 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-View Exocentric to Egocentric Video Synthesis
Jul 07, 2021

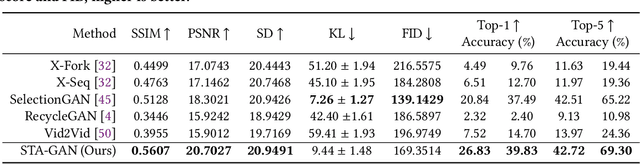
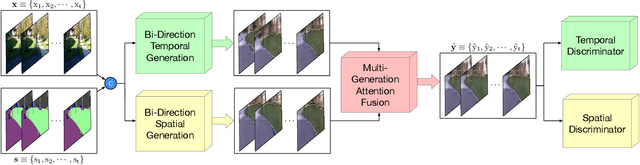
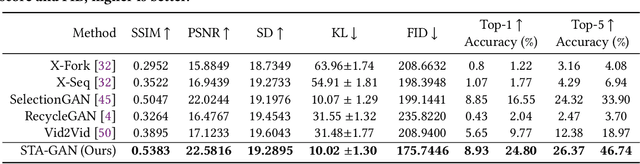
Cross-view video synthesis task seeks to generate video sequences of one view from another dramatically different view. In this paper, we investigate the exocentric (third-person) view to egocentric (first-person) view video generation task. This is challenging because egocentric view sometimes is remarkably different from the exocentric view. Thus, transforming the appearances across the two different views is a non-trivial task. Particularly, we propose a novel Bi-directional Spatial Temporal Attention Fusion Generative Adversarial Network (STA-GAN) to learn both spatial and temporal information to generate egocentric video sequences from the exocentric view. The proposed STA-GAN consists of three parts: temporal branch, spatial branch, and attention fusion. First, the temporal and spatial branches generate a sequence of fake frames and their corresponding features. The fake frames are generated in both downstream and upstream directions for both temporal and spatial branches. Next, the generated four different fake frames and their corresponding features (spatial and temporal branches in two directions) are fed into a novel multi-generation attention fusion module to produce the final video sequence. Meanwhile, we also propose a novel temporal and spatial dual-discriminator for more robust network optimization. Extensive experiments on the Side2Ego and Top2Ego datasets show that the proposed STA-GAN significantly outperforms the existing methods.
Federated Learning for Multi-Center Imaging Diagnostics: A Study in Cardiovascular Disease
Jul 07, 2021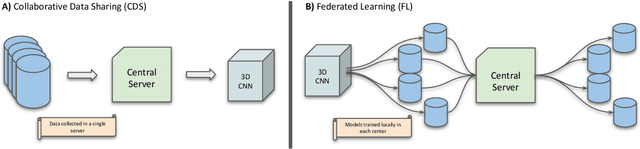

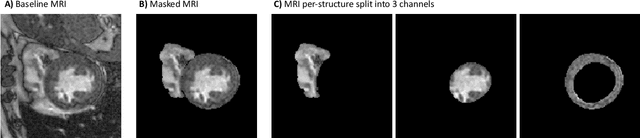

Deep learning models can enable accurate and efficient disease diagnosis, but have thus far been hampered by the data scarcity present in the medical world. Automated diagnosis studies have been constrained by underpowered single-center datasets, and although some results have shown promise, their generalizability to other institutions remains questionable as the data heterogeneity between institutions is not taken into account. By allowing models to be trained in a distributed manner that preserves patients' privacy, federated learning promises to alleviate these issues, by enabling diligent multi-center studies. We present the first federated learning study on the modality of cardiovascular magnetic resonance (CMR) and use four centers derived from subsets of the M\&M and ACDC datasets, focusing on the diagnosis of hypertrophic cardiomyopathy (HCM). We adapt a 3D-CNN network pretrained on action recognition and explore two different ways of incorporating shape prior information to the model, and four different data augmentation set-ups, systematically analyzing their impact on the different collaborative learning choices. We show that despite the small size of data (180 subjects derived from four centers), the privacy preserving federated learning achieves promising results that are competitive with traditional centralized learning. We further find that federatively trained models exhibit increased robustness and are more sensitive to domain shift effects.
Annotation of Chinese Predicate Heads and Relevant Elements
Apr 01, 2021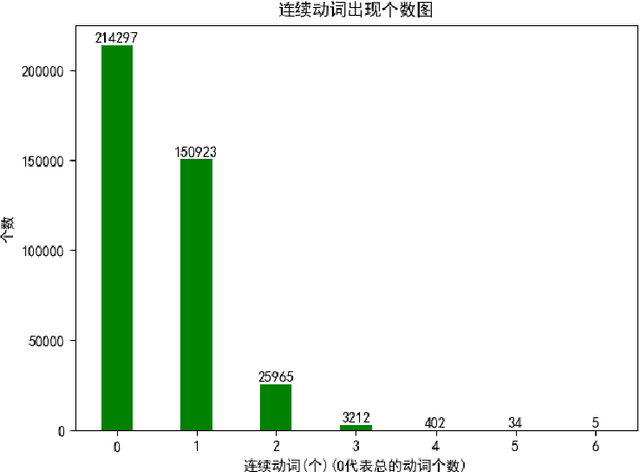
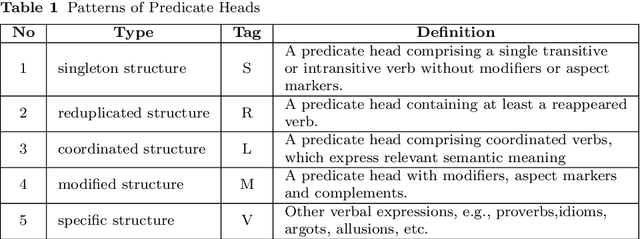
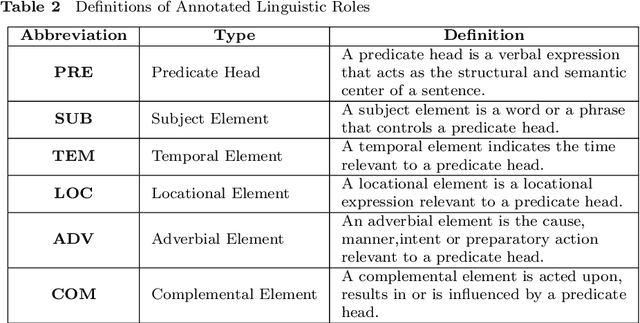
A predicate head is a verbal expression that plays a role as the structural center of a sentence. Identifying predicate heads is critical to understanding a sentence. It plays the leading role in organizing the relevant syntactic elements in a sentence, including subject elements, adverbial elements, etc. For some languages, such as English, word morphologies are valuable for identifying predicate heads. However, Chinese offers no morphological information to indicate words` grammatical roles. A Chinese sentence often contains several verbal expressions; identifying the expression that plays the role of the predicate head is not an easy task. Furthermore, Chinese sentences are inattentive to structure and provide no delimitation between words. Therefore, identifying Chinese predicate heads involves significant challenges. In Chinese information extraction, little work has been performed in predicate head recognition. No generally accepted evaluation dataset supports work in this important area. This paper presents the first attempt to develop an annotation guideline for Chinese predicate heads and their relevant syntactic elements. This annotation guideline emphasizes the role of the predicate as the structural center of a sentence. The design of relevant syntactic element annotation also follows this principle. Many considerations are proposed to achieve this goal, e.g., patterns of predicate heads, a flattened annotation structure, and a simpler syntactic unit type. Based on the proposed annotation guideline, more than 1,500 documents were manually annotated. The corpus will be available online for public access. With this guideline and annotated corpus, our goal is to broadly impact and advance the research in the area of Chinese information extraction and to provide the research community with a critical resource that has been lacking for a long time.
End-to-End Hierarchical Relation Extraction for Generic Form Understanding
Jun 02, 2021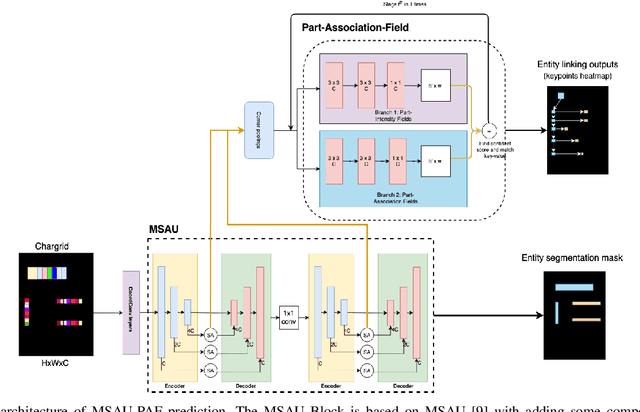
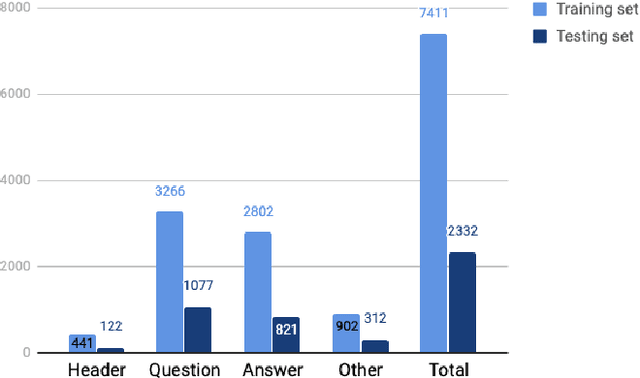
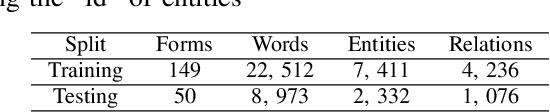

Form understanding is a challenging problem which aims to recognize semantic entities from the input document and their hierarchical relations. Previous approaches face significant difficulty dealing with the complexity of the task, thus treat these objectives separately. To this end, we present a novel deep neural network to jointly perform both entity detection and link prediction in an end-to-end fashion. Our model extends the Multi-stage Attentional U-Net architecture with the Part-Intensity Fields and Part-Association Fields for link prediction, enriching the spatial information flow with the additional supervision from entity linking. We demonstrate the effectiveness of the model on the Form Understanding in Noisy Scanned Documents (FUNSD) dataset, where our method substantially outperforms the original model and state-of-the-art baselines in both Entity Labeling and Entity Linking task.
* Accepted to ICPR 2020
DTGAN: Differential Private Training for Tabular GANs
Aug 02, 2021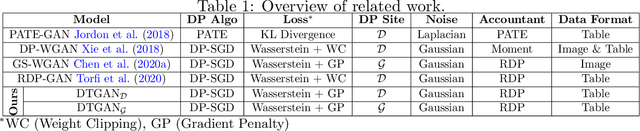
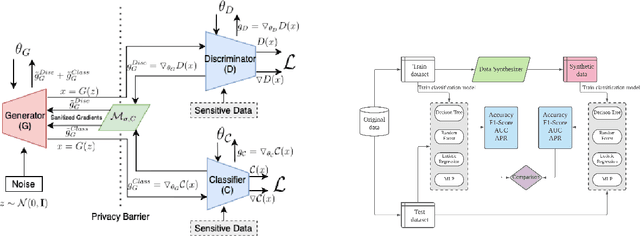

Tabular generative adversarial networks (TGAN) have recently emerged to cater to the need of synthesizing tabular data -- the most widely used data format. While synthetic tabular data offers the advantage of complying with privacy regulations, there still exists a risk of privacy leakage via inference attacks due to interpolating the properties of real data during training. Differential private (DP) training algorithms provide theoretical guarantees for training machine learning models by injecting statistical noise to prevent privacy leaks. However, the challenges of applying DP on TGAN are to determine the most optimal framework (i.e., PATE/DP-SGD) and neural network (i.e., Generator/Discriminator)to inject noise such that the data utility is well maintained under a given privacy guarantee. In this paper, we propose DTGAN, a novel conditional Wasserstein tabular GAN that comes in two variants DTGAN_G and DTGAN_D, for providing a detailed comparison of tabular GANs trained using DP-SGD for the generator vs discriminator, respectively. We elicit the privacy analysis associated with training the generator with complex loss functions (i.e., classification and information losses) needed for high quality tabular data synthesis. Additionally, we rigorously evaluate the theoretical privacy guarantees offered by DP empirically against membership and attribute inference attacks. Our results on 3 datasets show that the DP-SGD framework is superior to PATE and that a DP discriminator is more optimal for training convergence. Thus, we find (i) DTGAN_D is capable of maintaining the highest data utility across 4 ML models by up to 18% in terms of the average precision score for a strict privacy budget, epsilon = 1, as compared to the prior studies and (ii) DP effectively prevents privacy loss against inference attacks by restricting the success probability of membership attacks to be close to 50%.
HDMI: High-order Deep Multiplex Infomax
Feb 28, 2021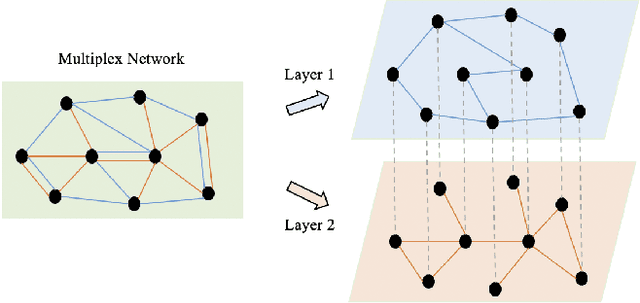

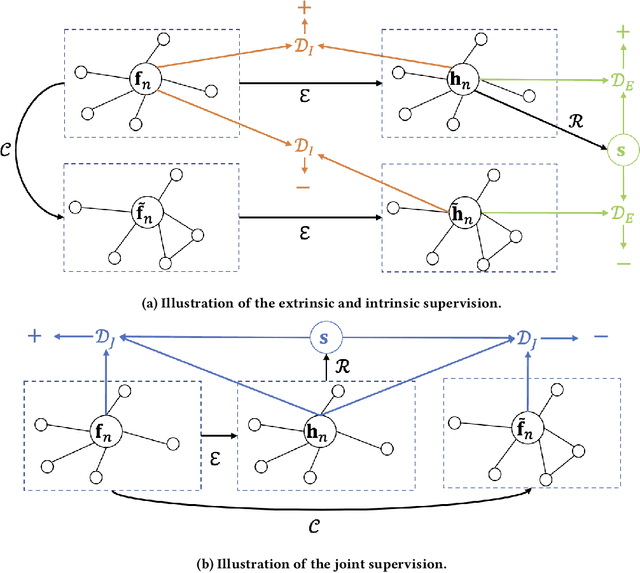
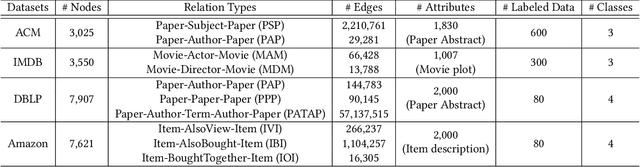
Networks have been widely used to represent the relations between objects such as academic networks and social networks, and learning embedding for networks has thus garnered plenty of research attention. Self-supervised network representation learning aims at extracting node embedding without external supervision. Recently, maximizing the mutual information between the local node embedding and the global summary (e.g. Deep Graph Infomax, or DGI for short) has shown promising results on many downstream tasks such as node classification. However, there are two major limitations of DGI. Firstly, DGI merely considers the extrinsic supervision signal (i.e., the mutual information between node embedding and global summary) while ignores the intrinsic signal (i.e., the mutual dependence between node embedding and node attributes). Secondly, nodes in a real-world network are usually connected by multiple edges with different relations, while DGI does not fully explore the various relations among nodes. To address the above-mentioned problems, we propose a novel framework, called High-order Deep Multiplex Infomax (HDMI), for learning node embedding on multiplex networks in a self-supervised way. To be more specific, we first design a joint supervision signal containing both extrinsic and intrinsic mutual information by high-order mutual information, and we propose a High-order Deep Infomax (HDI) to optimize the proposed supervision signal. Then we propose an attention based fusion module to combine node embedding from different layers of the multiplex network. Finally, we evaluate the proposed HDMI on various downstream tasks such as unsupervised clustering and supervised classification. The experimental results show that HDMI achieves state-of-the-art performance on these tasks.
LPF: A Language-Prior Feedback Objective Function for De-biased Visual Question Answering
Jun 23, 2021
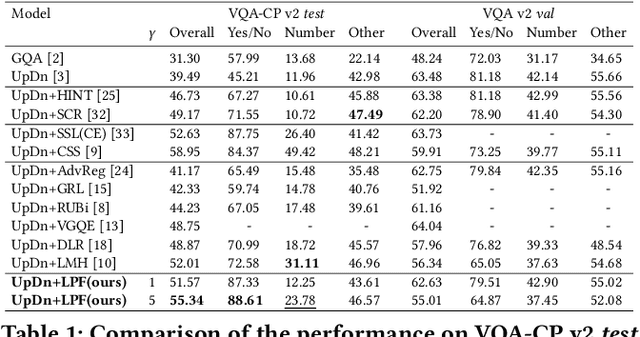
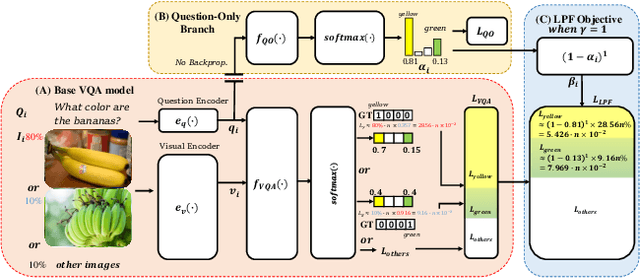
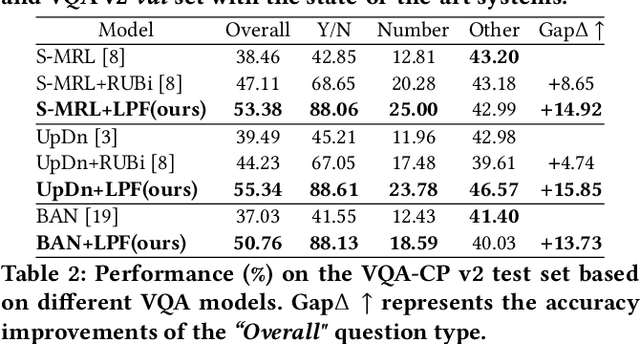
Most existing Visual Question Answering (VQA) systems tend to overly rely on language bias and hence fail to reason from the visual clue. To address this issue, we propose a novel Language-Prior Feedback (LPF) objective function, to re-balance the proportion of each answer's loss value in the total VQA loss. The LPF firstly calculates a modulating factor to determine the language bias using a question-only branch. Then, the LPF assigns a self-adaptive weight to each training sample in the training process. With this reweighting mechanism, the LPF ensures that the total VQA loss can be reshaped to a more balanced form. By this means, the samples that require certain visual information to predict will be efficiently used during training. Our method is simple to implement, model-agnostic, and end-to-end trainable. We conduct extensive experiments and the results show that the LPF (1) brings a significant improvement over various VQA models, (2) achieves competitive performance on the bias-sensitive VQA-CP v2 benchmark.
Can Less be More? When Increasing-to-Balancing Label Noise Rates Considered Beneficial
Jul 13, 2021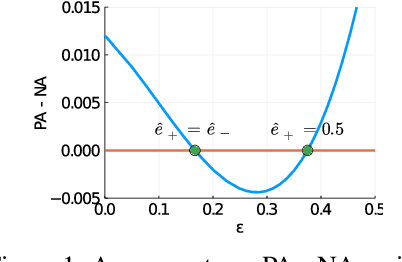
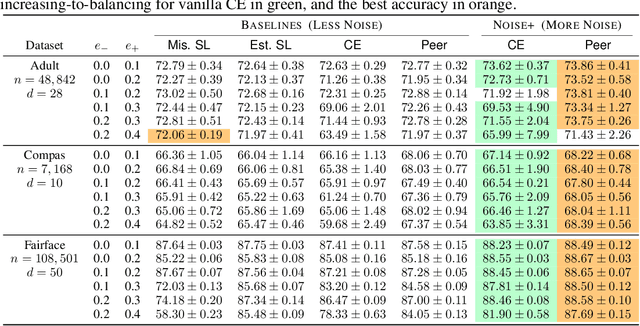

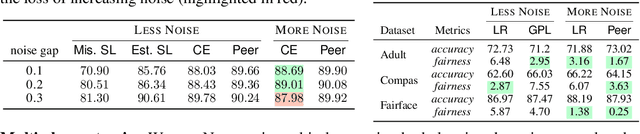
In this paper, we answer the question when inserting label noise (less informative labels) can instead return us more accurate and fair models. We are primarily inspired by two observations that 1) increasing a certain class of instances' label noise to balance the noise rates (increasing-to-balancing) results in an easier learning problem; 2) Increasing-to-balancing improves fairness guarantees against label bias. In this paper, we will first quantify the trade-offs introduced by increasing a certain group of instances' label noise rate w.r.t. the learning difficulties and performance guarantees. We analytically demonstrate when such an increase proves to be beneficial, in terms of either improved generalization errors or the fairness guarantees. Then we present a method to leverage our idea of inserting label noise for the task of learning with noisy labels, either without or with a fairness constraint. The primary technical challenge we face is due to the fact that we would not know which data instances are suffering from higher noise, and we would not have the ground truth labels to verify any possible hypothesis. We propose a detection method that informs us which group of labels might suffer from higher noise, without using ground truth information. We formally establish the effectiveness of the proposed solution and demonstrate it with extensive experiments.
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jun 15, 2021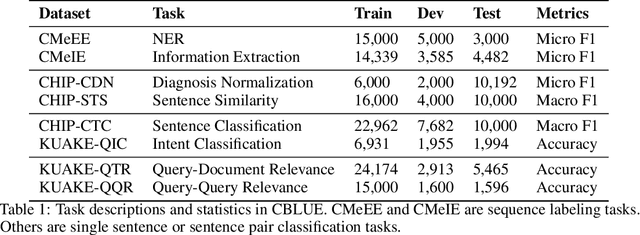
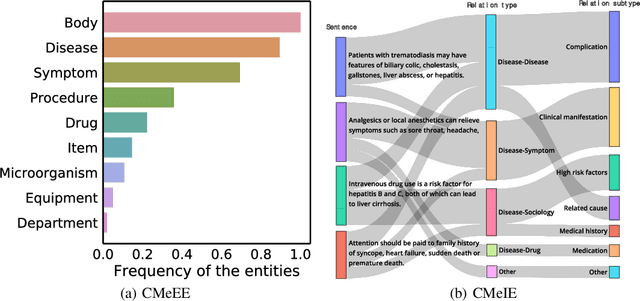
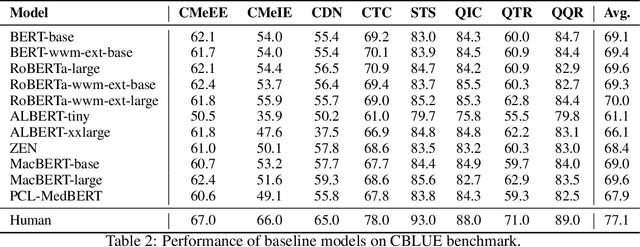
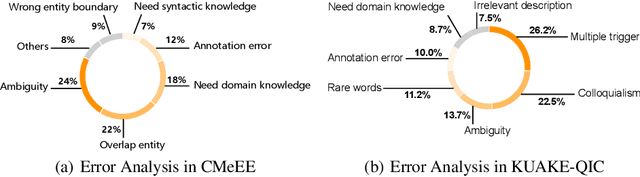
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.
LambdaUNet: 2.5D Stroke Lesion Segmentation of Diffusion-weighted MR Images
Apr 28, 2021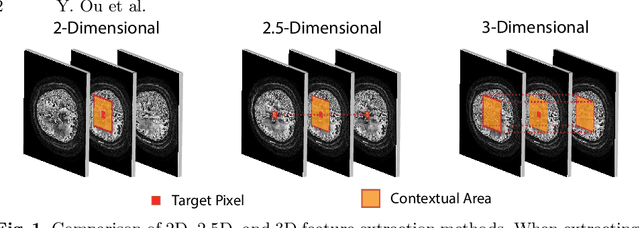
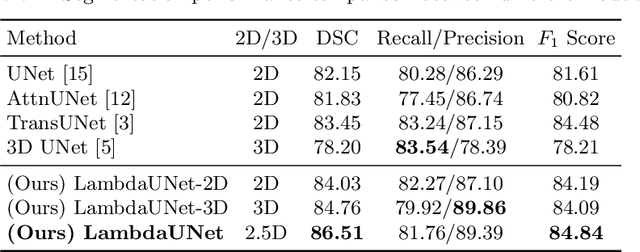


Diffusion-weighted (DW) magnetic resonance imaging is essential for the diagnosis and treatment of ischemic stroke. DW images (DWIs) are usually acquired in multi-slice settings where lesion areas in two consecutive 2D slices are highly discontinuous due to large slice thickness and sometimes even slice gaps. Therefore, although DWIs contain rich 3D information, they cannot be treated as regular 3D or 2D images. Instead, DWIs are somewhere in-between (or 2.5D) due to the volumetric nature but inter-slice discontinuities. Thus, it is not ideal to apply most existing segmentation methods as they are designed for either 2D or 3D images. To tackle this problem, we propose a new neural network architecture tailored for segmenting highly-discontinuous 2.5D data such as DWIs. Our network, termed LambdaUNet, extends UNet by replacing convolutional layers with our proposed Lambda+ layers. In particular, Lambda+ layers transform both intra-slice and inter-slice context around a pixel into linear functions, called lambdas, which are then applied to the pixel to produce informative 2.5D features. LambdaUNet is simple yet effective in combining sparse inter-slice information from adjacent slices while also capturing dense contextual features within a single slice. Experiments on a unique clinical dataset demonstrate that LambdaUNet outperforms existing 3D/2D image segmentation methods including recent variants of UNet. Code for LambdaUNet will be released with the publication to facilitate future research.