 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Corner Patches: Semantics-Aware Backdoor Attack in Federated Learning
Mar 31, 2026Backdoor attacks on federated learning (FL) are most often evaluated with synthetic corner patches or out-of-distribution (OOD) patterns that are unlikely to arise in practice. In this paper, we revisit the backdoor threat to standard FL (a single global model) under a more realistic setting where triggers must be semantically meaningful, in-distribution, and visually plausible. We propose SABLE, a Semantics-Aware Backdoor for LEarning in federated settings, which constructs natural, content-consistent triggers (e.g., semantic attribute changes such as sunglasses) and optimizes an aggregation-aware malicious objective with feature separation and parameter regularization to keep attacker updates close to benign ones. We instantiate SABLE on CelebA hair-color classification and the German Traffic Sign Recognition Benchmark (GTSRB), poisoning only a small, interpretable subset of each malicious client's local data while otherwise following the standard FL protocol. Across heterogeneous client partitions and multiple aggregation rules (FedAvg, Trimmed Mean, MultiKrum, and FLAME), our semantics-driven triggers achieve high targeted attack success rates while preserving benign test accuracy. These results show that semantics-aligned backdoors remain a potent and practical threat in federated learning, and that robustness claims based solely on synthetic patch triggers can be overly optimistic.
Ascendra: Dynamic Request Prioritization for Efficient LLM Serving
Apr 30, 2025The rapid advancement of Large Language Models (LLMs) has driven the need for more efficient serving strategies. In this context, efficiency refers to the proportion of requests that meet their Service Level Objectives (SLOs), particularly for Time To First Token (TTFT) and Time Between Tokens (TBT). However, existing systems often prioritize one metric at the cost of the other. We present Ascendra, an LLM serving system designed to meet both TTFT and TBT SLOs simultaneously. The core insight behind Ascendra is that a request's urgency evolves as it approaches its deadline. To leverage this, Ascendra partitions GPU resources into two types of instances: low-priority and high-priority. Low-priority instances maximize throughput by processing requests out of arrival order, but at the risk of request starvation. To address this, Ascendra employs a performance model to predict requests at risk of missing their SLOs and proactively offloads them to high-priority instances. High-priority instances are optimized for low-latency execution and handle urgent requests nearing their deadlines. This partitioned architecture enables Ascendra to effectively balance high throughput and low latency. Extensive evaluation shows that Ascendra improves system throughput by up to 1.7x compared to vLLM and Sarathi-Serve while meeting both TTFT and TBT SLOs.
Hubs and Spokes Learning: Efficient and Scalable Collaborative Machine Learning
Apr 29, 2025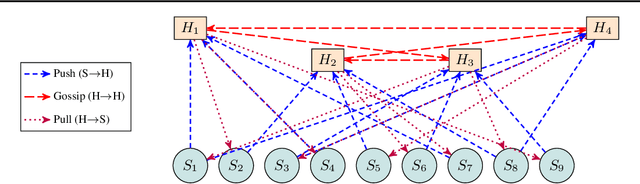
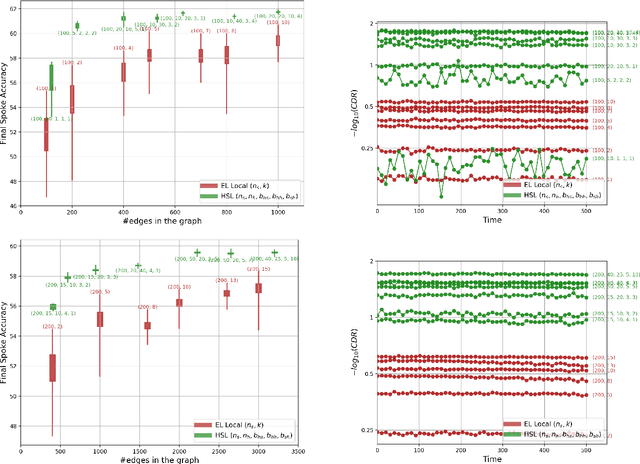
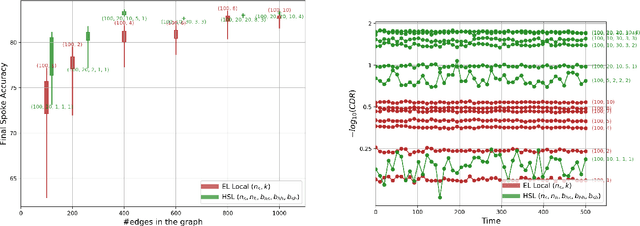
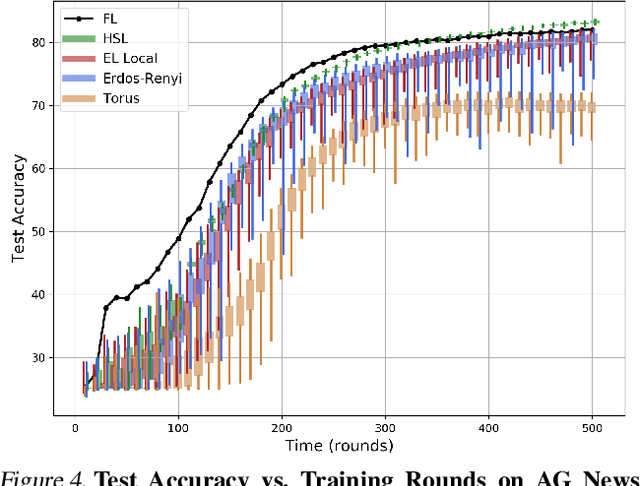
We introduce the Hubs and Spokes Learning (HSL) framework, a novel paradigm for collaborative machine learning that combines the strengths of Federated Learning (FL) and Decentralized Learning (P2PL). HSL employs a two-tier communication structure that avoids the single point of failure inherent in FL and outperforms the state-of-the-art P2PL framework, Epidemic Learning Local (ELL). At equal communication budgets (total edges), HSL achieves higher performance than ELL, while at significantly lower communication budgets, it can match ELL's performance. For instance, with only 400 edges, HSL reaches the same test accuracy that ELL achieves with 1000 edges for 100 peers (spokes) on CIFAR-10, demonstrating its suitability for resource-constrained systems. HSL also achieves stronger consensus among nodes after mixing, resulting in improved performance with fewer training rounds. We substantiate these claims through rigorous theoretical analyses and extensive experimental results, showcasing HSL's practicality for large-scale collaborative learning.
Learning to Inference Adaptively for Multimodal Large Language Models
Mar 13, 2025
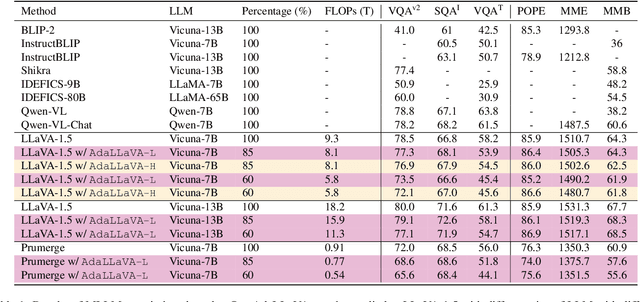
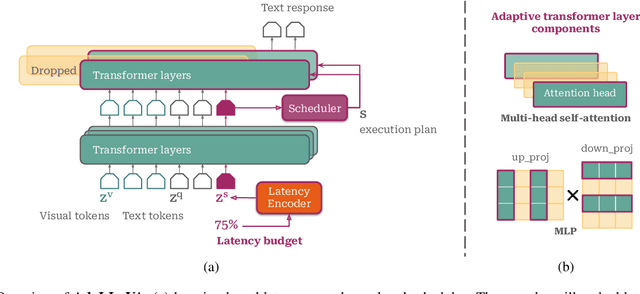
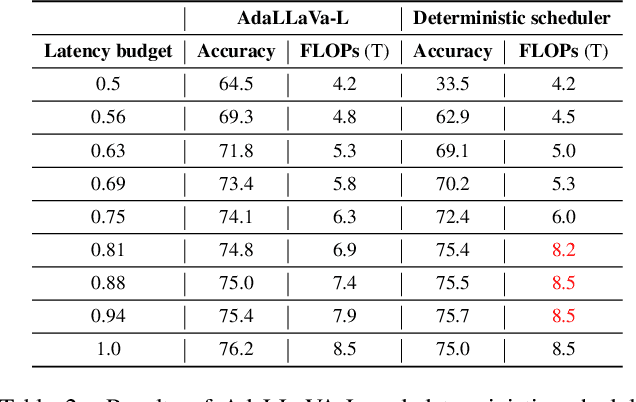
Multimodal Large Language Models (MLLMs) have shown impressive capabilities in reasoning, yet come with substantial computational cost, limiting their deployment in resource-constrained settings. Despite recent efforts on improving the efficiency of MLLMs, prior solutions fall short in responding to varying runtime conditions, in particular changing resource availability (e.g., contention due to the execution of other programs on the device). To bridge this gap, we introduce AdaLLaVA, an adaptive inference framework that learns to dynamically reconfigure operations in an MLLM during inference, accounting for the input data and a latency budget. We conduct extensive experiments across benchmarks involving question-answering, reasoning, and hallucination. Our results show that AdaLLaVA effectively adheres to input latency budget, achieving varying accuracy and latency tradeoffs at runtime. Further, we demonstrate that AdaLLaVA adapts to both input latency and content, can be integrated with token selection for enhanced efficiency, and generalizes across MLLMs.Our project webpage with code release is at https://zhuoyan-xu.github.io/ada-llava/.
HopTrack: A Real-time Multi-Object Tracking System for Embedded Devices
Nov 01, 2024



Multi-Object Tracking (MOT) poses significant challenges in computer vision. Despite its wide application in robotics, autonomous driving, and smart manufacturing, there is limited literature addressing the specific challenges of running MOT on embedded devices. State-of-the-art MOT trackers designed for high-end GPUs often experience low processing rates (<11fps) when deployed on embedded devices. Existing MOT frameworks for embedded devices proposed strategies such as fusing the detector model with the feature embedding model to reduce inference latency or combining different trackers to improve tracking accuracy, but tend to compromise one for the other. This paper introduces HopTrack, a real-time multi-object tracking system tailored for embedded devices. Our system employs a novel discretized static and dynamic matching approach along with an innovative content-aware dynamic sampling technique to enhance tracking accuracy while meeting the real-time requirement. Compared with the best high-end GPU modified baseline Byte (Embed) and the best existing baseline on embedded devices MobileNet-JDE, HopTrack achieves a processing speed of up to 39.29 fps on NVIDIA AGX Xavier with a multi-object tracking accuracy (MOTA) of up to 63.12% on the MOT16 benchmark, outperforming both counterparts by 2.15% and 4.82%, respectively. Additionally, the accuracy improvement is coupled with the reduction in energy consumption (20.8%), power (5%), and memory usage (8%), which are crucial resources on embedded devices. HopTrack is also detector agnostic allowing the flexibility of plug-and-play.
Federated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape - A Survey
May 06, 2024Deep learning has shown incredible potential across a vast array of tasks and accompanying this growth has been an insatiable appetite for data. However, a large amount of data needed for enabling deep learning is stored on personal devices and recent concerns on privacy have further highlighted challenges for accessing such data. As a result, federated learning (FL) has emerged as an important privacy-preserving technology enabling collaborative training of machine learning models without the need to send the raw, potentially sensitive, data to a central server. However, the fundamental premise that sending model updates to a server is privacy-preserving only holds if the updates cannot be "reverse engineered" to infer information about the private training data. It has been shown under a wide variety of settings that this premise for privacy does {\em not} hold. In this survey paper, we provide a comprehensive literature review of the different privacy attacks and defense methods in FL. We identify the current limitations of these attacks and highlight the settings in which FL client privacy can be broken. We dissect some of the successful industry applications of FL and draw lessons for future successful adoption. We survey the emerging landscape of privacy regulation for FL. We conclude with future directions for taking FL toward the cherished goal of generating accurate models while preserving the privacy of the data from its participants.
Leak and Learn: An Attacker's Cookbook to Train Using Leaked Data from Federated Learning
Mar 26, 2024



Federated learning is a decentralized learning paradigm introduced to preserve privacy of client data. Despite this, prior work has shown that an attacker at the server can still reconstruct the private training data using only the client updates. These attacks are known as data reconstruction attacks and fall into two major categories: gradient inversion (GI) and linear layer leakage attacks (LLL). However, despite demonstrating the effectiveness of these attacks in breaching privacy, prior work has not investigated the usefulness of the reconstructed data for downstream tasks. In this work, we explore data reconstruction attacks through the lens of training and improving models with leaked data. We demonstrate the effectiveness of both GI and LLL attacks in maliciously training models using the leaked data more accurately than a benign federated learning strategy. Counter-intuitively, this bump in training quality can occur despite limited reconstruction quality or a small total number of leaked images. Finally, we show the limitations of these attacks for downstream training, individually for GI attacks and for LLL attacks.
Benchmarking Algorithms for Federated Domain Generalization
Jul 11, 2023



While prior domain generalization (DG) benchmarks consider train-test dataset heterogeneity, we evaluate Federated DG which introduces federated learning (FL) specific challenges. Additionally, we explore domain-based heterogeneity in clients' local datasets - a realistic Federated DG scenario. Prior Federated DG evaluations are limited in terms of the number or heterogeneity of clients and dataset diversity. To address this gap, we propose an Federated DG benchmark methodology that enables control of the number and heterogeneity of clients and provides metrics for dataset difficulty. We then apply our methodology to evaluate 13 Federated DG methods, which include centralized DG methods adapted to the FL context, FL methods that handle client heterogeneity, and methods designed specifically for Federated DG. Our results suggest that despite some progress, there remain significant performance gaps in Federated DG particularly when evaluating with a large number of clients, high client heterogeneity, or more realistic datasets. Please check our extendable benchmark code here: https://github.com/inouye-lab/FedDG_Benchmark.
The Resource Problem of Using Linear Layer Leakage Attack in Federated Learning
Mar 27, 2023



Secure aggregation promises a heightened level of privacy in federated learning, maintaining that a server only has access to a decrypted aggregate update. Within this setting, linear layer leakage methods are the only data reconstruction attacks able to scale and achieve a high leakage rate regardless of the number of clients or batch size. This is done through increasing the size of an injected fully-connected (FC) layer. However, this results in a resource overhead which grows larger with an increasing number of clients. We show that this resource overhead is caused by an incorrect perspective in all prior work that treats an attack on an aggregate update in the same way as an individual update with a larger batch size. Instead, by attacking the update from the perspective that aggregation is combining multiple individual updates, this allows the application of sparsity to alleviate resource overhead. We show that the use of sparsity can decrease the model size overhead by over 327$\times$ and the computation time by 3.34$\times$ compared to SOTA while maintaining equivalent total leakage rate, 77% even with $1000$ clients in aggregation.
Secure Aggregation in Federated Learning is not Private: Leaking User Data at Large Scale through Model Modification
Mar 21, 2023



Security and privacy are important concerns in machine learning. End user devices often contain a wealth of data and this information is sensitive and should not be shared with servers or enterprises. As a result, federated learning was introduced to enable machine learning over large decentralized datasets while promising privacy by eliminating the need for data sharing. However, prior work has shown that shared gradients often contain private information and attackers can gain knowledge either through malicious modification of the architecture and parameters or by using optimization to approximate user data from the shared gradients. Despite this, most attacks have so far been limited in scale of number of clients, especially failing when client gradients are aggregated together using secure model aggregation. The attacks that still function are strongly limited in the number of clients attacked, amount of training samples they leak, or number of iterations they take to be trained. In this work, we introduce MANDRAKE, an attack that overcomes previous limitations to directly leak large amounts of client data even under secure aggregation across large numbers of clients. Furthermore, we break the anonymity of aggregation as the leaked data is identifiable and directly tied back to the clients they come from. We show that by sending clients customized convolutional parameters, the weight gradients of data points between clients will remain separate through aggregation. With an aggregation across many clients, prior work could only leak less than 1% of images. With the same number of non-zero parameters, and using only a single training iteration, MANDRAKE leaks 70-80% of data samples.