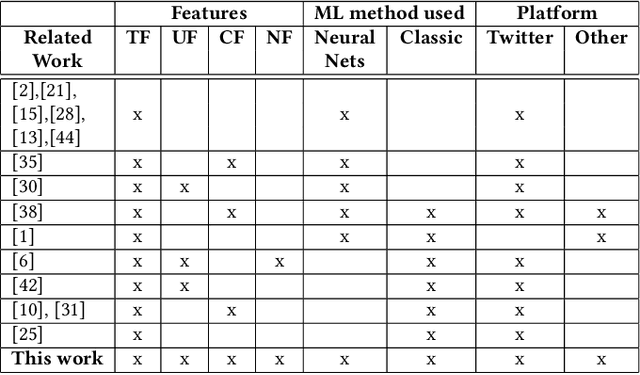
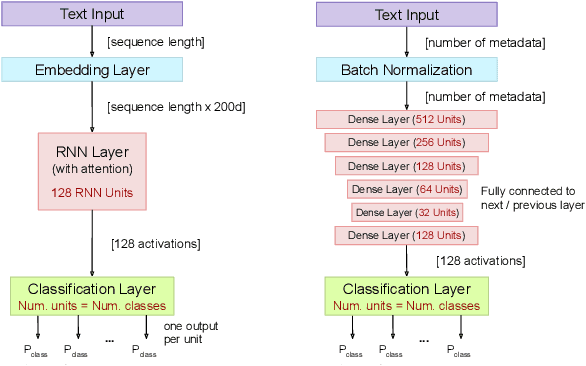
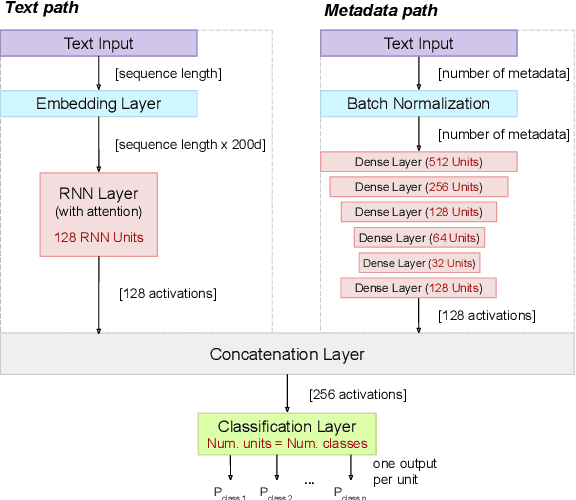
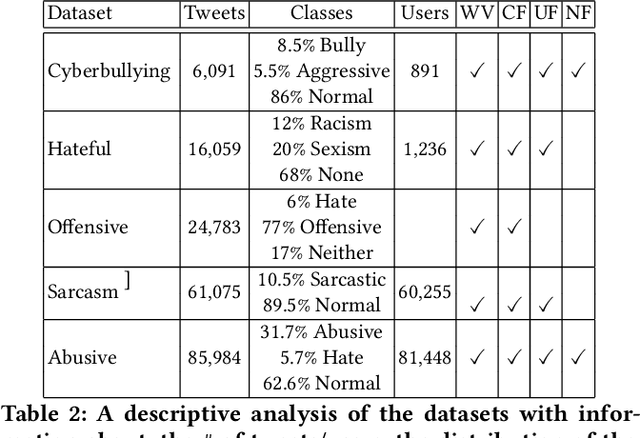
Hate speech, offensive language, sexism, racism and other types of abusive behavior have become a common phenomenon in many online social media platforms. In recent years, such diverse abusive behaviors have been manifesting with increased frequency and levels of intensity. This is due to the openness and willingness of popular media platforms, such as Twitter and Facebook, to host content of sensitive or controversial topics. However, these platforms have not adequately addressed the problem of online abusive behavior, and their responsiveness to the effective detection and blocking of such inappropriate behavior remains limited. In the present paper, we study this complex problem by following a more holistic approach, which considers the various aspects of abusive behavior. To make the approach tangible, we focus on Twitter data and analyze user and textual properties from different angles of abusive posting behavior. We propose a deep learning architecture, which utilizes a wide variety of available metadata, and combines it with automatically-extracted hidden patterns within the text of the tweets, to detect multiple abusive behavioral norms which are highly inter-related. We apply this unified architecture in a seamless, transparent fashion to detect different types of abusive behavior (hate speech, sexism vs. racism, bullying, sarcasm, etc.) without the need for any tuning of the model architecture for each task. We test the proposed approach with multiple datasets addressing different and multiple abusive behaviors on Twitter. Our results demonstrate that it largely outperforms the state-of-art methods (between 21 and 45\% improvement in AUC, depending on the dataset).
Measuring #GamerGate: A Tale of Hate, Sexism, and Bullying
Feb 24, 2017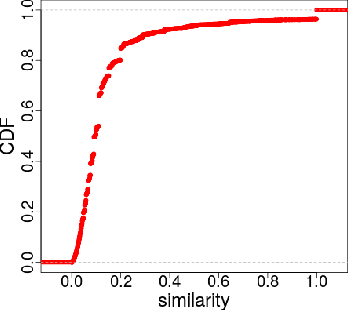

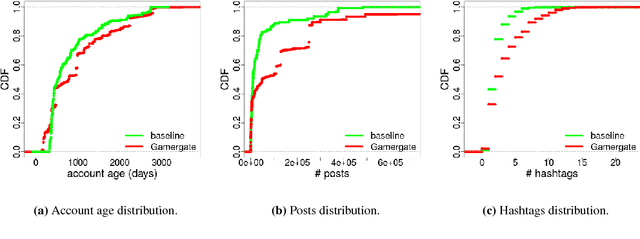
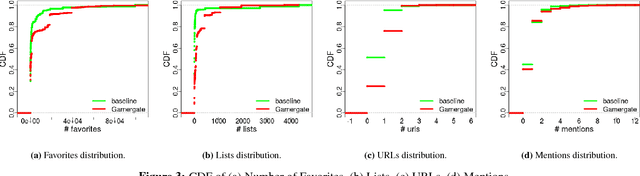
Over the past few years, online aggression and abusive behaviors have occurred in many different forms and on a variety of platforms. In extreme cases, these incidents have evolved into hate, discrimination, and bullying, and even materialized into real-world threats and attacks against individuals or groups. In this paper, we study the Gamergate controversy. Started in August 2014 in the online gaming world, it quickly spread across various social networking platforms, ultimately leading to many incidents of cyberbullying and cyberaggression. We focus on Twitter, presenting a measurement study of a dataset of 340k unique users and 1.6M tweets to study the properties of these users, the content they post, and how they differ from random Twitter users. We find that users involved in this "Twitter war" tend to have more friends and followers, are generally more engaged and post tweets with negative sentiment, less joy, and more hate than random users. We also perform preliminary measurements on how the Twitter suspension mechanism deals with such abusive behaviors. While we focus on Gamergate, our methodology to collect and analyze tweets related to aggressive and bullying activities is of independent interest.