 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023



TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.
ESPnet-ST-v2: Multipurpose Spoken Language Translation Toolkit
Apr 11, 2023



ESPnet-ST-v2 is a revamp of the open-source ESPnet-ST toolkit necessitated by the broadening interests of the spoken language translation community. ESPnet-ST-v2 supports 1) offline speech-to-text translation (ST), 2) simultaneous speech-to-text translation (SST), and 3) offline speech-to-speech translation (S2ST) -- each task is supported with a wide variety of approaches, differentiating ESPnet-ST-v2 from other open source spoken language translation toolkits. This toolkit offers state-of-the-art architectures such as transducers, hybrid CTC/attention, multi-decoders with searchable intermediates, time-synchronous blockwise CTC/attention, Translatotron models, and direct discrete unit models. In this paper, we describe the overall design, example models for each task, and performance benchmarking behind ESPnet-ST-v2, which is publicly available at https://github.com/espnet/espnet.
TorchAudio: Building Blocks for Audio and Speech Processing
Oct 28, 2021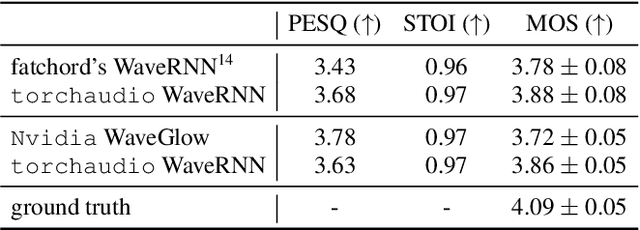
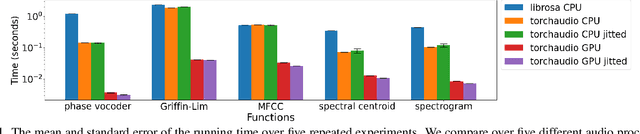


This document describes version 0.10 of torchaudio: building blocks for machine learning applications in the audio and speech processing domain. The objective of torchaudio is to accelerate the development and deployment of machine learning applications for researchers and engineers by providing off-the-shelf building blocks. The building blocks are designed to be GPU-compatible, automatically differentiable, and production-ready. torchaudio can be easily installed from Python Package Index repository and the source code is publicly available under a BSD-2-Clause License (as of September 2021) at https://github.com/pytorch/audio. In this document, we provide an overview of the design principles, functionalities, and benchmarks of torchaudio. We also benchmark our implementation of several audio and speech operations and models. We verify through the benchmarks that our implementations of various operations and models are valid and perform similarly to other publicly available implementations.