 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriangular Consistency as a Universal Constraint for Learning Optical Flow
Jun 18, 2026We propose triangular consistency as a first-principled constraint for optical flow, which is agnostic to network architecture, supervision type, and dataset, and applies to both image-pair and multi-frame settings. This simple but powerful constraint is to compose two flows to induce a third flow and enforce consistency among the three. The composed flows may arise from (i) image pairs, yielding cycle consistency; (ii) multiple video frames, producing longer-range motion through temporal chaining; or (iii) image pairs combined with controlled synthetic transformations, which becomes data augmentation. This triangular consistency introduces negligible computational overhead and requires no additional annotations. Since it is derived directly from the geometry of optical flow, it does not rely on model-specific assumptions and serves as a ``universal'' plug-and-play component for optical flow training. Experiments show consistent improvement across supervised, unsupervised, and transfer learning settings.
Naïve PAINE: Lightweight Text-to-Image Generation Improvement with Prompt Evaluation
Mar 12, 2026Text-to-Image (T2I) generation is primarily driven by Diffusion Models (DM) which rely on random Gaussian noise. Thus, like playing the slots at a casino, a DM will produce different results given the same user-defined inputs. This imposes a gambler's burden: To perform multiple generation cycles to obtain a satisfactory result. However, even though DMs use stochastic sampling to seed generation, the distribution of generated content quality highly depends on the prompt and the generative ability of a DM with respect to it. To account for this, we propose Naïve PAINE for improving the generative quality of Diffusion Models by leveraging T2I preference benchmarks. We directly predict the numerical quality of an image from the initial noise and given prompt. Naïve PAINE then selects a handful of quality noises and forwards them to the DM for generation. Further, Naïve PAINE provides feedback on the DM generative quality given the prompt and is lightweight enough to seamlessly fit into existing DM pipelines. Experimental results demonstrate that Naïve PAINE outperforms existing approaches on several prompt corpus benchmarks.
RSA: Resolving Scale Ambiguities in Monocular Depth Estimators through Language Descriptions
Oct 03, 2024



We propose a method for metric-scale monocular depth estimation. Inferring depth from a single image is an ill-posed problem due to the loss of scale from perspective projection during the image formation process. Any scale chosen is a bias, typically stemming from training on a dataset; hence, existing works have instead opted to use relative (normalized, inverse) depth. Our goal is to recover metric-scaled depth maps through a linear transformation. The crux of our method lies in the observation that certain objects (e.g., cars, trees, street signs) are typically found or associated with certain types of scenes (e.g., outdoor). We explore whether language descriptions can be used to transform relative depth predictions to those in metric scale. Our method, RSA, takes as input a text caption describing objects present in an image and outputs the parameters of a linear transformation which can be applied globally to a relative depth map to yield metric-scaled depth predictions. We demonstrate our method on recent general-purpose monocular depth models on indoors (NYUv2) and outdoors (KITTI). When trained on multiple datasets, RSA can serve as a general alignment module in zero-shot settings. Our method improves over common practices in aligning relative to metric depth and results in predictions that are comparable to an upper bound of fitting relative depth to ground truth via a linear transformation.
Diffeomorphic Template Registration for Atmospheric Turbulence Mitigation
May 06, 2024



We describe a method for recovering the irradiance underlying a collection of images corrupted by atmospheric turbulence. Since supervised data is often technically impossible to obtain, assumptions and biases have to be imposed to solve this inverse problem, and we choose to model them explicitly. Rather than initializing a latent irradiance ("template") by heuristics to estimate deformation, we select one of the images as a reference, and model the deformation in this image by the aggregation of the optical flow from it to other images, exploiting a prior imposed by Central Limit Theorem. Then with a novel flow inversion module, the model registers each image TO the template but WITHOUT the template, avoiding artifacts related to poor template initialization. To illustrate the robustness of the method, we simply (i) select the first frame as the reference and (ii) use the simplest optical flow to estimate the warpings, yet the improvement in registration is decisive in the final reconstruction, as we achieve state-of-the-art performance despite its simplicity. The method establishes a strong baseline that can be further improved by integrating it seamlessly into more sophisticated pipelines, or with domain-specific methods if so desired.
WorDepth: Variational Language Prior for Monocular Depth Estimation
Apr 05, 2024



Three-dimensional (3D) reconstruction from a single image is an ill-posed problem with inherent ambiguities, i.e. scale. Predicting a 3D scene from text description(s) is similarly ill-posed, i.e. spatial arrangements of objects described. We investigate the question of whether two inherently ambiguous modalities can be used in conjunction to produce metric-scaled reconstructions. To test this, we focus on monocular depth estimation, the problem of predicting a dense depth map from a single image, but with an additional text caption describing the scene. To this end, we begin by encoding the text caption as a mean and standard deviation; using a variational framework, we learn the distribution of the plausible metric reconstructions of 3D scenes corresponding to the text captions as a prior. To "select" a specific reconstruction or depth map, we encode the given image through a conditional sampler that samples from the latent space of the variational text encoder, which is then decoded to the output depth map. Our approach is trained alternatingly between the text and image branches: in one optimization step, we predict the mean and standard deviation from the text description and sample from a standard Gaussian, and in the other, we sample using a (image) conditional sampler. Once trained, we directly predict depth from the encoded text using the conditional sampler. We demonstrate our approach on indoor (NYUv2) and outdoor (KITTI) scenarios, where we show that language can consistently improve performance in both.
AugUndo: Scaling Up Augmentations for Unsupervised Depth Completion
Oct 15, 2023Unsupervised depth completion methods are trained by minimizing sparse depth and image reconstruction error. Block artifacts from resampling, intensity saturation, and occlusions are amongst the many undesirable by-products of common data augmentation schemes that affect image reconstruction quality, and thus the training signal. Hence, typical augmentations on images that are viewed as essential to training pipelines in other vision tasks have seen limited use beyond small image intensity changes and flipping. The sparse depth modality have seen even less as intensity transformations alter the scale of the 3D scene, and geometric transformations may decimate the sparse points during resampling. We propose a method that unlocks a wide range of previously-infeasible geometric augmentations for unsupervised depth completion. This is achieved by reversing, or "undo"-ing, geometric transformations to the coordinates of the output depth, warping the depth map back to the original reference frame. This enables computing the reconstruction losses using the original images and sparse depth maps, eliminating the pitfalls of naive loss computation on the augmented inputs. This simple yet effective strategy allows us to scale up augmentations to boost performance. We demonstrate our method on indoor (VOID) and outdoor (KITTI) datasets where we improve upon three existing methods by an average of 10.4\% across both datasets.
Sub-token ViT Embedding via Stochastic Resonance Transformers
Oct 06, 2023



We discover the presence of quantization artifacts in Vision Transformers (ViTs), which arise due to the image tokenization step inherent in these architectures. These artifacts result in coarsely quantized features, which negatively impact performance, especially on downstream dense prediction tasks. We present a zero-shot method to improve how pre-trained ViTs handle spatial quantization. In particular, we propose to ensemble the features obtained from perturbing input images via sub-token spatial translations, inspired by Stochastic Resonance, a method traditionally applied to climate dynamics and signal processing. We term our method ``Stochastic Resonance Transformer" (SRT), which we show can effectively super-resolve features of pre-trained ViTs, capturing more of the local fine-grained structures that might otherwise be neglected as a result of tokenization. SRT can be applied at any layer, on any task, and does not require any fine-tuning. The advantage of the former is evident when applied to monocular depth prediction, where we show that ensembling model outputs are detrimental while applying SRT on intermediate ViT features outperforms the baseline models by an average of 4.7% and 14.9% on the RMSE and RMSE-log metrics across three different architectures. When applied to semi-supervised video object segmentation, SRT also improves over the baseline models uniformly across all metrics, and by an average of 2.4% in F&J score. We further show that these quantization artifacts can be attenuated to some extent via self-distillation. On the unsupervised salient region segmentation, SRT improves upon the base model by an average of 2.1% on the maxF metric. Finally, despite operating purely on pixel-level features, SRT generalizes to non-dense prediction tasks such as image retrieval and object discovery, yielding consistent improvements of up to 2.6% and 1.0% respectively.
Divided Attention: Unsupervised Multi-Object Discovery with Contextually Separated Slots
Apr 04, 2023



We introduce a method to segment the visual field into independently moving regions, trained with no ground truth or supervision. It consists of an adversarial conditional encoder-decoder architecture based on Slot Attention, modified to use the image as context to decode optical flow without attempting to reconstruct the image itself. In the resulting multi-modal representation, one modality (flow) feeds the encoder to produce separate latent codes (slots), whereas the other modality (image) conditions the decoder to generate the first (flow) from the slots. This design frees the representation from having to encode complex nuisance variability in the image due to, for instance, illumination and reflectance properties of the scene. Since customary autoencoding based on minimizing the reconstruction error does not preclude the entire flow from being encoded into a single slot, we modify the loss to an adversarial criterion based on Contextual Information Separation. The resulting min-max optimization fosters the separation of objects and their assignment to different attention slots, leading to Divided Attention, or DivA. DivA outperforms recent unsupervised multi-object motion segmentation methods while tripling run-time speed up to 104FPS and reducing the performance gap from supervised methods to 12% or less. DivA can handle different numbers of objects and different image sizes at training and test time, is invariant to permutation of object labels, and does not require explicit regularization.
Does Monocular Depth Estimation Provide Better Pre-training than Classification for Semantic Segmentation?
Mar 29, 2022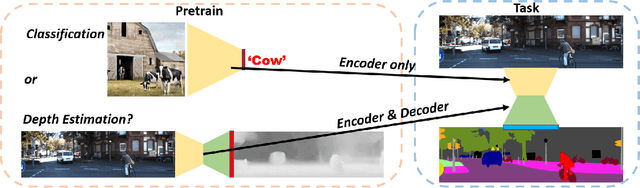
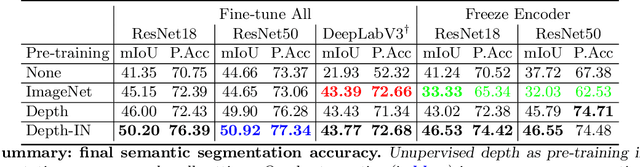

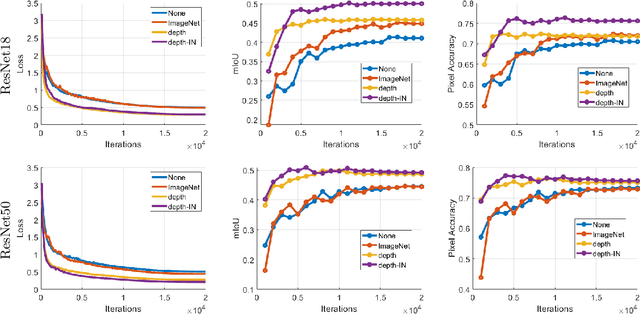
Training a deep neural network for semantic segmentation is labor-intensive, so it is common to pre-train it for a different task, and then fine-tune it with a small annotated dataset. State-of-the-art methods use image classification for pre-training, which introduces uncontrolled biases. We test the hypothesis that depth estimation from unlabeled videos may provide better pre-training. Despite the absence of any semantic information, we argue that estimating scene geometry is closer to the task of semantic segmentation than classifying whole images into semantic classes. Since analytical validation is intractable, we test the hypothesis empirically by introducing a pre-training scheme that yields an improvement of 5.7% mIoU and 4.1% pixel accuracy over classification-based pre-training. While annotation is not needed for pre-training, it is needed for testing the hypothesis. We use the KITTI (outdoor) and NYU-V2 (indoor) benchmarks to that end, and provide an extensive discussion of the benefits and limitations of the proposed scheme in relation to existing unsupervised, self-supervised, and semi-supervised pre-training protocols.
Flow-Guided Video Inpainting with Scene Templates
Aug 29, 2021
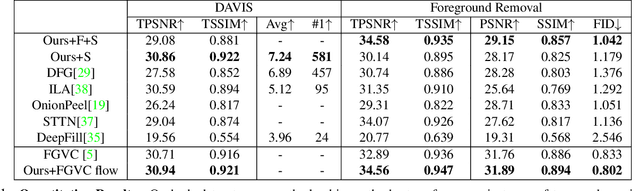
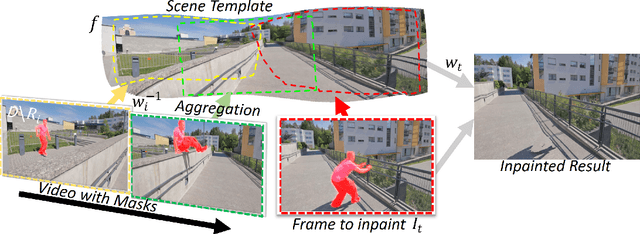

We consider the problem of filling in missing spatio-temporal regions of a video. We provide a novel flow-based solution by introducing a generative model of images in relation to the scene (without missing regions) and mappings from the scene to images. We use the model to jointly infer the scene template, a 2D representation of the scene, and the mappings. This ensures consistency of the frame-to-frame flows generated to the underlying scene, reducing geometric distortions in flow based inpainting. The template is mapped to the missing regions in the video by a new L2-L1 interpolation scheme, creating crisp inpaintings and reducing common blur and distortion artifacts. We show on two benchmark datasets that our approach out-performs state-of-the-art quantitatively and in user studies.