 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Modeling Hierarchical Time Series Using Autoregressive Transformer and Conditional Normalizing Flow based Reconciliation
Dec 28, 2022
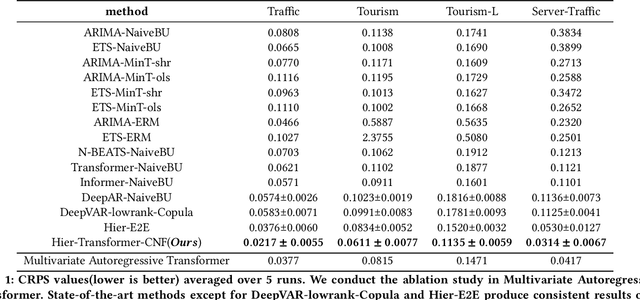
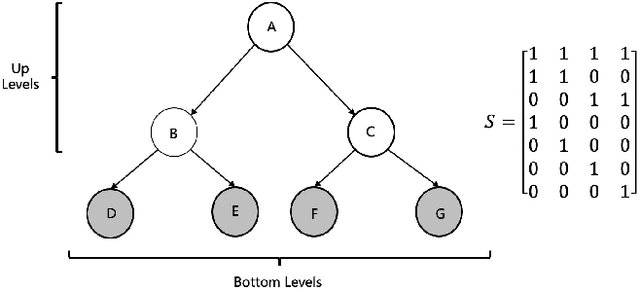
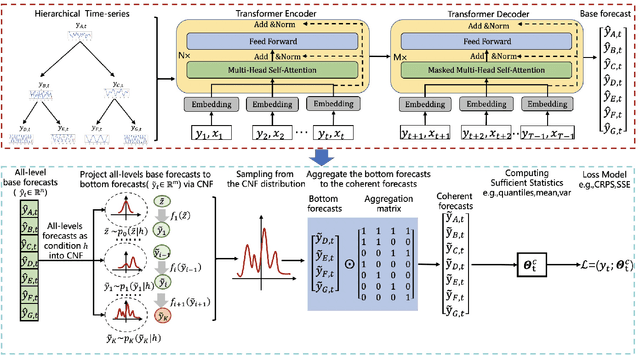
Multivariate time series forecasting with hierarchical structure is pervasive in real-world applications, demanding not only predicting each level of the hierarchy, but also reconciling all forecasts to ensure coherency, i.e., the forecasts should satisfy the hierarchical aggregation constraints. Moreover, the disparities of statistical characteristics between levels can be huge, worsened by non-Gaussian distributions and non-linear correlations. To this extent, we propose a novel end-to-end hierarchical time series forecasting model, based on conditioned normalizing flow-based autoregressive transformer reconciliation, to represent complex data distribution while simultaneously reconciling the forecasts to ensure coherency. Unlike other state-of-the-art methods, we achieve the forecasting and reconciliation simultaneously without requiring any explicit post-processing step. In addition, by harnessing the power of deep model, we do not rely on any assumption such as unbiased estimates or Gaussian distribution. Our evaluation experiments are conducted on four real-world hierarchical datasets from different industrial domains (three public ones and a dataset from the application servers of Alipay's data center) and the preliminary results demonstrate efficacy of our proposed method.
Velocity Obstacle for Polytopic Collision Avoidance for Distributed Multi-robot Systems
Apr 17, 2023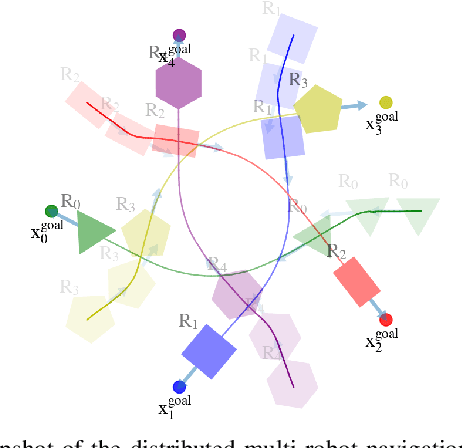
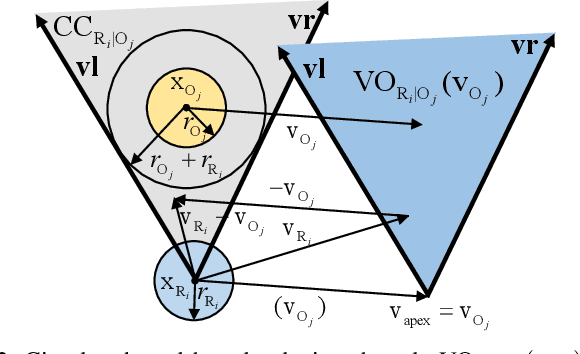
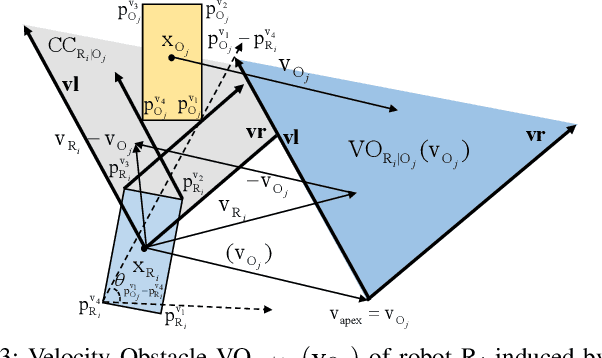
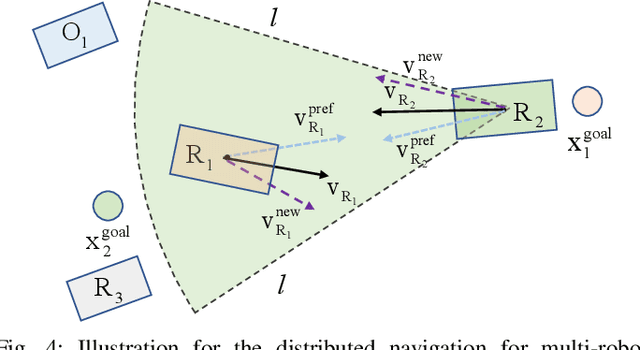
Obstacle avoidance for multi-robot navigation with polytopic shapes is challenging. Existing works simplify the system dynamics or consider it as a convex or non-convex optimization problem with positive distance constraints between robots, which limits real-time performance and scalability. Additionally, generating collision-free behavior for polytopic-shaped robots is harder due to implicit and non-differentiable distance functions between polytopes. In this paper, we extend the concept of velocity obstacle (VO) principle for polytopic-shaped robots and propose a novel approach to construct the VO in the function of vertex coordinates and other robot's states. Compared with existing work about obstacle avoidance between polytopic-shaped robots, our approach is much more computationally efficient as the proposed approach for construction of VO between polytopes is optimization-free. Based on VO representation for polytopic shapes, we later propose a navigation approach for distributed multi-robot systems. We validate our proposed VO representation and navigation approach in multiple challenging scenarios including large-scale randomized tests, and our approach outperforms the state of art in many evaluation metrics, including completion rate, deadlock rate, and the average travel distance.
Neural Network Algorithm for Intercepting Targets Moving Along Known Trajectories by a Dubins' Car
Apr 12, 2023The task of intercepting a target moving along a rectilinear or circular trajectory by a Dubins' car is formulated as a time-optimal control problem with an arbitrary direction of the car's velocity at the interception moment. To solve this problem and to synthesize interception trajectories, neural network methods of unsupervised learning based on the Deep Deterministic Policy Gradient algorithm are used. The analysis of the obtained control laws and interception trajectories in comparison with the analytical solutions of the interception problem is performed. The mathematical modeling for the parameters of the target movement that the neural network had not seen before during training is carried out. Model experiments are conducted to test the stability of the neural solution. The effectiveness of using neural network methods for the synthesis of interception trajectories for given classes of target movements is shown.
3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes
Apr 22, 2023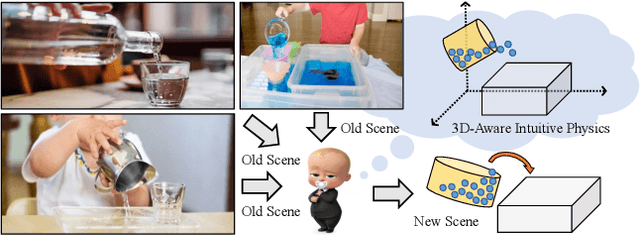
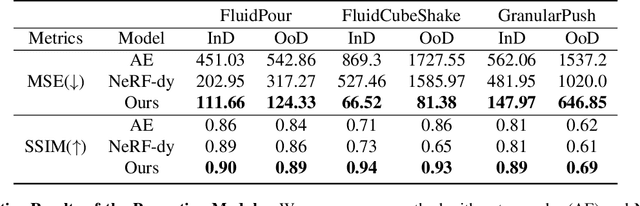
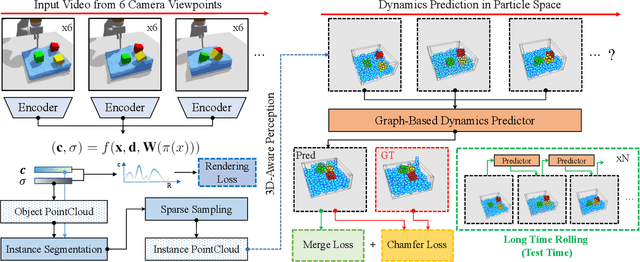
Given a visual scene, humans have strong intuitions about how a scene can evolve over time under given actions. The intuition, often termed visual intuitive physics, is a critical ability that allows us to make effective plans to manipulate the scene to achieve desired outcomes without relying on extensive trial and error. In this paper, we present a framework capable of learning 3D-grounded visual intuitive physics models from videos of complex scenes with fluids. Our method is composed of a conditional Neural Radiance Field (NeRF)-style visual frontend and a 3D point-based dynamics prediction backend, using which we can impose strong relational and structural inductive bias to capture the structure of the underlying environment. Unlike existing intuitive point-based dynamics works that rely on the supervision of dense point trajectory from simulators, we relax the requirements and only assume access to multi-view RGB images and (imperfect) instance masks acquired using color prior. This enables the proposed model to handle scenarios where accurate point estimation and tracking are hard or impossible. We generate datasets including three challenging scenarios involving fluid, granular materials, and rigid objects in the simulation. The datasets do not include any dense particle information so most previous 3D-based intuitive physics pipelines can barely deal with that. We show our model can make long-horizon future predictions by learning from raw images and significantly outperforms models that do not employ an explicit 3D representation space. We also show that once trained, our model can achieve strong generalization in complex scenarios under extrapolate settings.
ESPnet-ST-v2: Multipurpose Spoken Language Translation Toolkit
Apr 11, 2023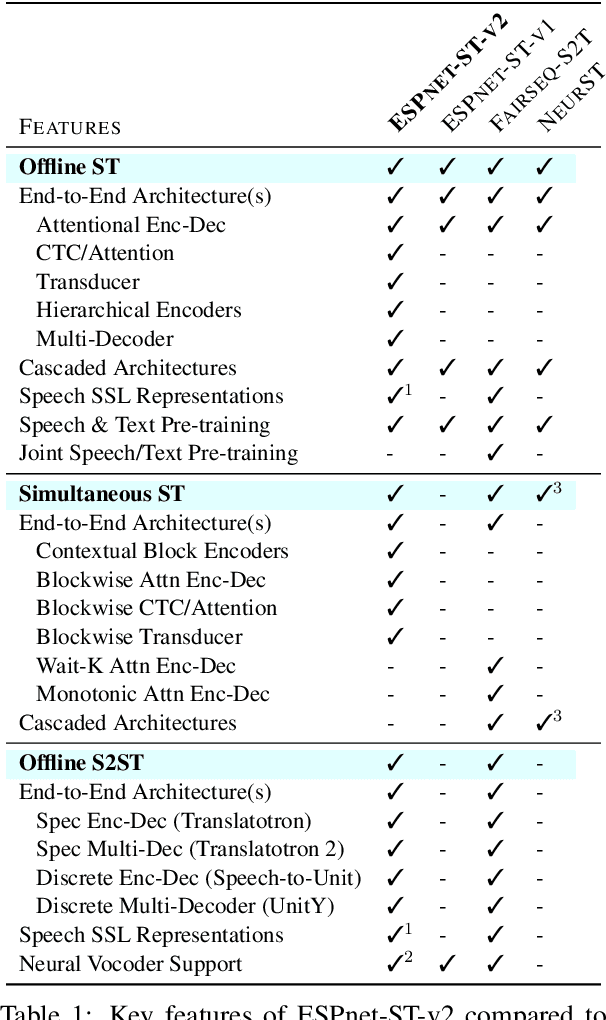

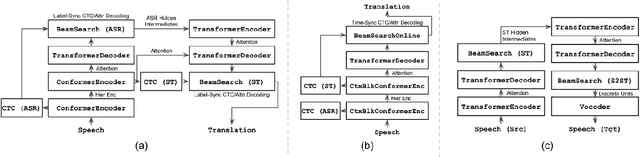
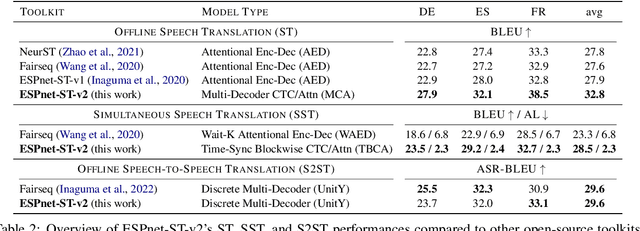
ESPnet-ST-v2 is a revamp of the open-source ESPnet-ST toolkit necessitated by the broadening interests of the spoken language translation community. ESPnet-ST-v2 supports 1) offline speech-to-text translation (ST), 2) simultaneous speech-to-text translation (SST), and 3) offline speech-to-speech translation (S2ST) -- each task is supported with a wide variety of approaches, differentiating ESPnet-ST-v2 from other open source spoken language translation toolkits. This toolkit offers state-of-the-art architectures such as transducers, hybrid CTC/attention, multi-decoders with searchable intermediates, time-synchronous blockwise CTC/attention, Translatotron models, and direct discrete unit models. In this paper, we describe the overall design, example models for each task, and performance benchmarking behind ESPnet-ST-v2, which is publicly available at https://github.com/espnet/espnet.
Divided Attention: Unsupervised Multi-Object Discovery with Contextually Separated Slots
Apr 04, 2023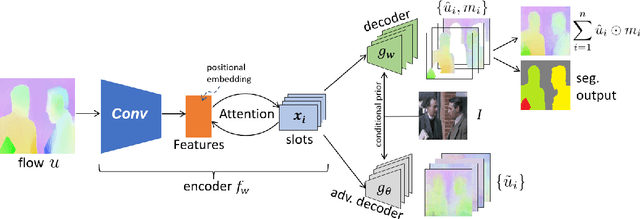
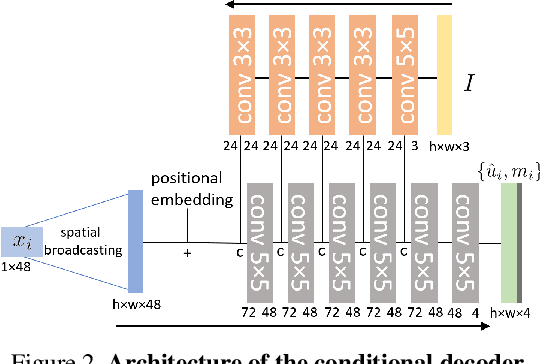
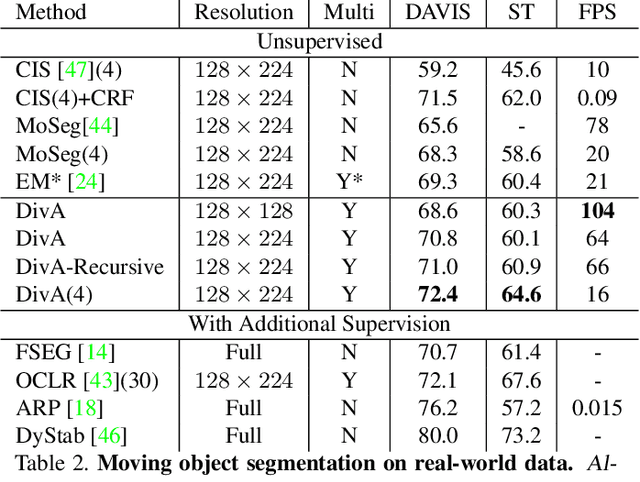

We introduce a method to segment the visual field into independently moving regions, trained with no ground truth or supervision. It consists of an adversarial conditional encoder-decoder architecture based on Slot Attention, modified to use the image as context to decode optical flow without attempting to reconstruct the image itself. In the resulting multi-modal representation, one modality (flow) feeds the encoder to produce separate latent codes (slots), whereas the other modality (image) conditions the decoder to generate the first (flow) from the slots. This design frees the representation from having to encode complex nuisance variability in the image due to, for instance, illumination and reflectance properties of the scene. Since customary autoencoding based on minimizing the reconstruction error does not preclude the entire flow from being encoded into a single slot, we modify the loss to an adversarial criterion based on Contextual Information Separation. The resulting min-max optimization fosters the separation of objects and their assignment to different attention slots, leading to Divided Attention, or DivA. DivA outperforms recent unsupervised multi-object motion segmentation methods while tripling run-time speed up to 104FPS and reducing the performance gap from supervised methods to 12% or less. DivA can handle different numbers of objects and different image sizes at training and test time, is invariant to permutation of object labels, and does not require explicit regularization.
Silent Abandonment in Contact Centers: Estimating Customer Patience from Uncertain Data
Apr 23, 2023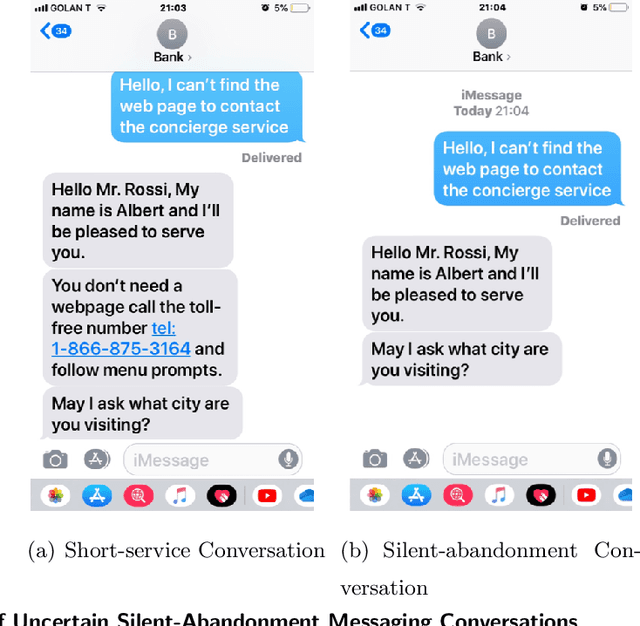
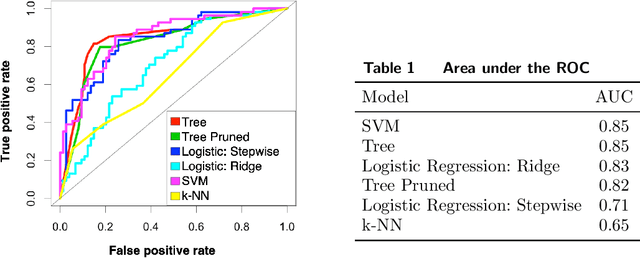

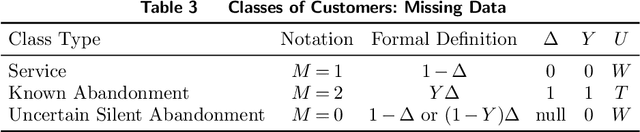
In the quest to improve services, companies offer customers the opportunity to interact with agents through contact centers, where the communication is mainly text-based. This has become one of the favorite channels of communication with companies in recent years. However, contact centers face operational challenges, since the measurement of common proxies for customer experience, such as knowledge of whether customers have abandoned the queue and their willingness to wait for service (patience), are subject to information uncertainty. We focus this research on the impact of a main source of such uncertainty: silent abandonment by customers. These customers leave the system while waiting for a reply to their inquiry, but give no indication of doing so, such as closing the mobile app of the interaction. As a result, the system is unaware that they have left and waste agent time and capacity until this fact is realized. In this paper, we show that 30%-67% of the abandoning customers abandon the system silently, and that such customer behavior reduces system efficiency by 5%-15%. To do so, we develop methodologies to identify silent-abandonment customers in two types of contact centers: chat and messaging systems. We first use text analysis and an SVM model to estimate the actual abandonment level. We then use a parametric estimator and develop an expectation-maximization algorithm to estimate customer patience accurately, as customer patience is an important parameter for fitting queueing models to the data. We show how accounting for silent abandonment in a queueing model improves dramatically the estimation accuracy of key measures of performance. Finally, we suggest strategies to operationally cope with the phenomenon of silent abandonment.
Real-Time Deformable-Contact-Aware Model Predictive Control for Force-Modulated Manipulation
Dec 19, 2022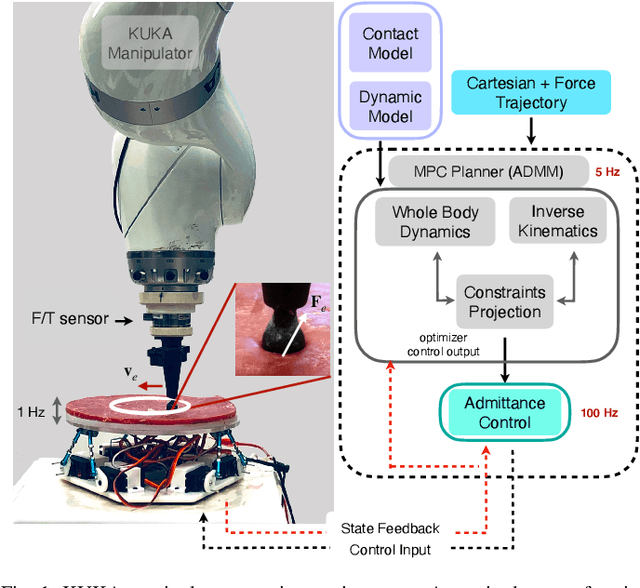
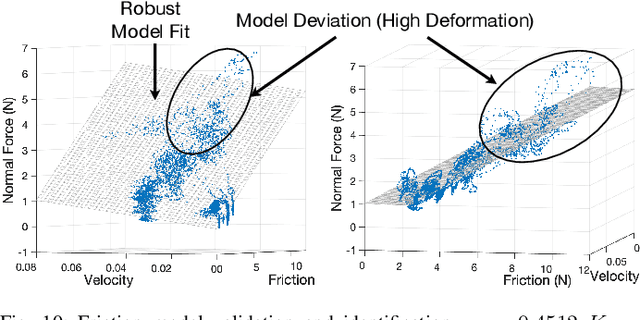
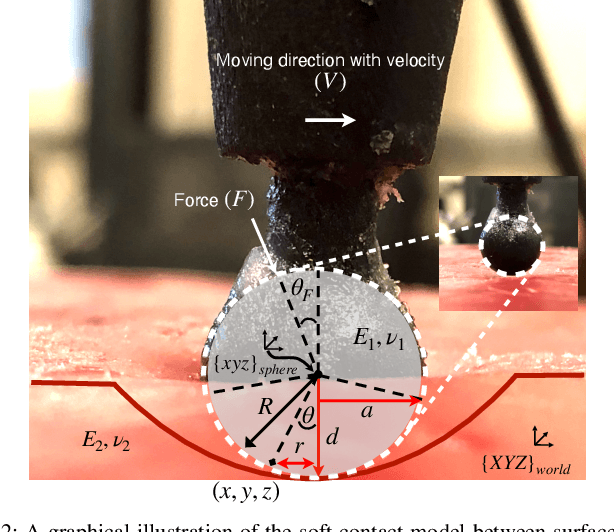
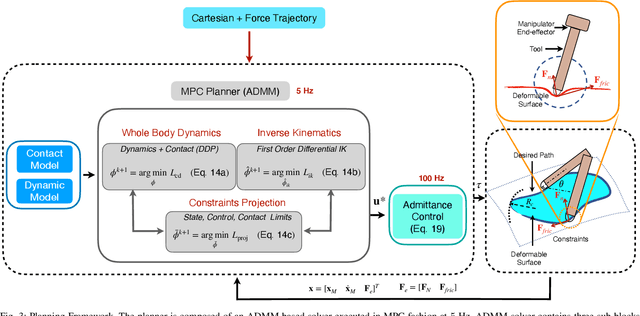
Force modulation of robotic manipulators has been extensively studied for several decades. However, it is not yet commonly used in safety-critical applications due to a lack of accurate interaction contact modeling and weak performance guarantees - a large proportion of them concerning the modulation of interaction forces. This study presents a high-level framework for simultaneous trajectory optimization and force control of the interaction between a manipulator and soft environments, which is prone to external disturbances. Sliding friction and normal contact force are taken into account. The dynamics of the soft contact model and the manipulator are simultaneously incorporated in a trajectory optimizer to generate desired motion and force profiles. A constrained optimization framework based on Alternative Direction Method of Multipliers (ADMM) has been employed to efficiently generate real-time optimal control inputs and high-dimensional state trajectories in a Model Predictive Control fashion. Experimental validation of the model performance is conducted on a soft substrate with known material properties using a Cartesian space force control mode. Results show a comparison of ground truth and real-time model-based contact force and motion tracking for multiple Cartesian motions in the valid range of the friction model. It is shown that a contact model-based motion planner can compensate for frictional forces and motion disturbances and improve the overall motion and force tracking accuracy. The proposed high-level planner has the potential to facilitate the automation of medical tasks involving the manipulation of compliant, delicate, and deformable tissues.
Unleashing the Potential of Spiking Neural Networks by Dynamic Confidence
Mar 26, 2023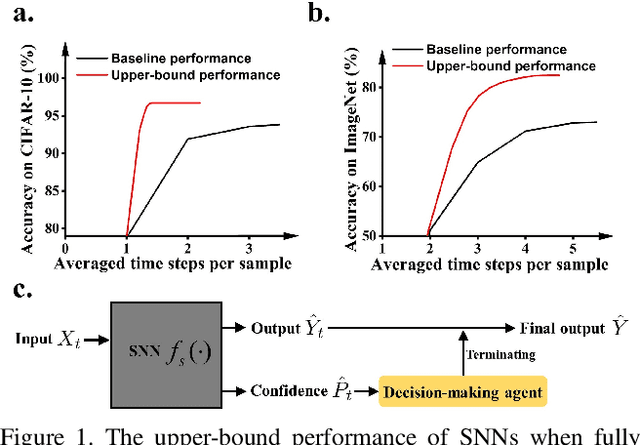
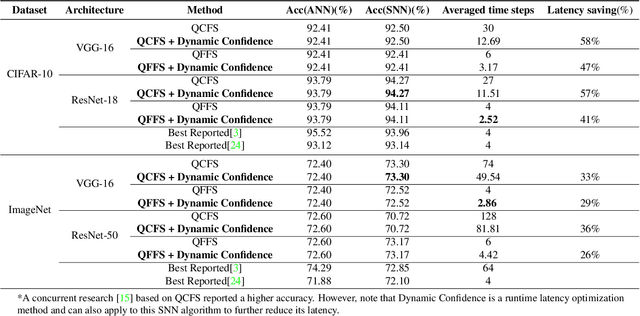
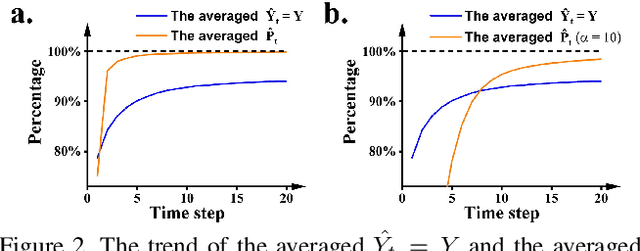
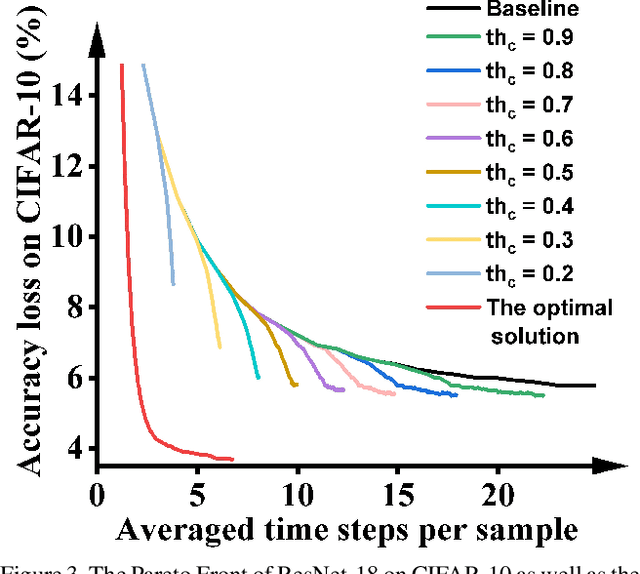
This paper presents a new methodology to alleviate the fundamental trade-off between accuracy and latency in spiking neural networks (SNNs). The approach involves decoding confidence information over time from the SNN outputs and using it to develop a decision-making agent that can dynamically determine when to terminate each inference. The proposed method, Dynamic Confidence, provides several significant benefits to SNNs. 1. It can effectively optimize latency dynamically at runtime, setting it apart from many existing low-latency SNN algorithms. Our experiments on CIFAR-10 and ImageNet datasets have demonstrated an average 40% speedup across eight different settings after applying Dynamic Confidence. 2. The decision-making agent in Dynamic Confidence is straightforward to construct and highly robust in parameter space, making it extremely easy to implement. 3. The proposed method enables visualizing the potential of any given SNN, which sets a target for current SNNs to approach. For instance, if an SNN can terminate at the most appropriate time point for each input sample, a ResNet-50 SNN can achieve an accuracy as high as 82.47% on ImageNet within just 4.71 time steps on average. Unlocking the potential of SNNs needs a highly-reliable decision-making agent to be constructed and fed with a high-quality estimation of ground truth. In this regard, Dynamic Confidence represents a meaningful step toward realizing the potential of SNNs.
Progressive Channel-Shrinking Network
Apr 01, 2023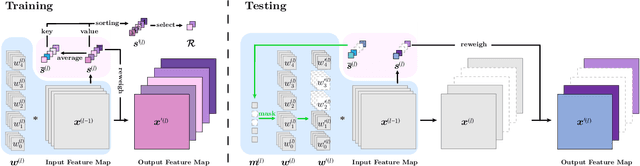
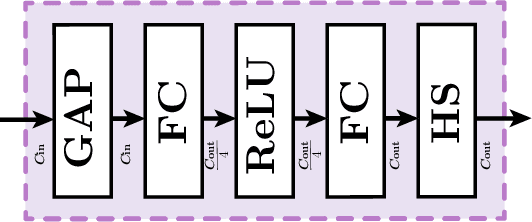
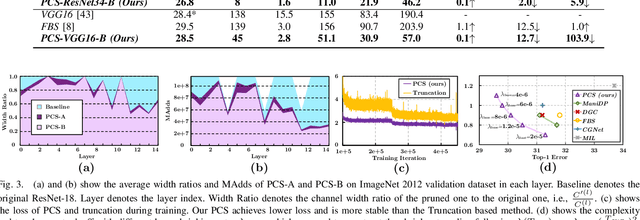
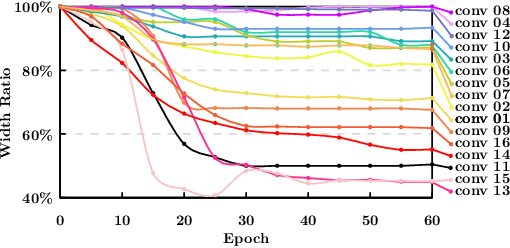
Currently, salience-based channel pruning makes continuous breakthroughs in network compression. In the realization, the salience mechanism is used as a metric of channel salience to guide pruning. Therefore, salience-based channel pruning can dynamically adjust the channel width at run-time, which provides a flexible pruning scheme. However, there are two problems emerging: a gating function is often needed to truncate the specific salience entries to zero, which destabilizes the forward propagation; dynamic architecture brings more cost for indexing in inference which bottlenecks the inference speed. In this paper, we propose a Progressive Channel-Shrinking (PCS) method to compress the selected salience entries at run-time instead of roughly approximating them to zero. We also propose a Running Shrinking Policy to provide a testing-static pruning scheme that can reduce the memory access cost for filter indexing. We evaluate our method on ImageNet and CIFAR10 datasets over two prevalent networks: ResNet and VGG, and demonstrate that our PCS outperforms all baselines and achieves state-of-the-art in terms of compression-performance tradeoff. Moreover, we observe a significant and practical acceleration of inference.