 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the 2023 ML-SUPERB Challenge: Pre-Training and Evaluation over More Languages and Beyond
Oct 09, 2023



The 2023 Multilingual Speech Universal Performance Benchmark (ML-SUPERB) Challenge expands upon the acclaimed SUPERB framework, emphasizing self-supervised models in multilingual speech recognition and language identification. The challenge comprises a research track focused on applying ML-SUPERB to specific multilingual subjects, a Challenge Track for model submissions, and a New Language Track where language resource researchers can contribute and evaluate their low-resource language data in the context of the latest progress in multilingual speech recognition. The challenge garnered 12 model submissions and 54 language corpora, resulting in a comprehensive benchmark encompassing 154 languages. The findings indicate that merely scaling models is not the definitive solution for multilingual speech tasks, and a variety of speech/voice types present significant challenges in multilingual speech processing.
Reproducing Whisper-Style Training Using an Open-Source Toolkit and Publicly Available Data
Oct 02, 2023Pre-training speech models on large volumes of data has achieved remarkable success. OpenAI Whisper is a multilingual multitask model trained on 680k hours of supervised speech data. It generalizes well to various speech recognition and translation benchmarks even in a zero-shot setup. However, the full pipeline for developing such models (from data collection to training) is not publicly accessible, which makes it difficult for researchers to further improve its performance and address training-related issues such as efficiency, robustness, fairness, and bias. This work presents an Open Whisper-style Speech Model (OWSM), which reproduces Whisper-style training using an open-source toolkit and publicly available data. OWSM even supports more translation directions and can be more efficient to train. We will publicly release all scripts used for data preparation, training, inference, and scoring as well as pre-trained models and training logs to promote open science.
Joint Prediction and Denoising for Large-scale Multilingual Self-supervised Learning
Sep 28, 2023Multilingual self-supervised learning (SSL) has often lagged behind state-of-the-art (SOTA) methods due to the expenses and complexity required to handle many languages. This further harms the reproducibility of SSL, which is already limited to few research groups due to its resource usage. We show that more powerful techniques can actually lead to more efficient pre-training, opening SSL to more research groups. We propose WavLabLM, which extends WavLM's joint prediction and denoising to 40k hours of data across 136 languages. To build WavLabLM, we devise a novel multi-stage pre-training method, designed to address the language imbalance of multilingual data. WavLabLM achieves comparable performance to XLS-R on ML-SUPERB with less than 10% of the training data, making SSL realizable with academic compute. We show that further efficiency can be achieved with a vanilla HuBERT Base model, which can maintain 94% of XLS-R's performance with only 3% of the data, 4 GPUs, and limited trials. We open-source all code and models in ESPnet.
ML-SUPERB: Multilingual Speech Universal PERformance Benchmark
May 18, 2023

Speech processing Universal PERformance Benchmark (SUPERB) is a leaderboard to benchmark the performance of Self-Supervised Learning (SSL) models on various speech processing tasks. However, SUPERB largely considers English speech in its evaluation. This paper presents multilingual SUPERB (ML-SUPERB), covering 143 languages (ranging from high-resource to endangered), and considering both automatic speech recognition and language identification. Following the concept of SUPERB, ML-SUPERB utilizes frozen SSL features and employs a simple framework for multilingual tasks by learning a shallow downstream model. Similar to the SUPERB benchmark, we find speech SSL models can significantly improve performance compared to FBANK features. Furthermore, we find that multilingual models do not always perform better than their monolingual counterparts. We will release ML-SUPERB as a challenge with organized datasets and reproducible training scripts for future multilingual representation research.
ESPnet-ST-v2: Multipurpose Spoken Language Translation Toolkit
Apr 11, 2023



ESPnet-ST-v2 is a revamp of the open-source ESPnet-ST toolkit necessitated by the broadening interests of the spoken language translation community. ESPnet-ST-v2 supports 1) offline speech-to-text translation (ST), 2) simultaneous speech-to-text translation (SST), and 3) offline speech-to-speech translation (S2ST) -- each task is supported with a wide variety of approaches, differentiating ESPnet-ST-v2 from other open source spoken language translation toolkits. This toolkit offers state-of-the-art architectures such as transducers, hybrid CTC/attention, multi-decoders with searchable intermediates, time-synchronous blockwise CTC/attention, Translatotron models, and direct discrete unit models. In this paper, we describe the overall design, example models for each task, and performance benchmarking behind ESPnet-ST-v2, which is publicly available at https://github.com/espnet/espnet.
More Speaking or More Speakers?
Nov 02, 2022



Self-training (ST) and self-supervised learning (SSL) methods have demonstrated strong improvements in automatic speech recognition (ASR). In spite of these advances, to the best of our knowledge, there is no analysis of how the composition of the labelled and unlabelled datasets used in these methods affects the results. In this work we aim to analyse the effect of numbers of speakers in the training data on a recent SSL algorithm (wav2vec 2.0), and a recent ST algorithm (slimIPL). We perform a systematic analysis on both labeled and unlabeled data by varying the number of speakers while keeping the number of hours fixed and vice versa. Our findings suggest that SSL requires a large amount of unlabeled data to produce high accuracy results, while ST requires a sufficient number of speakers in the labelled data, especially in the low-regime setting. In this manner these two approaches improve supervised learning in different regimes of dataset composition.
Avoid Overthinking in Self-Supervised Models for Speech Recognition
Nov 01, 2022Self-supervised learning (SSL) models reshaped our approach to speech, language and vision. However their huge size and the opaque relations between their layers and tasks result in slow inference and network overthinking, where predictions made from the last layer of large models is worse than those made from intermediate layers. Early exit (EE) strategies can solve both issues by dynamically reducing computations at inference time for certain samples. Although popular for classification tasks in vision and language, EE has seen less use for sequence-to-sequence speech recognition (ASR) tasks where outputs from early layers are often degenerate. This challenge is further compounded when speech SSL models are applied on out-of-distribution (OOD) data. This paper first shows that SSL models do overthinking in ASR. We then motivate further research in EE by computing an optimal bound for performance versus speed trade-offs. To approach this bound we propose two new strategies for ASR: (1) we adapt the recently proposed patience strategy to ASR; and (2) we design a new EE strategy specific to ASR that performs better than all strategies previously introduced.
Continuous Pseudo-Labeling from the Start
Oct 17, 2022
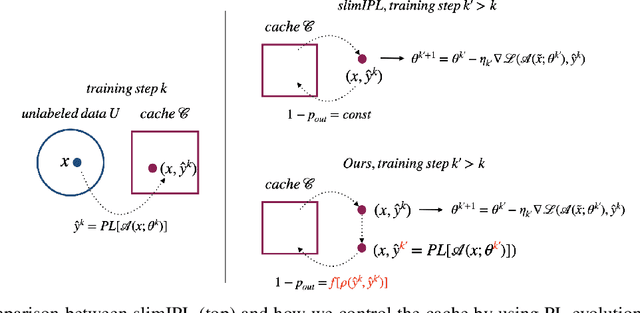
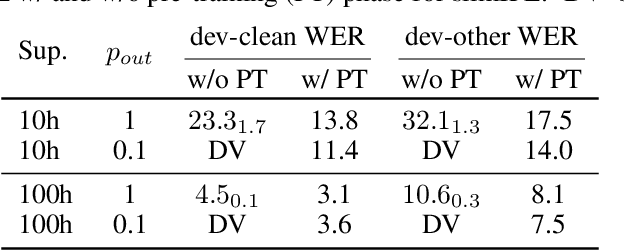
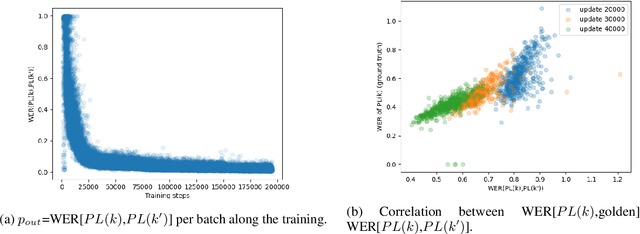
Self-training (ST), or pseudo-labeling has sparked significant interest in the automatic speech recognition (ASR) community recently because of its success in harnessing unlabeled data. Unlike prior semi-supervised learning approaches that relied on iteratively regenerating pseudo-labels (PLs) from a trained model and using them to train a new model, recent state-of-the-art methods perform `continuous training' where PLs are generated using a very recent version of the model being trained. Nevertheless, these approaches still rely on bootstrapping the ST using an initial supervised learning phase where the model is trained on labeled data alone. We believe this has the potential for over-fitting to the labeled dataset in low resource settings and that ST from the start of training should reduce over-fitting. In this paper we show how we can do this by dynamically controlling the evolution of PLs during the training process in ASR. To the best of our knowledge, this is the first study that shows the feasibility of generating PLs from the very start of the training. We are able to achieve this using two techniques that avoid instabilities which lead to degenerate models that do not generalize. Firstly, we control the evolution of PLs through a curriculum that uses the online changes in PLs to control the membership of the cache of PLs and improve generalization. Secondly, we find that by sampling transcriptions from the predictive distribution, rather than only using the best transcription, we can stabilize training further. With these techniques, our ST models match prior works without an external language model.
Combining Spectral and Self-Supervised Features for Low Resource Speech Recognition and Translation
Apr 18, 2022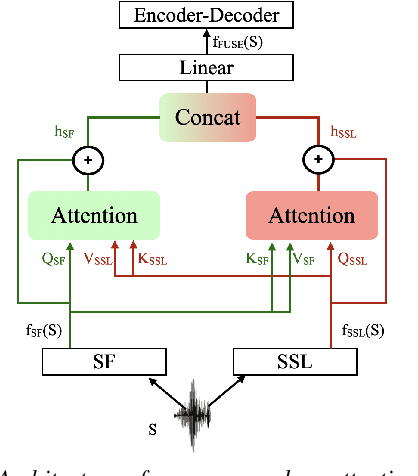
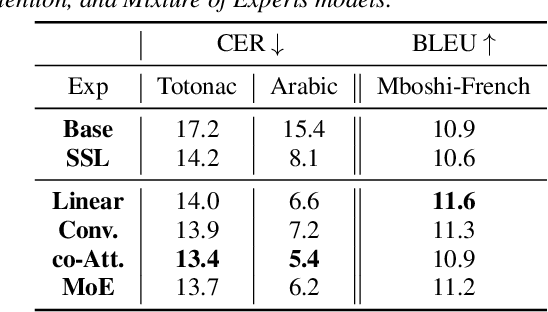
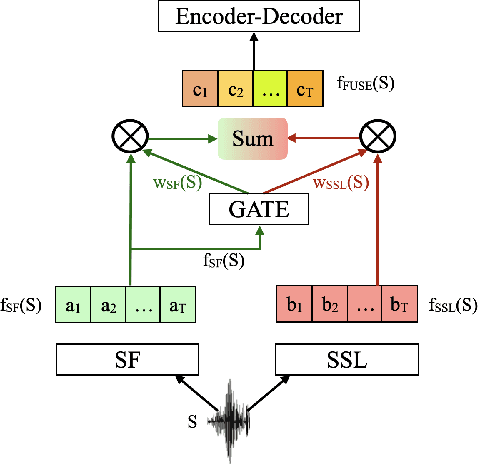

Self-Supervised Learning (SSL) models have been successfully applied in various deep learning-based speech tasks, particularly those with a limited amount of data. However, the quality of SSL representations depends highly on the relatedness between the SSL training domain(s) and the target data domain. On the contrary, spectral feature (SF) extractors such as log Mel-filterbanks are hand-crafted non-learnable components, and could be more robust to domain shifts. The present work examines the assumption that combining non-learnable SF extractors to SSL models is an effective approach to low resource speech tasks. We propose a learnable and interpretable framework to combine SF and SSL representations. The proposed framework outperforms significantly both baseline and SSL models on Automatic Speech Recognition (ASR) and Speech Translation (ST) tasks on three low resource datasets. We additionally design a mixture of experts based combination model. This last model reveals that the relative contribution of SSL models over conventional SF extractors is very small in case of domain mismatch between SSL training set and the target language data.
Joint Modeling of Code-Switched and Monolingual ASR via Conditional Factorization
Nov 29, 2021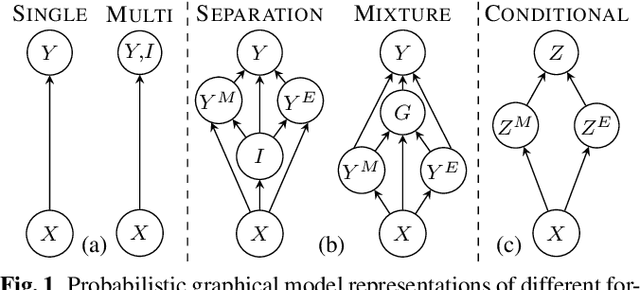
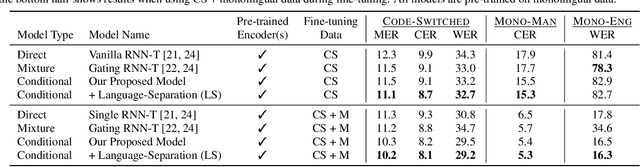
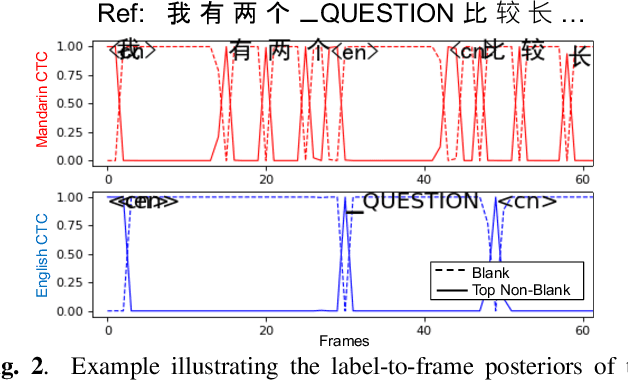
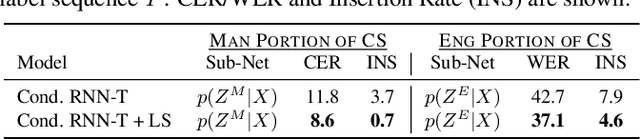
Conversational bilingual speech encompasses three types of utterances: two purely monolingual types and one intra-sententially code-switched type. In this work, we propose a general framework to jointly model the likelihoods of the monolingual and code-switch sub-tasks that comprise bilingual speech recognition. By defining the monolingual sub-tasks with label-to-frame synchronization, our joint modeling framework can be conditionally factorized such that the final bilingual output, which may or may not be code-switched, is obtained given only monolingual information. We show that this conditionally factorized joint framework can be modeled by an end-to-end differentiable neural network. We demonstrate the efficacy of our proposed model on bilingual Mandarin-English speech recognition across both monolingual and code-switched corpora.