 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Neural Robot Dynamics on the Fly for Predictive Control
Apr 05, 2026Accurate dynamics models are critical for the design of predictive controller for autonomous mobile robots. Physics-based models are often too simple to capture relevant real-world effects, while data-driven models are data-intensive and slow to train. We introduce an approach for fast adaptation of neural robot dynamic models that combines offline training with efficient online updates. Our approach learns an incremental neural dynamics model offline and performs low-rank second-order parameter adaptation online, enabling rapid updates without full retraining. We demonstrate the approach on a real quadrotor robot, achieving robust predictive tracking control in novel operational conditions.
Kernel-SDF: An Open-Source Library for Real-Time Signed Distance Function Estimation using Kernel Regression
Mar 31, 2026Accurate and efficient environment representation is crucial for robotic applications such as motion planning, manipulation, and navigation. Signed distance functions (SDFs) have emerged as a powerful representation for encoding distance to obstacle boundaries, enabling efficient collision-checking and trajectory optimization techniques. However, existing SDF reconstruction methods have limitations when it comes to large-scale uncertainty-aware SDF estimation from streaming sensor data. Voxel-based approaches are limited by fixed resolution and lack uncertainty quantification, neural network methods require significant training time, while Gaussian process (GP) methods struggle with scalability, sign estimation, and uncertainty calibration. In this letter, we develop an open-source library, Kernel-SDF, which uses kernel regression to learn SDF with calibrated uncertainty quantification in real-time. Our approach consists of a front-end that learns a continuous occupancy field via kernel regression, and a back-end that estimates accurate SDF via GP regression using samples from the front-end surface boundaries. Kernel-SDF provides accurate SDF, SDF gradient, SDF uncertainty, and mesh construction in real-time. Evaluation results show that Kernel-SDF achieves superior accuracy compared to existing methods, while maintaining real-time performance, making it suitable for various robotics applications requiring reliable uncertainty-aware geometric information.
Rainbow-DemoRL: Combining Improvements in Demonstration-Augmented Reinforcement Learning
Mar 28, 2026Several approaches have been proposed to improve the sample efficiency of online reinforcement learning (RL) by leveraging demonstrations collected offline. The offline data can be used directly as transitions to optimize RL objectives, or offline policy and value functions can first be learned from the data and then used for online finetuning or to provide reference actions. While each of these strategies has shown compelling results, it is unclear which method has the most impact on sample efficiency, whether these approaches can be combined, and if there are cumulative benefits. We classify existing demonstration-augmented RL approaches into three categories and perform an extensive empirical study of their strengths, weaknesses, and combinations to isolate the contribution of each strategy and determine effective hybrid combinations for sample-efficient online RL. Our analysis reveals that directly reusing offline data and initializing with behavior cloning consistently outperform more complex offline RL pretraining methods for improving online sample efficiency.
PhysGraph: Physically-Grounded Graph-Transformer Policies for Bimanual Dexterous Hand-Tool-Object Manipulation
Mar 02, 2026Bimanual dexterous manipulation for tool use remains a formidable challenge in robotics due to the high-dimensional state space and complicated contact dynamics. Existing methods naively represent the entire system state as a single configuration vector, disregarding the rich structural and topological information inherent to articulated hands. We present PhysGraph, a physically-grounded graph transformer policy designed explicitly for challenging bimanual hand-tool-object manipulation. Unlike prior works, we represent the bimanual system as a kinematic graph and introduce per-link tokenization to preserve fine-grained local state information. We propose a physically-grounded bias generator that injects structural priors directly into the attention mechanism, including kinematic spatial distance, dynamic contact states, geometric proximity, and anatomical properties. This allows the policy to explicitly reason about physical interactions rather than learning them implicitly from sparse rewards. Extensive experiments show that PhysGraph significantly outperforms baseline - ManipTrans in manipulation precision and task success rates while using only 51% of the parameters of ManipTrans. Furthermore, the inherent topological flexibility of our architecture shows qualitative zero-shot transfer to unseen tool/object geometries, and is sufficiently general to be trained on three robotic hands (Shadow, Allegro, Inspire).
MATT-Diff: Multimodal Active Target Tracking by Diffusion Policy
Nov 14, 2025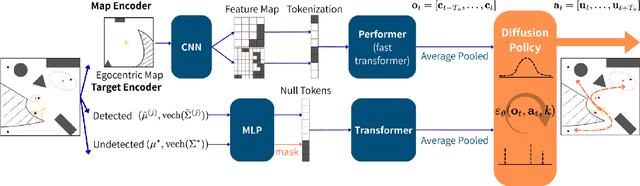
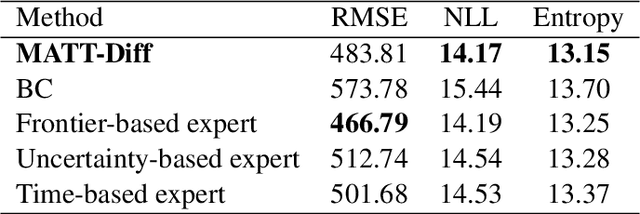
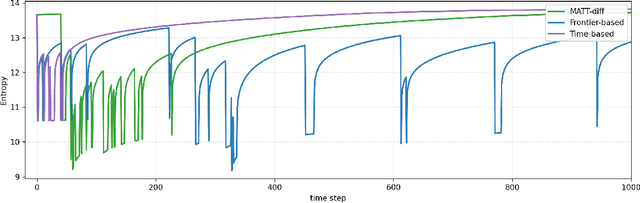
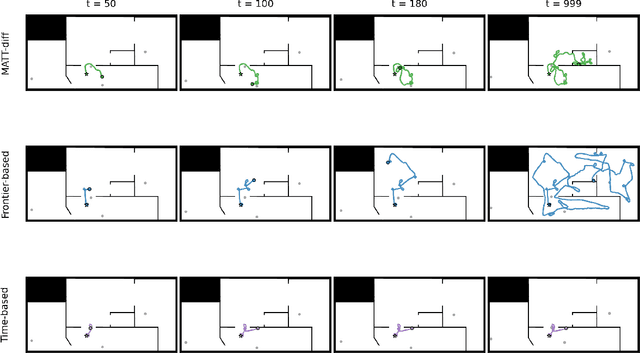
This paper proposes MATT-Diff: Multi-Modal Active Target Tracking by Diffusion Policy, a control policy that captures multiple behavioral modes - exploration, dedicated tracking, and target reacquisition - for active multi-target tracking. The policy enables agent control without prior knowledge of target numbers, states, or dynamics. Effective target tracking demands balancing exploration for undetected or lost targets with following the motion of detected but uncertain ones. We generate a demonstration dataset from three expert planners including frontier-based exploration, an uncertainty-based hybrid planner switching between frontier-based exploration and RRT* tracking based on target uncertainty, and a time-based hybrid planner switching between exploration and tracking based on target detection time. We design a control policy utilizing a vision transformer for egocentric map tokenization and an attention mechanism to integrate variable target estimates represented by Gaussian densities. Trained as a diffusion model, the policy learns to generate multi-modal action sequences through a denoising process. Evaluations demonstrate MATT-Diff's superior tracking performance against expert and behavior cloning baselines across multiple target motions, empirically validating its advantages in target tracking.
A Shared-Autonomy Construction Robotic System for Overhead Works
Nov 12, 2025We present the ongoing development of a robotic system for overhead work such as ceiling drilling. The hardware platform comprises a mobile base with a two-stage lift, on which a bimanual torso is mounted with a custom-designed drilling end effector and RGB-D cameras. To support teleoperation in dynamic environments with limited visibility, we use Gaussian splatting for online 3D reconstruction and introduce motion parameters to model moving objects. For safe operation around dynamic obstacles, we developed a neural configuration-space barrier approach for planning and control. Initial feasibility studies demonstrate the capability of the hardware in drilling, bolting, and anchoring, and the software in safe teleoperation in a dynamic environment.
$ abla$-SDF: Learning Euclidean Signed Distance Functions Online with Gradient-Augmented Octree Interpolation and Neural Residual
Oct 21, 2025



Estimation of signed distance functions (SDFs) from point cloud data has been shown to benefit many robot autonomy capabilities, including localization, mapping, motion planning, and control. Methods that support online and large-scale SDF reconstruction tend to rely on discrete volumetric data structures, which affect the continuity and differentiability of the SDF estimates. Recently, using implicit features, neural network methods have demonstrated high-fidelity and differentiable SDF reconstruction but they tend to be less efficient, can experience catastrophic forgetting and memory limitations in large environments, and are often restricted to truncated SDFs. This work proposes $\nabla$-SDF, a hybrid method that combines an explicit prior obtained from gradient-augmented octree interpolation with an implicit neural residual. Our method achieves non-truncated (Euclidean) SDF reconstruction with computational and memory efficiency comparable to volumetric methods and differentiability and accuracy comparable to neural network methods. Extensive experiments demonstrate that \methodname{} outperforms the state of the art in terms of accuracy and efficiency, providing a scalable solution for downstream tasks in robotics and computer vision.
Certifying Stability of Reinforcement Learning Policies using Generalized Lyapunov Functions
May 19, 2025We study the problem of certifying the stability of closed-loop systems under control policies derived from optimal control or reinforcement learning (RL). Classical Lyapunov methods require a strict step-wise decrease in the Lyapunov function but such a certificate is difficult to construct for a learned control policy. The value function associated with an RL policy is a natural Lyapunov function candidate but it is not clear how it should be modified. To gain intuition, we first study the linear quadratic regulator (LQR) problem and make two key observations. First, a Lyapunov function can be obtained from the value function of an LQR policy by augmenting it with a residual term related to the system dynamics and stage cost. Second, the classical Lyapunov decrease requirement can be relaxed to a generalized Lyapunov condition requiring only decrease on average over multiple time steps. Using this intuition, we consider the nonlinear setting and formulate an approach to learn generalized Lyapunov functions by augmenting RL value functions with neural network residual terms. Our approach successfully certifies the stability of RL policies trained on Gymnasium and DeepMind Control benchmarks. We also extend our method to jointly train neural controllers and stability certificates using a multi-step Lyapunov loss, resulting in larger certified inner approximations of the region of attraction compared to the classical Lyapunov approach. Overall, our formulation enables stability certification for a broad class of systems with learned policies by making certificates easier to construct, thereby bridging classical control theory and modern learning-based methods.
Learned IMU Bias Prediction for Invariant Visual Inertial Odometry
May 10, 2025Autonomous mobile robots operating in novel environments depend critically on accurate state estimation, often utilizing visual and inertial measurements. Recent work has shown that an invariant formulation of the extended Kalman filter improves the convergence and robustness of visual-inertial odometry by utilizing the Lie group structure of a robot's position, velocity, and orientation states. However, inertial sensors also require measurement bias estimation, yet introducing the bias in the filter state breaks the Lie group symmetry. In this paper, we design a neural network to predict the bias of an inertial measurement unit (IMU) from a sequence of previous IMU measurements. This allows us to use an invariant filter for visual inertial odometry, relying on the learned bias prediction rather than introducing the bias in the filter state. We demonstrate that an invariant multi-state constraint Kalman filter (MSCKF) with learned bias predictions achieves robust visual-inertial odometry in real experiments, even when visual information is unavailable for extended periods and the system needs to rely solely on IMU measurements.
Variational Formulation of the Particle Flow Particle Filter
May 06, 2025



This paper provides a formulation of the particle flow particle filter from the perspective of variational inference. We show that the transient density used to derive the particle flow particle filter follows a time-scaled trajectory of the Fisher-Rao gradient flow in the space of probability densities. The Fisher-Rao gradient flow is obtained as a continuous-time algorithm for variational inference, minimizing the Kullback-Leibler divergence between a variational density and the true posterior density.