 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting In-Context Learning with Long Context Language Models
Dec 22, 2024



In-Context Learning (ICL) is a technique by which language models make predictions based on examples provided in their input context. Previously, their context window size imposed a limit on the number of examples that can be shown, making example selection techniques crucial for identifying the maximally effective set of examples. However, the recent advent of Long Context Language Models (LCLMs) has significantly increased the number of examples that can be included in context, raising an important question of whether ICL performance in a many-shot regime is still sensitive to the method of sample selection. To answer this, we revisit these approaches in the context of LCLMs through extensive experiments on 18 datasets spanning 4 tasks. Surprisingly, we observe that sophisticated example selection techniques do not yield significant improvements over a simple random sample selection method. Instead, we find that the advent of LCLMs has fundamentally shifted the challenge of ICL from that of selecting the most effective examples to that of collecting sufficient examples to fill the context window. Specifically, in certain datasets, including all available examples does not fully utilize the context window; however, by augmenting the examples in context with a simple data augmentation approach, we substantially improve ICL performance by 5%.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024



Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Transforming LLMs into Cross-modal and Cross-lingual Retrieval Systems
Apr 04, 2024Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
LLM Augmented LLMs: Expanding Capabilities through Composition
Jan 04, 2024



Foundational models with billions of parameters which have been trained on large corpora of data have demonstrated non-trivial skills in a variety of domains. However, due to their monolithic structure, it is challenging and expensive to augment them or impart new skills. On the other hand, due to their adaptation abilities, several new instances of these models are being trained towards new domains and tasks. In this work, we study the problem of efficient and practical composition of existing foundation models with more specific models to enable newer capabilities. To this end, we propose CALM -- Composition to Augment Language Models -- which introduces cross-attention between models to compose their representations and enable new capabilities. Salient features of CALM are: (i) Scales up LLMs on new tasks by 're-using' existing LLMs along with a few additional parameters and data, (ii) Existing model weights are kept intact, and hence preserves existing capabilities, and (iii) Applies to diverse domains and settings. We illustrate that augmenting PaLM2-S with a smaller model trained on low-resource languages results in an absolute improvement of up to 13\% on tasks like translation into English and arithmetic reasoning for low-resource languages. Similarly, when PaLM2-S is augmented with a code-specific model, we see a relative improvement of 40\% over the base model for code generation and explanation tasks -- on-par with fully fine-tuned counterparts.
Multimodal Modeling For Spoken Language Identification
Sep 19, 2023



Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
ESPnet-ST-v2: Multipurpose Spoken Language Translation Toolkit
Apr 11, 2023



ESPnet-ST-v2 is a revamp of the open-source ESPnet-ST toolkit necessitated by the broadening interests of the spoken language translation community. ESPnet-ST-v2 supports 1) offline speech-to-text translation (ST), 2) simultaneous speech-to-text translation (SST), and 3) offline speech-to-speech translation (S2ST) -- each task is supported with a wide variety of approaches, differentiating ESPnet-ST-v2 from other open source spoken language translation toolkits. This toolkit offers state-of-the-art architectures such as transducers, hybrid CTC/attention, multi-decoders with searchable intermediates, time-synchronous blockwise CTC/attention, Translatotron models, and direct discrete unit models. In this paper, we describe the overall design, example models for each task, and performance benchmarking behind ESPnet-ST-v2, which is publicly available at https://github.com/espnet/espnet.
Align, Write, Re-order: Explainable End-to-End Speech Translation via Operation Sequence Generation
Nov 11, 2022



The black-box nature of end-to-end speech translation (E2E ST) systems makes it difficult to understand how source language inputs are being mapped to the target language. To solve this problem, we would like to simultaneously generate automatic speech recognition (ASR) and ST predictions such that each source language word is explicitly mapped to a target language word. A major challenge arises from the fact that translation is a non-monotonic sequence transduction task due to word ordering differences between languages -- this clashes with the monotonic nature of ASR. Therefore, we propose to generate ST tokens out-of-order while remembering how to re-order them later. We achieve this by predicting a sequence of tuples consisting of a source word, the corresponding target words, and post-editing operations dictating the correct insertion points for the target word. We examine two variants of such operation sequences which enable generation of monotonic transcriptions and non-monotonic translations from the same speech input simultaneously. We apply our approach to offline and real-time streaming models, demonstrating that we can provide explainable translations without sacrificing quality or latency. In fact, the delayed re-ordering ability of our approach improves performance during streaming. As an added benefit, our method performs ASR and ST simultaneously, making it faster than using two separate systems to perform these tasks.
A Study on the Integration of Pre-trained SSL, ASR, LM and SLU Models for Spoken Language Understanding
Nov 10, 2022



Collecting sufficient labeled data for spoken language understanding (SLU) is expensive and time-consuming. Recent studies achieved promising results by using pre-trained models in low-resource scenarios. Inspired by this, we aim to ask: which (if any) pre-training strategies can improve performance across SLU benchmarks? To answer this question, we employ four types of pre-trained models and their combinations for SLU. We leverage self-supervised speech and language models (LM) pre-trained on large quantities of unpaired data to extract strong speech and text representations. We also explore using supervised models pre-trained on larger external automatic speech recognition (ASR) or SLU corpora. We conduct extensive experiments on the SLU Evaluation (SLUE) benchmark and observe self-supervised pre-trained models to be more powerful, with pre-trained LM and speech models being most beneficial for the Sentiment Analysis and Named Entity Recognition task, respectively.
Token-level Sequence Labeling for Spoken Language Understanding using Compositional End-to-End Models
Oct 27, 2022End-to-end spoken language understanding (SLU) systems are gaining popularity over cascaded approaches due to their simplicity and ability to avoid error propagation. However, these systems model sequence labeling as a sequence prediction task causing a divergence from its well-established token-level tagging formulation. We build compositional end-to-end SLU systems that explicitly separate the added complexity of recognizing spoken mentions in SLU from the NLU task of sequence labeling. By relying on intermediate decoders trained for ASR, our end-to-end systems transform the input modality from speech to token-level representations that can be used in the traditional sequence labeling framework. This composition of ASR and NLU formulations in our end-to-end SLU system offers direct compatibility with pre-trained ASR and NLU systems, allows performance monitoring of individual components and enables the use of globally normalized losses like CRF, making them attractive in practical scenarios. Our models outperform both cascaded and direct end-to-end models on a labeling task of named entity recognition across SLU benchmarks.
CTC Alignments Improve Autoregressive Translation
Oct 11, 2022
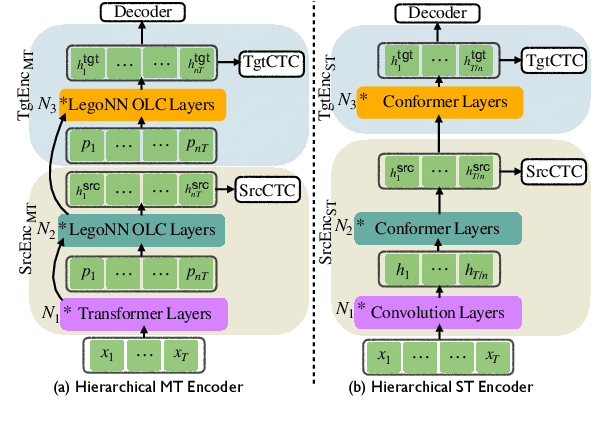

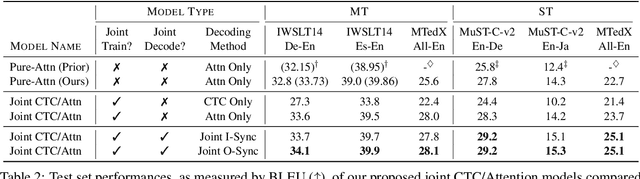
Connectionist Temporal Classification (CTC) is a widely used approach for automatic speech recognition (ASR) that performs conditionally independent monotonic alignment. However for translation, CTC exhibits clear limitations due to the contextual and non-monotonic nature of the task and thus lags behind attentional decoder approaches in terms of translation quality. In this work, we argue that CTC does in fact make sense for translation if applied in a joint CTC/attention framework wherein CTC's core properties can counteract several key weaknesses of pure-attention models during training and decoding. To validate this conjecture, we modify the Hybrid CTC/Attention model originally proposed for ASR to support text-to-text translation (MT) and speech-to-text translation (ST). Our proposed joint CTC/attention models outperform pure-attention baselines across six benchmark translation tasks.