 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning A Sparse Transformer Network for Effective Image Deraining
Mar 21, 2023

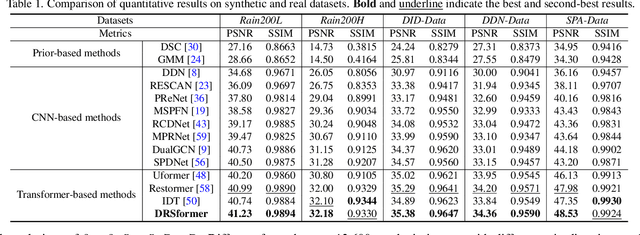
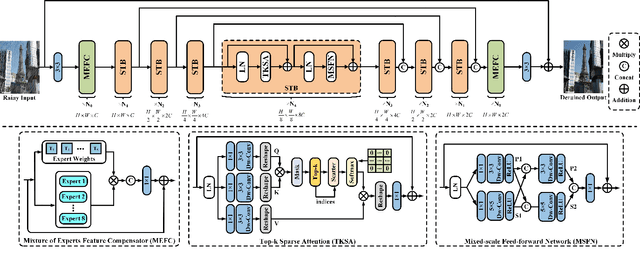

Transformers-based methods have achieved significant performance in image deraining as they can model the non-local information which is vital for high-quality image reconstruction. In this paper, we find that most existing Transformers usually use all similarities of the tokens from the query-key pairs for the feature aggregation. However, if the tokens from the query are different from those of the key, the self-attention values estimated from these tokens also involve in feature aggregation, which accordingly interferes with the clear image restoration. To overcome this problem, we propose an effective DeRaining network, Sparse Transformer (DRSformer) that can adaptively keep the most useful self-attention values for feature aggregation so that the aggregated features better facilitate high-quality image reconstruction. Specifically, we develop a learnable top-k selection operator to adaptively retain the most crucial attention scores from the keys for each query for better feature aggregation. Simultaneously, as the naive feed-forward network in Transformers does not model the multi-scale information that is important for latent clear image restoration, we develop an effective mixed-scale feed-forward network to generate better features for image deraining. To learn an enriched set of hybrid features, which combines local context from CNN operators, we equip our model with mixture of experts feature compensator to present a cooperation refinement deraining scheme. Extensive experimental results on the commonly used benchmarks demonstrate that the proposed method achieves favorable performance against state-of-the-art approaches. The source code and trained models are available at https://github.com/cschenxiang/DRSformer.
* Accepted as a highlight paper in CVPR 2023
Secure Aggregation in Federated Learning is not Private: Leaking User Data at Large Scale through Model Modification
Mar 21, 2023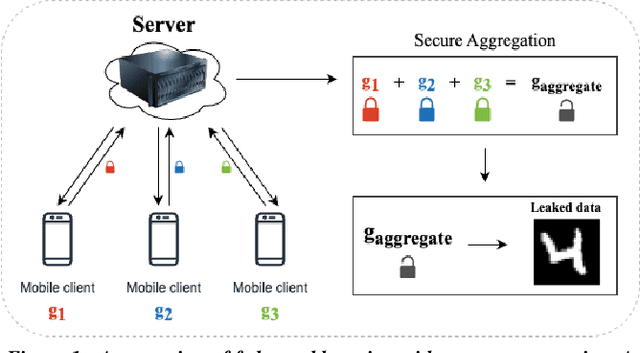
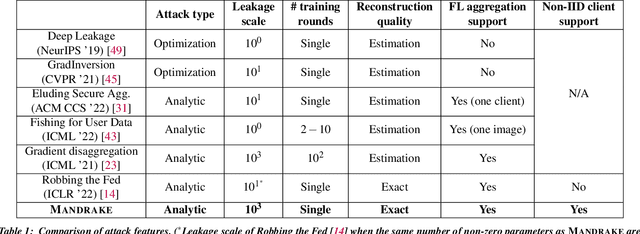
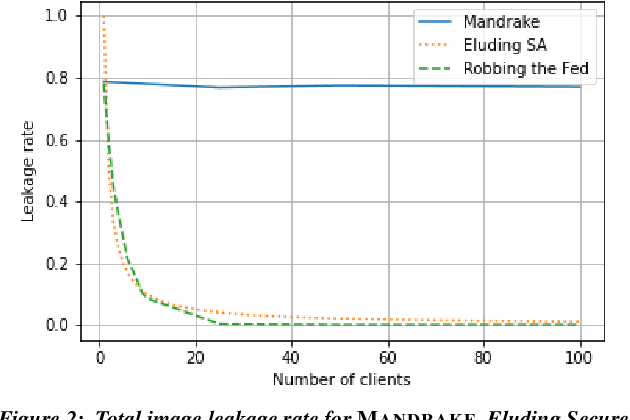
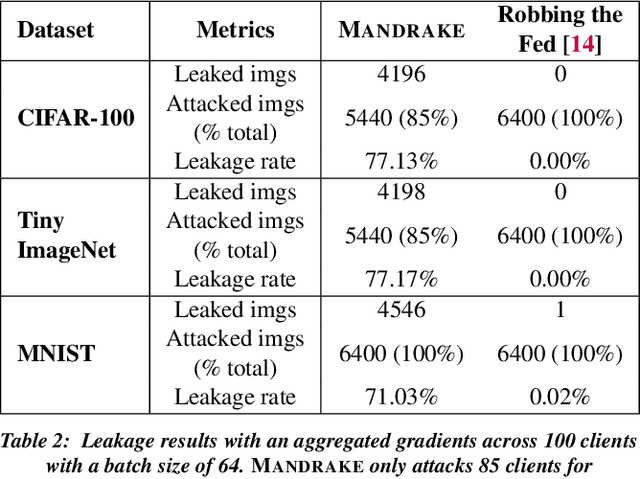
Security and privacy are important concerns in machine learning. End user devices often contain a wealth of data and this information is sensitive and should not be shared with servers or enterprises. As a result, federated learning was introduced to enable machine learning over large decentralized datasets while promising privacy by eliminating the need for data sharing. However, prior work has shown that shared gradients often contain private information and attackers can gain knowledge either through malicious modification of the architecture and parameters or by using optimization to approximate user data from the shared gradients. Despite this, most attacks have so far been limited in scale of number of clients, especially failing when client gradients are aggregated together using secure model aggregation. The attacks that still function are strongly limited in the number of clients attacked, amount of training samples they leak, or number of iterations they take to be trained. In this work, we introduce MANDRAKE, an attack that overcomes previous limitations to directly leak large amounts of client data even under secure aggregation across large numbers of clients. Furthermore, we break the anonymity of aggregation as the leaked data is identifiable and directly tied back to the clients they come from. We show that by sending clients customized convolutional parameters, the weight gradients of data points between clients will remain separate through aggregation. With an aggregation across many clients, prior work could only leak less than 1% of images. With the same number of non-zero parameters, and using only a single training iteration, MANDRAKE leaks 70-80% of data samples.
Traj-MAE: Masked Autoencoders for Trajectory Prediction
Mar 12, 2023
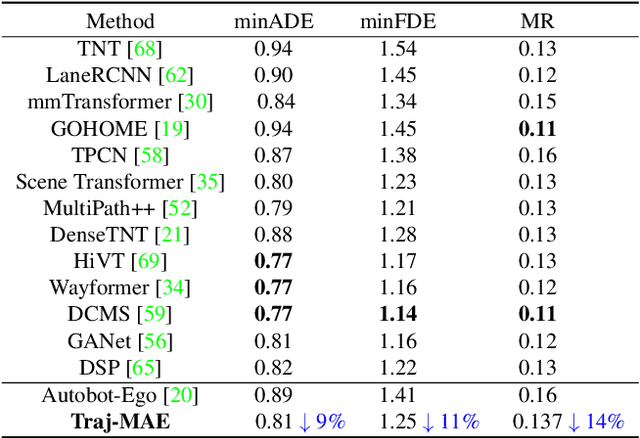
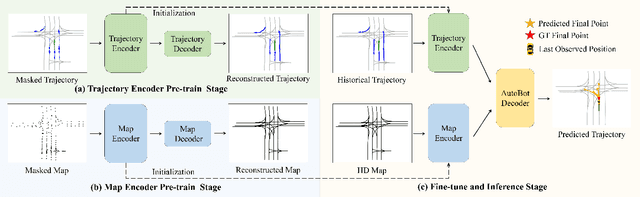
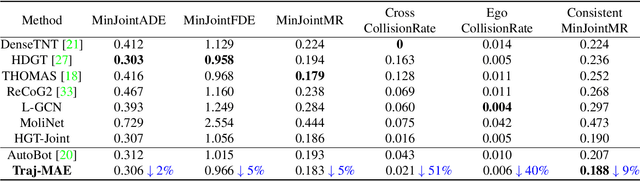
Trajectory prediction has been a crucial task in building a reliable autonomous driving system by anticipating possible dangers. One key issue is to generate consistent trajectory predictions without colliding. To overcome the challenge, we propose an efficient masked autoencoder for trajectory prediction (Traj-MAE) that better represents the complicated behaviors of agents in the driving environment. Specifically, our Traj-MAE employs diverse masking strategies to pre-train the trajectory encoder and map encoder, allowing for the capture of social and temporal information among agents while leveraging the effect of environment from multiple granularities. To address the catastrophic forgetting problem that arises when pre-training the network with multiple masking strategies, we introduce a continual pre-training framework, which can help Traj-MAE learn valuable and diverse information from various strategies efficiently. Our experimental results in both multi-agent and single-agent settings demonstrate that Traj-MAE achieves competitive results with state-of-the-art methods and significantly outperforms our baseline model.
Accommodating Audio Modality in CLIP for Multimodal Processing
Mar 12, 2023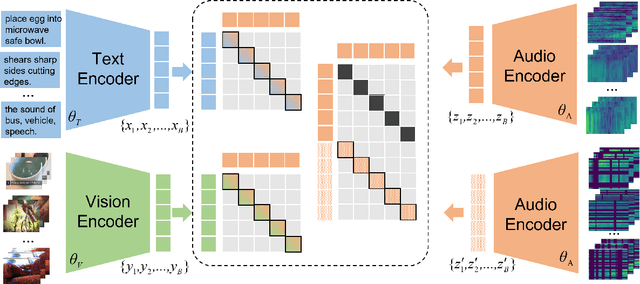
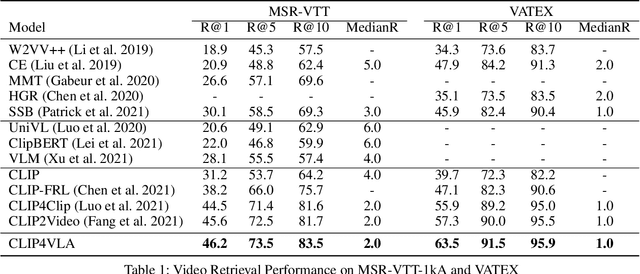
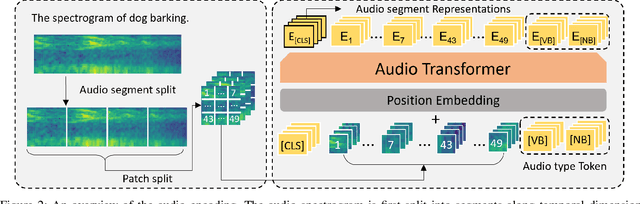
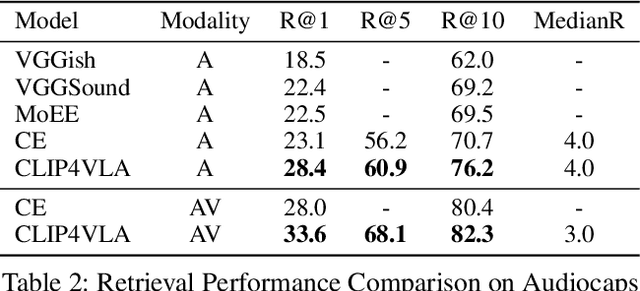
Multimodal processing has attracted much attention lately especially with the success of pre-training. However, the exploration has mainly focused on vision-language pre-training, as introducing more modalities can greatly complicate model design and optimization. In this paper, we extend the stateof-the-art Vision-Language model CLIP to accommodate the audio modality for Vision-Language-Audio multimodal processing. Specifically, we apply inter-modal and intra-modal contrastive learning to explore the correlation between audio and other modalities in addition to the inner characteristics of the audio modality. Moreover, we further design an audio type token to dynamically learn different audio information type for different scenarios, as both verbal and nonverbal heterogeneous information is conveyed in general audios. Our proposed CLIP4VLA model is validated in different downstream tasks including video retrieval and video captioning, and achieves the state-of-the-art performance on the benchmark datasets of MSR-VTT, VATEX, and Audiocaps.
Adaptive Skill Coordination for Robotic Mobile Manipulation
Apr 01, 2023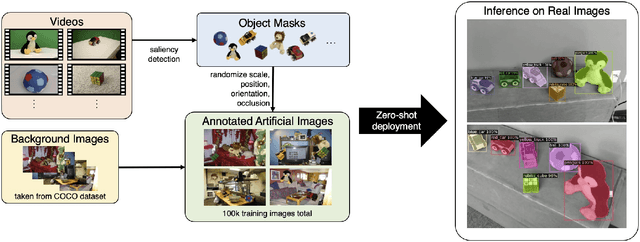
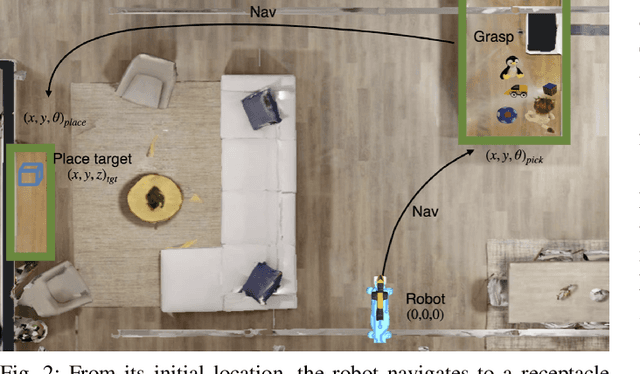
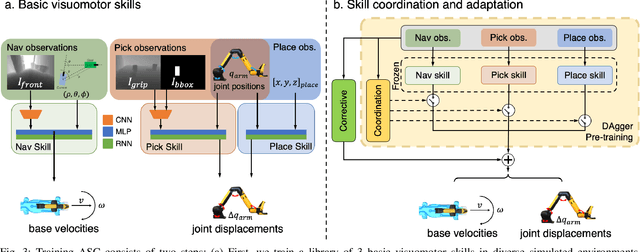

We present Adaptive Skill Coordination (ASC) - an approach for accomplishing long-horizon tasks (e.g., mobile pick-and-place, consisting of navigating to an object, picking it, navigating to another location, placing it, repeating). ASC consists of three components - (1) a library of basic visuomotor skills (navigation, pick, place), (2) a skill coordination policy that chooses which skills are appropriate to use when, and (3) a corrective policy that adapts pre-trained skills when out-of-distribution states are perceived. All components of ASC rely only on onboard visual and proprioceptive sensing, without access to privileged information like pre-built maps or precise object locations, easing real-world deployment. We train ASC in simulated indoor environments, and deploy it zero-shot in two novel real-world environments on the Boston Dynamics Spot robot. ASC achieves near-perfect performance at mobile pick-and-place, succeeding in 59/60 (98%) episodes, while sequentially executing skills succeeds in only 44/60 (73%) episodes. It is robust to hand-off errors, changes in the environment layout, dynamic obstacles (e.g., people), and unexpected disturbances, making it an ideal framework for complex, long-horizon tasks. Supplementary videos available at adaptiveskillcoordination.github.io.
Learning Continuous Control Policies for Information-Theoretic Active Perception
Sep 26, 2022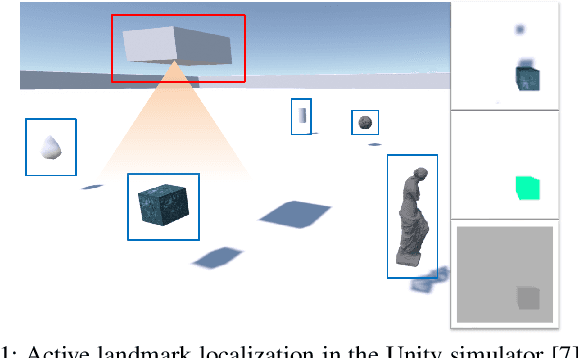
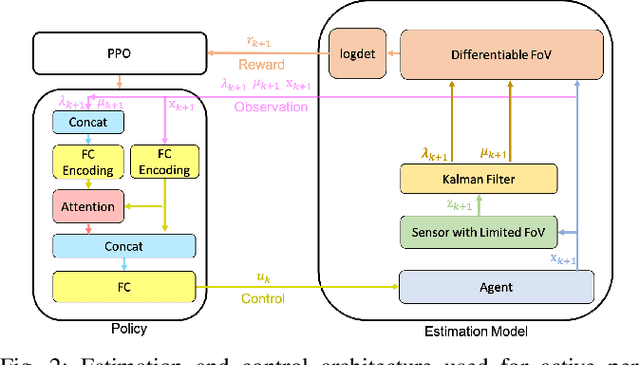
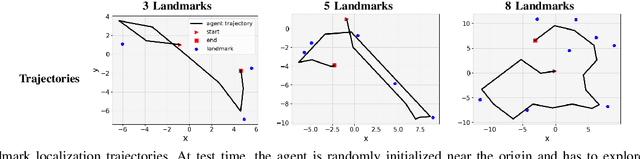
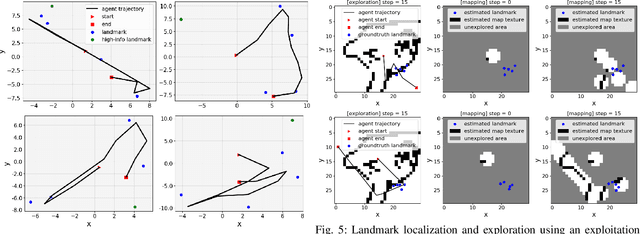
This paper proposes a method for learning continuous control policies for active landmark localization and exploration using an information-theoretic cost. We consider a mobile robot detecting landmarks within a limited sensing range, and tackle the problem of learning a control policy that maximizes the mutual information between the landmark states and the sensor observations. We employ a Kalman filter to convert the partially observable problem in the landmark state to Markov decision process (MDP), a differentiable field of view to shape the reward, and an attention-based neural network to represent the control policy. The approach is further unified with active volumetric mapping to promote exploration in addition to landmark localization. The performance is demonstrated in several simulated landmark localization tasks in comparison with benchmark methods.
LogoNet: a fine-grained network for instance-level logo sketch retrieval
Apr 05, 2023

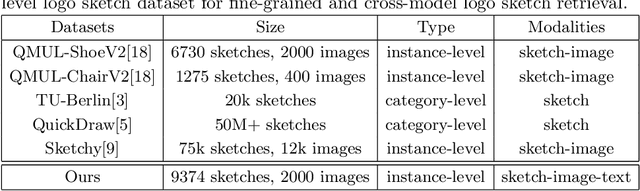
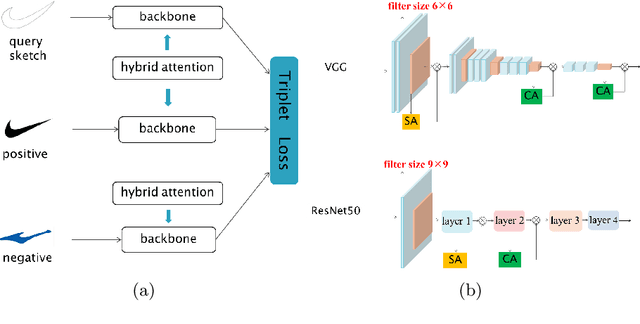
Sketch-based image retrieval, which aims to use sketches as queries to retrieve images containing the same query instance, receives increasing attention in recent years. Although dramatic progress has been made in sketch retrieval, few efforts are devoted to logo sketch retrieval which is still hindered by the following challenges: Firstly, logo sketch retrieval is more difficult than typical sketch retrieval problem, since a logo sketch usually contains much less visual contents with only irregular strokes and lines. Secondly, instance-specific sketches demonstrate dramatic appearance variances, making them less identifiable when querying the same logo instance. Thirdly, there exist several sketch retrieval benchmarking datasets nowadays, whereas an instance-level logo sketch dataset is still publicly unavailable. To address the above-mentioned limitations, we make twofold contributions in this study for instance-level logo sketch retrieval. To begin with, we construct an instance-level logo sketch dataset containing 2k logo instances and exceeding 9k sketches. To our knowledge, this is the first publicly available instance-level logo sketch dataset. Next, we develop a fine-grained triple-branch CNN architecture based on hybrid attention mechanism termed LogoNet for accurate logo sketch retrieval. More specifically, we embed the hybrid attention mechanism into the triple-branch architecture for capturing the key query-specific information from the limited visual cues in the logo sketches. Experimental evaluations both on our assembled dataset and public benchmark datasets demonstrate the effectiveness of our proposed network.
Active Teacher for Semi-Supervised Object Detection
Mar 15, 2023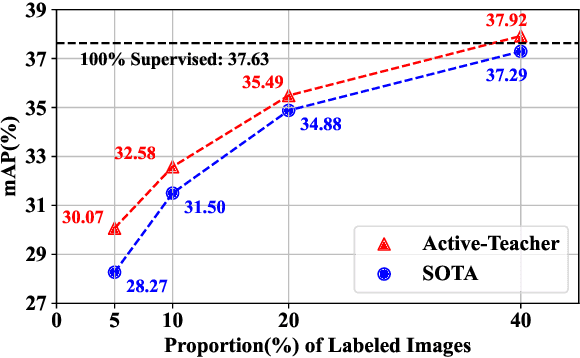
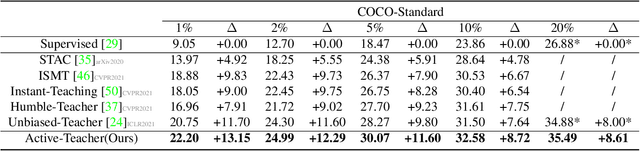
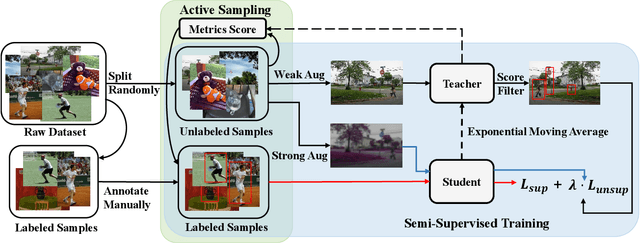
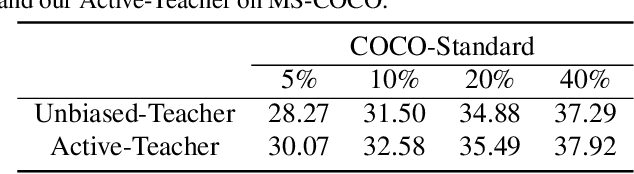
In this paper, we study teacher-student learning from the perspective of data initialization and propose a novel algorithm called Active Teacher(Source code are available at: \url{https://github.com/HunterJ-Lin/ActiveTeacher}) for semi-supervised object detection (SSOD). Active Teacher extends the teacher-student framework to an iterative version, where the label set is partially initialized and gradually augmented by evaluating three key factors of unlabeled examples, including difficulty, information and diversity. With this design, Active Teacher can maximize the effect of limited label information while improving the quality of pseudo-labels. To validate our approach, we conduct extensive experiments on the MS-COCO benchmark and compare Active Teacher with a set of recently proposed SSOD methods. The experimental results not only validate the superior performance gain of Active Teacher over the compared methods, but also show that it enables the baseline network, ie, Faster-RCNN, to achieve 100% supervised performance with much less label expenditure, ie 40% labeled examples on MS-COCO. More importantly, we believe that the experimental analyses in this paper can provide useful empirical knowledge for data annotation in practical applications.
Krylov Methods are (nearly) Optimal for Low-Rank Approximation
Apr 06, 2023
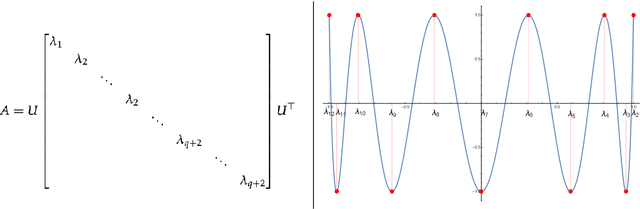
We consider the problem of rank-$1$ low-rank approximation (LRA) in the matrix-vector product model under various Schatten norms: $$ \min_{\|u\|_2=1} \|A (I - u u^\top)\|_{\mathcal{S}_p} , $$ where $\|M\|_{\mathcal{S}_p}$ denotes the $\ell_p$ norm of the singular values of $M$. Given $\varepsilon>0$, our goal is to output a unit vector $v$ such that $$ \|A(I - vv^\top)\|_{\mathcal{S}_p} \leq (1+\varepsilon) \min_{\|u\|_2=1}\|A(I - u u^\top)\|_{\mathcal{S}_p}. $$ Our main result shows that Krylov methods (nearly) achieve the information-theoretically optimal number of matrix-vector products for Spectral ($p=\infty$), Frobenius ($p=2$) and Nuclear ($p=1$) LRA. In particular, for Spectral LRA, we show that any algorithm requires $\Omega\left(\log(n)/\varepsilon^{1/2}\right)$ matrix-vector products, exactly matching the upper bound obtained by Krylov methods [MM15, BCW22]. Our lower bound addresses Open Question 1 in [Woo14], providing evidence for the lack of progress on algorithms for Spectral LRA and resolves Open Question 1.2 in [BCW22]. Next, we show that for any fixed constant $p$, i.e. $1\leq p =O(1)$, there is an upper bound of $O\left(\log(1/\varepsilon)/\varepsilon^{1/3}\right)$ matrix-vector products, implying that the complexity does not grow as a function of input size. This improves the $O\left(\log(n/\varepsilon)/\varepsilon^{1/3}\right)$ bound recently obtained in [BCW22], and matches their $\Omega\left(1/\varepsilon^{1/3}\right)$ lower bound, to a $\log(1/\varepsilon)$ factor.
coExplore: Combining multiple rankings for multi-robot exploration
Mar 30, 2023

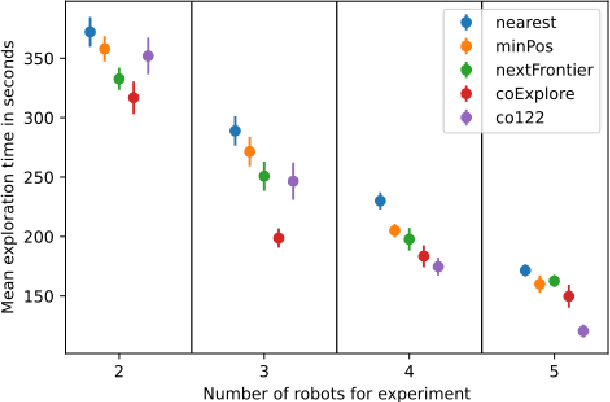
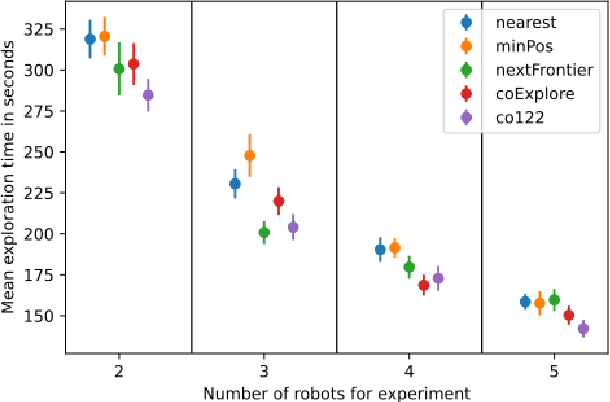
Multi-robot exploration is a field which tackles the challenge of exploring a previously unknown environment with a number of robots. This is especially relevant for search and rescue operations where time is essential. Current state of the art approaches are able to explore a given environment with a large number of robots by assigning them to frontiers. However, this assignment generally favors large frontiers and hence omits potentially valuable medium-sized frontiers. In this paper we showcase a novel multi-robot exploration algorithm, which improves and adapts the existing approaches. Through the addition of information gain based ranking we improve the exploration time for closed urban environments while maintaining similar exploration performance compared to the state-of-the-art for open environments. Accompanying this paper, we further publish our research code in order to lower the barrier to entry for further multi-robot exploration research. We evaluate the performance in three simulated scenarios, two urban and one open scenario, where our algorithm outperforms the state of the art by 5\% overall.