 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Flow-VAE for Safety-Critical Traffic Scenario Generation
May 06, 2026Safety-critical scenarios are essential for the development of autonomous vehicles (AVs) but are rare in real-world driving data. While simulation offers a way to generate such scenarios, manually designed test cases lack scalability, and adversarial optimization often produces unrealistic behaviors. In this work, we introduce a conditional latent flow matching approach for scalable and realistic safety-critical scenario generation. Our method uses distribution matching to transform nominal scenes into safety-critical rollouts. Furthermore, we demonstrate that incorporating both simulation and real-world data enables our framework to efficiently generate diverse, data-driven scenarios. Experimental results highlight that our approach is able to more consistently and realistically generate novel safety-critical scenarios, making it a valuable tool for training and benchmarking AV systems.
Efficient Equivariant Transformer for Self-Driving Agent Modeling
Apr 01, 2026Accurately modeling agent behaviors is an important task in self-driving. It is also a task with many symmetries, such as equivariance to the order of agents and objects in the scene or equivariance to arbitrary roto-translations of the entire scene as a whole; i.e., SE(2)-equivariance. The transformer architecture is a ubiquitous tool for modeling these symmetries. While standard self-attention is inherently permutation equivariant, explicit pairwise relative positional encodings have been the standard for introducing SE(2)-equivariance. However, this approach introduces an additional cost that is quadratic in the number of agents, limiting its scalability to larger scenes and batch sizes. In this work, we propose DriveGATr, a novel transformer-based architecture for agent modeling that achieves SE(2)-equivariance without the computational cost of existing methods. Inspired by recent advances in geometric deep learning, DriveGATr encodes scene elements as multivectors in the 2D projective geometric algebra $\mathbb{R}^*_{2,0,1}$ and processes them with a stack of equivariant transformer blocks. Crucially, DriveGATr models geometric relationships using standard attention between multivectors, eliminating the need for costly explicit pairwise relative positional encodings. Experiments on the Waymo Open Motion Dataset demonstrate that DriveGATr is comparable to the state-of-the-art in traffic simulation and establishes a superior Pareto front for performance vs computational cost.
Learning to Drive via Asymmetric Self-Play
Sep 26, 2024



Large-scale data is crucial for learning realistic and capable driving policies. However, it can be impractical to rely on scaling datasets with real data alone. The majority of driving data is uninteresting, and deliberately collecting new long-tail scenarios is expensive and unsafe. We propose asymmetric self-play to scale beyond real data with additional challenging, solvable, and realistic synthetic scenarios. Our approach pairs a teacher that learns to generate scenarios it can solve but the student cannot, with a student that learns to solve them. When applied to traffic simulation, we learn realistic policies with significantly fewer collisions in both nominal and long-tail scenarios. Our policies further zero-shot transfer to generate training data for end-to-end autonomy, significantly outperforming state-of-the-art adversarial approaches, or using real data alone. For more information, visit https://waabi.ai/selfplay .
Unraveling Attacks in Machine Learning-based IoT Ecosystems: A Survey and the Open Libraries Behind Them
Jan 27, 2024



The advent of the Internet of Things (IoT) has brought forth an era of unprecedented connectivity, with an estimated 80 billion smart devices expected to be in operation by the end of 2025. These devices facilitate a multitude of smart applications, enhancing the quality of life and efficiency across various domains. Machine Learning (ML) serves as a crucial technology, not only for analyzing IoT-generated data but also for diverse applications within the IoT ecosystem. For instance, ML finds utility in IoT device recognition, anomaly detection, and even in uncovering malicious activities. This paper embarks on a comprehensive exploration of the security threats arising from ML's integration into various facets of IoT, spanning various attack types including membership inference, adversarial evasion, reconstruction, property inference, model extraction, and poisoning attacks. Unlike previous studies, our work offers a holistic perspective, categorizing threats based on criteria such as adversary models, attack targets, and key security attributes (confidentiality, availability, and integrity). We delve into the underlying techniques of ML attacks in IoT environment, providing a critical evaluation of their mechanisms and impacts. Furthermore, our research thoroughly assesses 65 libraries, both author-contributed and third-party, evaluating their role in safeguarding model and data privacy. We emphasize the availability and usability of these libraries, aiming to arm the community with the necessary tools to bolster their defenses against the evolving threat landscape. Through our comprehensive review and analysis, this paper seeks to contribute to the ongoing discourse on ML-based IoT security, offering valuable insights and practical solutions to secure ML models and data in the rapidly expanding field of artificial intelligence in IoT.
Learning Realistic Traffic Agents in Closed-loop
Nov 02, 2023Realistic traffic simulation is crucial for developing self-driving software in a safe and scalable manner prior to real-world deployment. Typically, imitation learning (IL) is used to learn human-like traffic agents directly from real-world observations collected offline, but without explicit specification of traffic rules, agents trained from IL alone frequently display unrealistic infractions like collisions and driving off the road. This problem is exacerbated in out-of-distribution and long-tail scenarios. On the other hand, reinforcement learning (RL) can train traffic agents to avoid infractions, but using RL alone results in unhuman-like driving behaviors. We propose Reinforcing Traffic Rules (RTR), a holistic closed-loop learning objective to match expert demonstrations under a traffic compliance constraint, which naturally gives rise to a joint IL + RL approach, obtaining the best of both worlds. Our method learns in closed-loop simulations of both nominal scenarios from real-world datasets as well as procedurally generated long-tail scenarios. Our experiments show that RTR learns more realistic and generalizable traffic simulation policies, achieving significantly better tradeoffs between human-like driving and traffic compliance in both nominal and long-tail scenarios. Moreover, when used as a data generation tool for training prediction models, our learned traffic policy leads to considerably improved downstream prediction metrics compared to baseline traffic agents. For more information, visit the project website: https://waabi.ai/rtr
GoRela: Go Relative for Viewpoint-Invariant Motion Forecasting
Nov 08, 2022The task of motion forecasting is critical for self-driving vehicles (SDVs) to be able to plan a safe maneuver. Towards this goal, modern approaches reason about the map, the agents' past trajectories and their interactions in order to produce accurate forecasts. The predominant approach has been to encode the map and other agents in the reference frame of each target agent. However, this approach is computationally expensive for multi-agent prediction as inference needs to be run for each agent. To tackle the scaling challenge, the solution thus far has been to encode all agents and the map in a shared coordinate frame (e.g., the SDV frame). However, this is sample inefficient and vulnerable to domain shift (e.g., when the SDV visits uncommon states). In contrast, in this paper, we propose an efficient shared encoding for all agents and the map without sacrificing accuracy or generalization. Towards this goal, we leverage pair-wise relative positional encodings to represent geometric relationships between the agents and the map elements in a heterogeneous spatial graph. This parameterization allows us to be invariant to scene viewpoint, and save online computation by re-using map embeddings computed offline. Our decoder is also viewpoint agnostic, predicting agent goals on the lane graph to enable diverse and context-aware multimodal prediction. We demonstrate the effectiveness of our approach on the urban Argoverse 2 benchmark as well as a novel highway dataset.
Asymmetry Disentanglement Network for Interpretable Acute Ischemic Stroke Infarct Segmentation in Non-Contrast CT Scans
Jun 30, 2022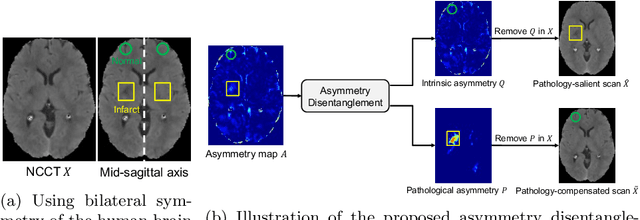
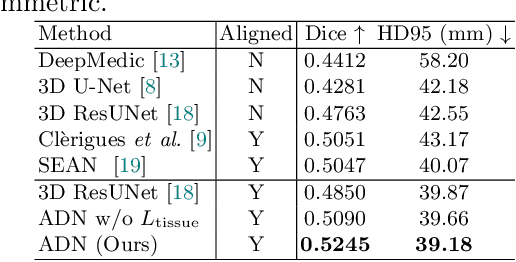
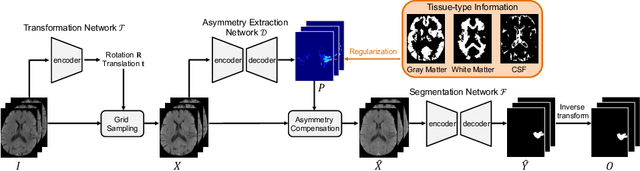
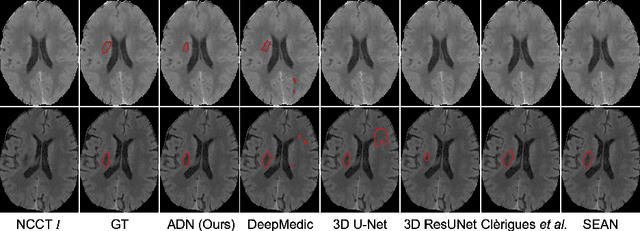
Accurate infarct segmentation in non-contrast CT (NCCT) images is a crucial step toward computer-aided acute ischemic stroke (AIS) assessment. In clinical practice, bilateral symmetric comparison of brain hemispheres is usually used to locate pathological abnormalities. Recent research has explored asymmetries to assist with AIS segmentation. However, most previous symmetry-based work mixed different types of asymmetries when evaluating their contribution to AIS. In this paper, we propose a novel Asymmetry Disentanglement Network (ADN) to automatically separate pathological asymmetries and intrinsic anatomical asymmetries in NCCTs for more effective and interpretable AIS segmentation. ADN first performs asymmetry disentanglement based on input NCCTs, which produces different types of 3D asymmetry maps. Then a synthetic, intrinsic-asymmetry-compensated and pathology-asymmetry-salient NCCT volume is generated and later used as input to a segmentation network. The training of ADN incorporates domain knowledge and adopts a tissue-type aware regularization loss function to encourage clinically-meaningful pathological asymmetry extraction. Coupled with an unsupervised 3D transformation network, ADN achieves state-of-the-art AIS segmentation performance on a public NCCT dataset. In addition to the superior performance, we believe the learned clinically-interpretable asymmetry maps can also provide insights towards a better understanding of AIS assessment. Our code is available at https://github.com/nihaomiao/MICCAI22_ADN.
Patcher: Patch Transformers with Mixture of Experts for Precise Medical Image Segmentation
Jun 03, 2022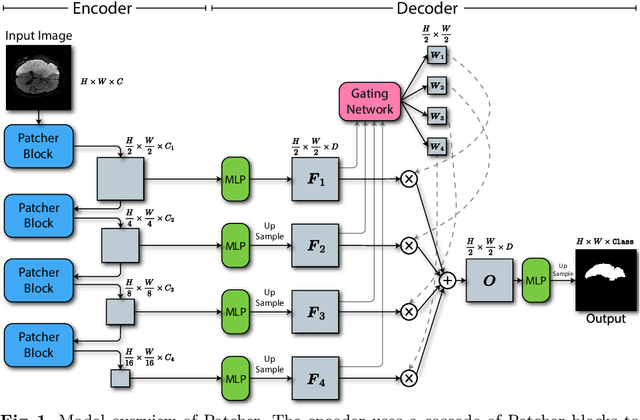
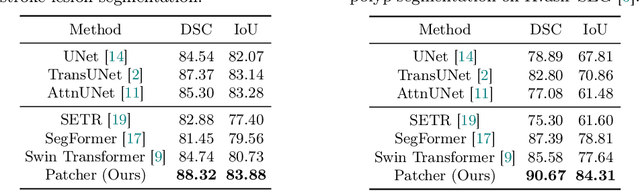


We present a new encoder-decoder Vision Transformer architecture, Patcher, for medical image segmentation. Unlike standard Vision Transformers, it employs Patcher blocks that segment an image into large patches, each of which is further divided into small patches. Transformers are applied to the small patches within a large patch, which constrains the receptive field of each pixel. We intentionally make the large patches overlap to enhance intra-patch communication. The encoder employs a cascade of Patcher blocks with increasing receptive fields to extract features from local to global levels. This design allows Patcher to benefit from both the coarse-to-fine feature extraction common in CNNs and the superior spatial relationship modeling of Transformers. We also propose a new mixture-of-experts (MoE) based decoder, which treats the feature maps from the encoder as experts and selects a suitable set of expert features to predict the label for each pixel. The use of MoE enables better specializations of the expert features and reduces interference between them during inference. Extensive experiments demonstrate that Patcher outperforms state-of-the-art Transformer- and CNN-based approaches significantly on stroke lesion segmentation and polyp segmentation. Code for Patcher will be released with publication to facilitate future research.
DeepStroke: An Efficient Stroke Screening Framework for Emergency Rooms with Multimodal Adversarial Deep Learning
Sep 24, 2021
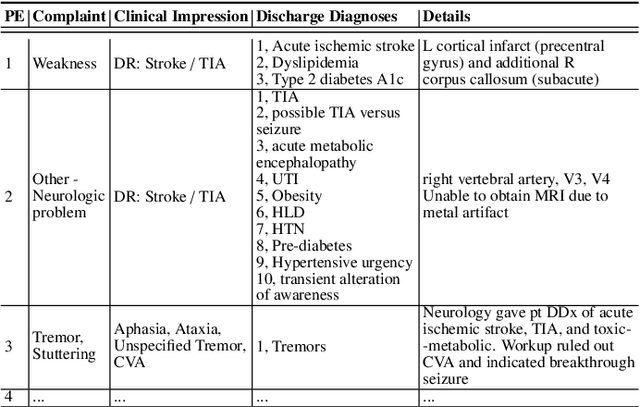
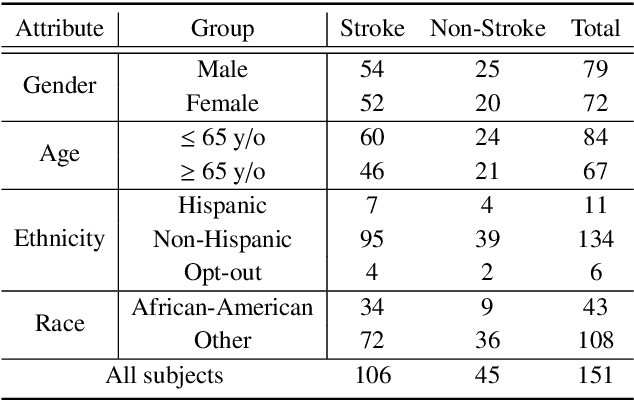
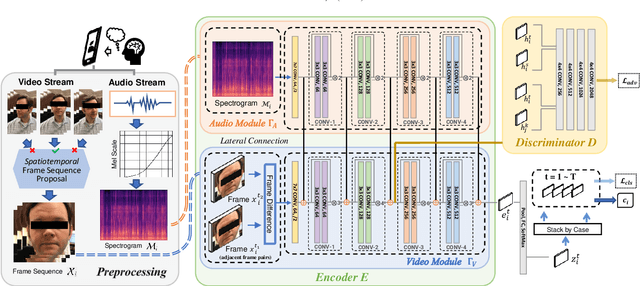
In an emergency room (ER) setting, the diagnosis of stroke is a common challenge. Due to excessive execution time and cost, an MRI scan is usually not available in the ER. Clinical tests are commonly referred to in stroke screening, but neurologists may not be immediately available. We propose a novel multimodal deep learning framework, DeepStroke, to achieve computer-aided stroke presence assessment by recognizing the patterns of facial motion incoordination and speech inability for patients with suspicion of stroke in an acute setting. Our proposed DeepStroke takes video data for local facial paralysis detection and audio data for global speech disorder analysis. It further leverages a multi-modal lateral fusion to combine the low- and high-level features and provides mutual regularization for joint training. A novel adversarial training loss is also introduced to obtain identity-independent and stroke-discriminative features. Experiments on our video-audio dataset with actual ER patients show that the proposed approach outperforms state-of-the-art models and achieves better performance than ER doctors, attaining a 6.60% higher sensitivity and maintaining 4.62% higher accuracy when specificity is aligned. Meanwhile, each assessment can be completed in less than 6 minutes, demonstrating the framework's great potential for clinical implementation.
LambdaUNet: 2.5D Stroke Lesion Segmentation of Diffusion-weighted MR Images
Apr 28, 2021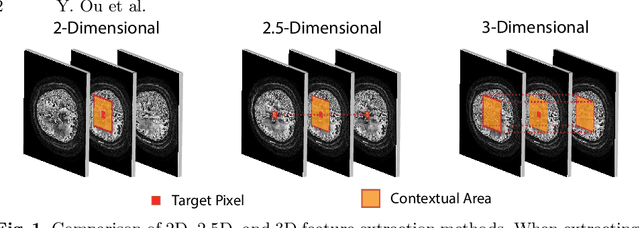
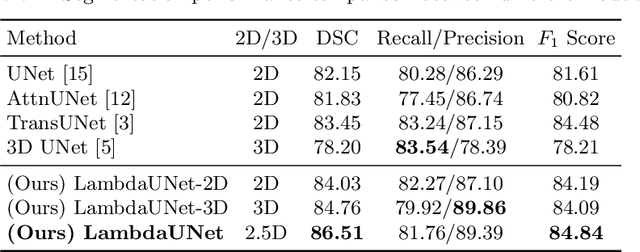


Diffusion-weighted (DW) magnetic resonance imaging is essential for the diagnosis and treatment of ischemic stroke. DW images (DWIs) are usually acquired in multi-slice settings where lesion areas in two consecutive 2D slices are highly discontinuous due to large slice thickness and sometimes even slice gaps. Therefore, although DWIs contain rich 3D information, they cannot be treated as regular 3D or 2D images. Instead, DWIs are somewhere in-between (or 2.5D) due to the volumetric nature but inter-slice discontinuities. Thus, it is not ideal to apply most existing segmentation methods as they are designed for either 2D or 3D images. To tackle this problem, we propose a new neural network architecture tailored for segmenting highly-discontinuous 2.5D data such as DWIs. Our network, termed LambdaUNet, extends UNet by replacing convolutional layers with our proposed Lambda+ layers. In particular, Lambda+ layers transform both intra-slice and inter-slice context around a pixel into linear functions, called lambdas, which are then applied to the pixel to produce informative 2.5D features. LambdaUNet is simple yet effective in combining sparse inter-slice information from adjacent slices while also capturing dense contextual features within a single slice. Experiments on a unique clinical dataset demonstrate that LambdaUNet outperforms existing 3D/2D image segmentation methods including recent variants of UNet. Code for LambdaUNet will be released with the publication to facilitate future research.