 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTri-Info: Generalizable, Interpretable Failure Prediction for VLA Models via Information Theory
Jun 18, 2026Vision-Language-Action (VLA) models are increasingly deployed across diverse tasks, yet they remain black boxes whose physical interactions can cause irreversible harm, making generalizable and interpretable failure detection essential. We observe that successful and failed rollouts carry systematically different information-theoretic signatures. Building on this, we formalize VLA control as a closed-loop information pipeline and derive the Triple Information-theoretic (Tri-Info) signals that capture whether actions remain diverse, temporally consistent, and coupled to state transitions. Across six VLA models and three benchmark environments, Tri-Info matches the strongest baselines in-domain. Moreover, Tri-Info transfers across architectures, environments, and the sim-to-real gap without retraining, reaching 83\% accuracy on real-world tasks where prior detectors collapse to chance. This establishes Tri-Info as a simple yet powerful method that not only detects failures with strong cross-domain generalization, but also delivers interpretable diagnostics of the underlying failure modes.
InfoAtlas: A Foundation Model for Zero-Shot Statistical Dependence Estimate
May 29, 2026Measuring statistical dependency between high-dimensional random variables is a fundamental task in data science and machine learning. Neural mutual information (MI) estimators offer a promising avenue, but they typically require costly iterative optimization for each new dataset, making them impractical for real-time applications. We present InfoAtlas, a foundation model-like architecture that eliminates this bottleneck by directly inferring MI in a single forward pass. Pretrained on large-scale synthetic data with rich dependence patterns, InfoAtlas learns to identify diverse dependence structures and predict MI directly from the dataset. Comprehensive experiments demonstrate that InfoAtlas matches state-of-the-art neural estimators in accuracy while achieving $100\times$ speedup, can flexibly handle varying dimensions and sample sizes through a single unified model, and generalizes effectively to complex, real-world scenarios. By reformulating MI estimation as an inference task, InfoAtlas establishes a foundation for real-time dependency analysis.
A Hypernetwork Based Framework for Non-Stationary Channel Prediction
Jan 16, 2024



In order to break through the development bottleneck of modern wireless communication networks, a critical issue is the out-of-date channel state information (CSI) in high mobility scenarios. In general, non-stationary CSI has statistical properties which vary with time, implying that the data distribution changes continuously over time. This temporal distribution shift behavior undermines the accurate channel prediction and it is still an open problem in the related literature. In this paper, a hypernetwork based framework is proposed for non-stationary channel prediction. The framework aims to dynamically update the neural network (NN) parameters as the wireless channel changes to automatically adapt to various input CSI distributions. Based on this framework, we focus on low-complexity hypernetwork design and present a deep learning (DL) based channel prediction method, termed as LPCNet, which improves the CSI prediction accuracy with acceptable complexity. Moreover, to maximize the achievable downlink spectral efficiency (SE), a joint channel prediction and beamforming (BF) method is developed, termed as JLPCNet, which seeks to predict the BF vector. Our numerical results showcase the effectiveness and flexibility of the proposed framework, and demonstrate the superior performance of LPCNet and JLPCNet in various scenarios for fixed and varying user speeds.
Divided Attention: Unsupervised Multi-Object Discovery with Contextually Separated Slots
Apr 04, 2023



We introduce a method to segment the visual field into independently moving regions, trained with no ground truth or supervision. It consists of an adversarial conditional encoder-decoder architecture based on Slot Attention, modified to use the image as context to decode optical flow without attempting to reconstruct the image itself. In the resulting multi-modal representation, one modality (flow) feeds the encoder to produce separate latent codes (slots), whereas the other modality (image) conditions the decoder to generate the first (flow) from the slots. This design frees the representation from having to encode complex nuisance variability in the image due to, for instance, illumination and reflectance properties of the scene. Since customary autoencoding based on minimizing the reconstruction error does not preclude the entire flow from being encoded into a single slot, we modify the loss to an adversarial criterion based on Contextual Information Separation. The resulting min-max optimization fosters the separation of objects and their assignment to different attention slots, leading to Divided Attention, or DivA. DivA outperforms recent unsupervised multi-object motion segmentation methods while tripling run-time speed up to 104FPS and reducing the performance gap from supervised methods to 12% or less. DivA can handle different numbers of objects and different image sizes at training and test time, is invariant to permutation of object labels, and does not require explicit regularization.
A Learnable Optimization and Regularization Approach to Massive MIMO CSI Feedback
Sep 30, 2022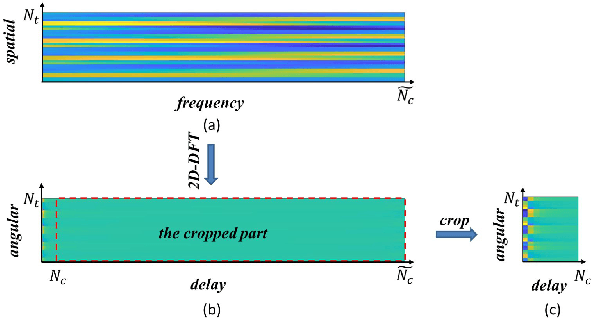
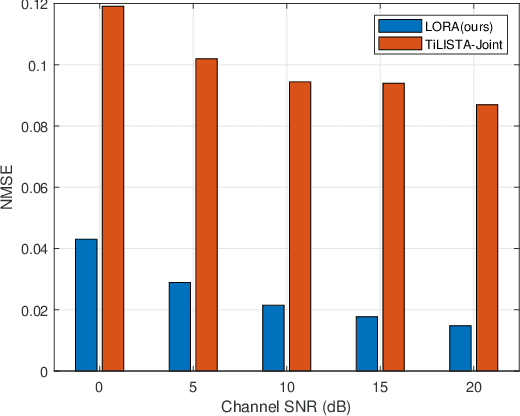
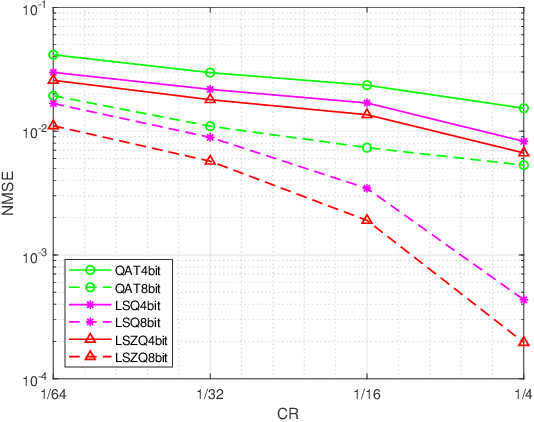
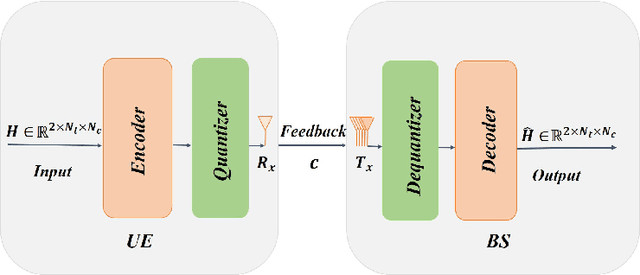
Channel state information (CSI) plays a critical role in achieving the potential benefits of massive multiple input multiple output (MIMO) systems. In frequency division duplex (FDD) massive MIMO systems, the base station (BS) relies on sustained and accurate CSI feedback from the users. However, due to the large number of antennas and users being served in massive MIMO systems, feedback overhead can become a bottleneck. In this paper, we propose a model-driven deep learning method for CSI feedback, called learnable optimization and regularization algorithm (LORA). Instead of using l1-norm as the regularization term, a learnable regularization module is introduced in LORA to automatically adapt to the characteristics of CSI. We unfold the conventional iterative shrinkage-thresholding algorithm (ISTA) to a neural network and learn both the optimization process and regularization term by end-toend training. We show that LORA improves the CSI feedback accuracy and speed. Besides, a novel learnable quantization method and the corresponding training scheme are proposed, and it is shown that LORA can operate successfully at different bit rates, providing flexibility in terms of the CSI feedback overhead. Various realistic scenarios are considered to demonstrate the effectiveness and robustness of LORA through numerical simulations.