 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Code-Switching with Word Senses for Pretraining in Neural Machine Translation
Oct 21, 2023
Lexical ambiguity is a significant and pervasive challenge in Neural Machine Translation (NMT), with many state-of-the-art (SOTA) NMT systems struggling to handle polysemous words (Campolungo et al., 2022). The same holds for the NMT pretraining paradigm of denoising synthetic "code-switched" text (Pan et al., 2021; Iyer et al., 2023), where word senses are ignored in the noising stage -- leading to harmful sense biases in the pretraining data that are subsequently inherited by the resulting models. In this work, we introduce Word Sense Pretraining for Neural Machine Translation (WSP-NMT) - an end-to-end approach for pretraining multilingual NMT models leveraging word sense-specific information from Knowledge Bases. Our experiments show significant improvements in overall translation quality. Then, we show the robustness of our approach to scale to various challenging data and resource-scarce scenarios and, finally, report fine-grained accuracy improvements on the DiBiMT disambiguation benchmark. Our studies yield interesting and novel insights into the merits and challenges of integrating word sense information and structured knowledge in multilingual pretraining for NMT.
Visual Grounding Helps Learn Word Meanings in Low-Data Regimes
Oct 20, 2023Modern neural language models (LMs) are powerful tools for modeling human sentence production and comprehension, and their internal representations are remarkably well-aligned with representations of language in the human brain. But to achieve these results, LMs must be trained in distinctly un-human-like ways -- requiring orders of magnitude more language data than children receive during development, and without any of the accompanying grounding in perception, action, or social behavior. Do models trained more naturalistically -- with grounded supervision -- exhibit more human-like language learning? We investigate this question in the context of word learning, a key sub-task in language acquisition. We train a diverse set of LM architectures, with and without auxiliary supervision from image captioning tasks, on datasets of varying scales. We then evaluate these models on a broad set of benchmarks characterizing models' learning of syntactic categories, lexical relations, semantic features, semantic similarity, and alignment with human neural representations. We find that visual supervision can indeed improve the efficiency of word learning. However, these improvements are limited: they are present almost exclusively in the low-data regime, and sometimes canceled out by the inclusion of rich distributional signals from text. The information conveyed by text and images is not redundant -- we find that models mainly driven by visual information yield qualitatively different from those mainly driven by word co-occurrences. However, our results suggest that current multi-modal modeling approaches fail to effectively leverage visual information to build more human-like word representations from human-sized datasets.
FLEEK: Factual Error Detection and Correction with Evidence Retrieved from External Knowledge
Oct 26, 2023
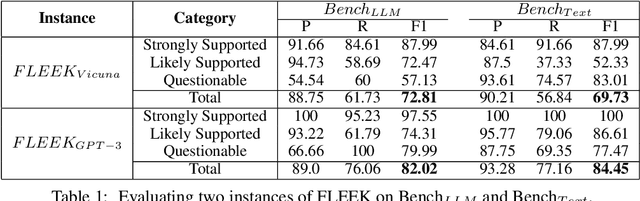
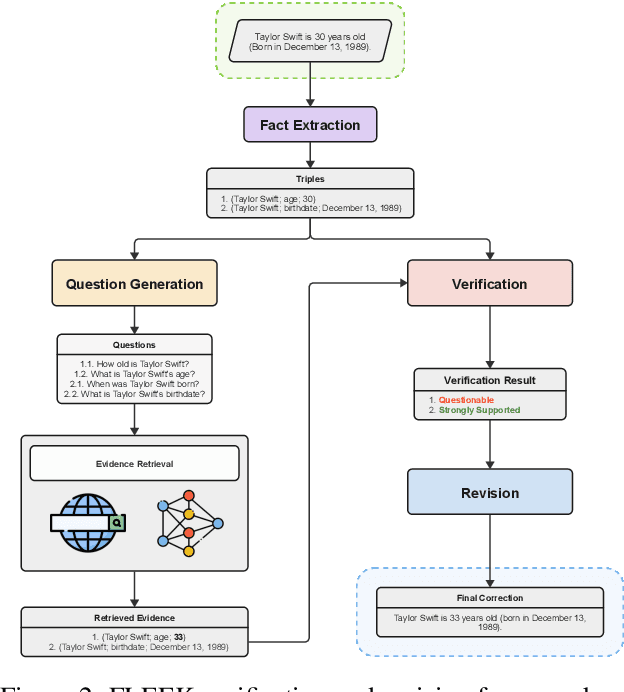
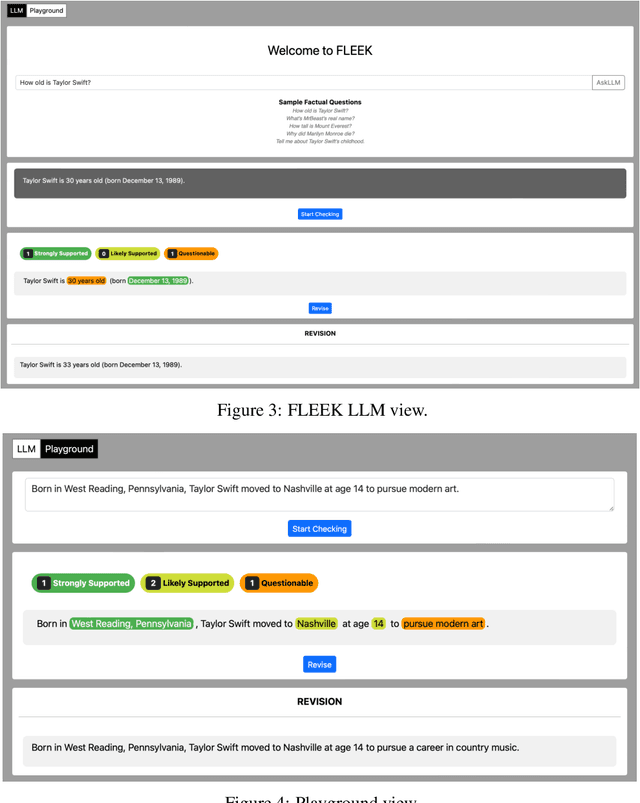
Detecting factual errors in textual information, whether generated by large language models (LLM) or curated by humans, is crucial for making informed decisions. LLMs' inability to attribute their claims to external knowledge and their tendency to hallucinate makes it difficult to rely on their responses. Humans, too, are prone to factual errors in their writing. Since manual detection and correction of factual errors is labor-intensive, developing an automatic approach can greatly reduce human effort. We present FLEEK, a prototype tool that automatically extracts factual claims from text, gathers evidence from external knowledge sources, evaluates the factuality of each claim, and suggests revisions for identified errors using the collected evidence. Initial empirical evaluation on fact error detection (77-85\% F1) shows the potential of FLEEK. A video demo of FLEEK can be found at https://youtu.be/NapJFUlkPdQ.
Bridging Phylogeny and Taxonomy with Protein-protein Interaction Networks
Oct 26, 2023The protein-protein interaction (PPI) network provides an overview of the complex biological reactions vital to an organism's metabolism and survival. Even though in the past PPI network were compared across organisms in detail, there has not been large-scale research on how individual PPI networks reflect on the species relationships. In this study we aim to increase our understanding of the tree of life and taxonomy by gleaming information from the PPI networks. We successful created (1) a predictor of network statistics based on known traits of existing species in the phylogeny, and (2) a taxonomic classifier of organism using the known protein network statistics, whether experimentally determined or predicted de novo. With the knowledge of protein interactions at its core, our two models effectively connects two field with widely diverging methodologies - the phylogeny and taxonomy of species.
Contrast Everything: A Hierarchical Contrastive Framework for Medical Time-Series
Oct 28, 2023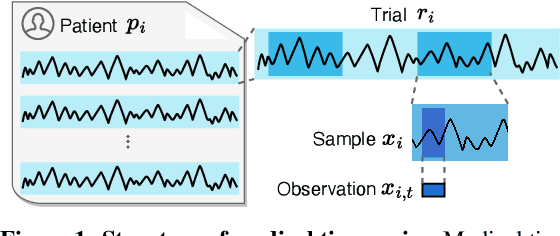

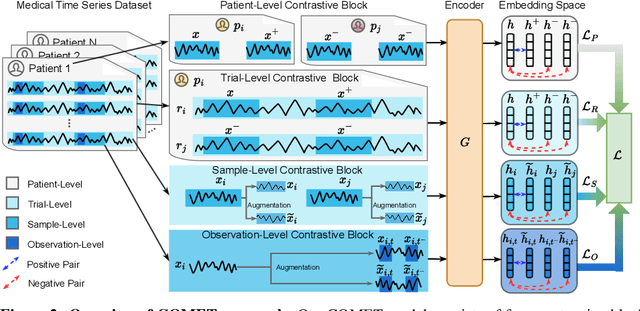
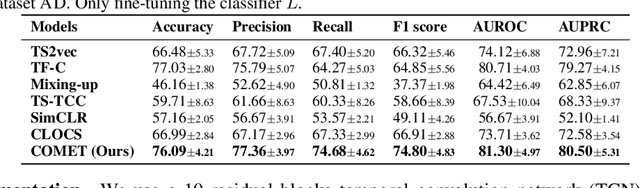
Contrastive representation learning is crucial in medical time series analysis as it alleviates dependency on labor-intensive, domain-specific, and scarce expert annotations. However, existing contrastive learning methods primarily focus on one single data level, which fails to fully exploit the intricate nature of medical time series. To address this issue, we present COMET, an innovative hierarchical framework that leverages data consistencies at all inherent levels in medical time series. Our meticulously designed model systematically captures data consistency from four potential levels: observation, sample, trial, and patient levels. By developing contrastive loss at multiple levels, we can learn effective representations that preserve comprehensive data consistency, maximizing information utilization in a self-supervised manner. We conduct experiments in the challenging patient-independent setting. We compare COMET against six baselines using three diverse datasets, which include ECG signals for myocardial infarction and EEG signals for Alzheimer's and Parkinson's diseases. The results demonstrate that COMET consistently outperforms all baselines, particularly in setup with 10% and 1% labeled data fractions across all datasets. These results underscore the significant impact of our framework in advancing contrastive representation learning techniques for medical time series. The source code is available at https://github.com/DL4mHealth/COMET.
* Accepted by NeurIPS 2023; 24pages (13 pages main paper + 11 pages supplementary materials)
UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting
Oct 28, 2023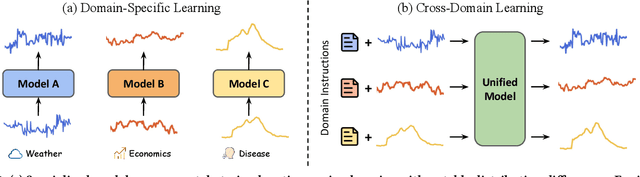
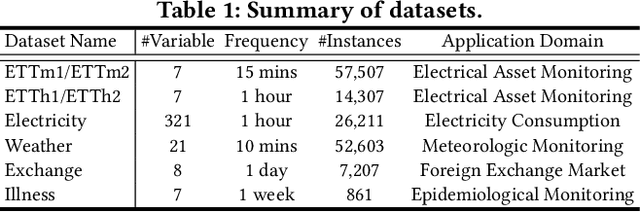
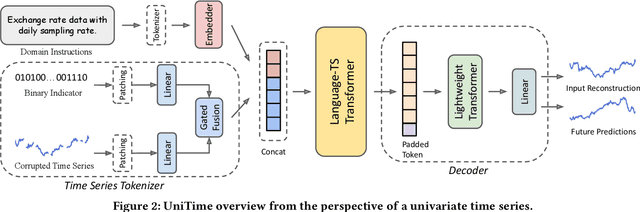
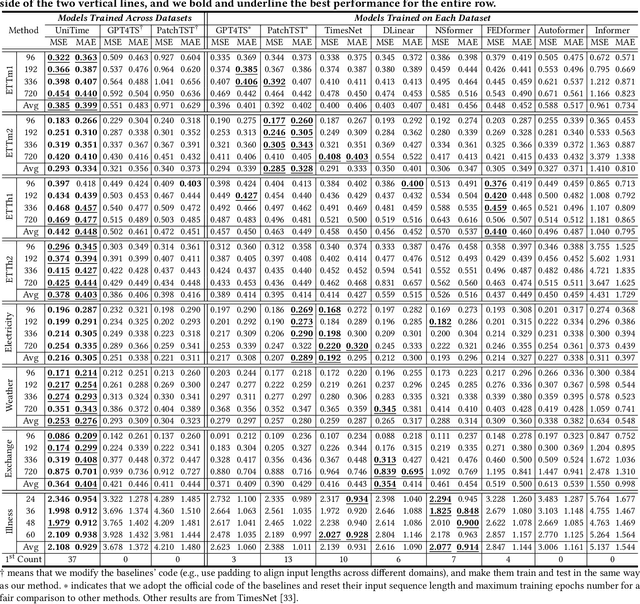
Multivariate time series forecasting plays a pivotal role in contemporary web technologies. In contrast to conventional methods that involve creating dedicated models for specific time series application domains, this research advocates for a unified model paradigm that transcends domain boundaries. However, learning an effective cross-domain model presents the following challenges. First, various domains exhibit disparities in data characteristics, e.g., the number of variables, posing hurdles for existing models that impose inflexible constraints on these factors. Second, the model may encounter difficulties in distinguishing data from various domains, leading to suboptimal performance in our assessments. Third, the diverse convergence rates of time series domains can also result in compromised empirical performance. To address these issues, we propose UniTime for effective cross-domain time series learning. Concretely, UniTime can flexibly adapt to data with varying characteristics. It also uses domain instructions and a Language-TS Transformer to offer identification information and align two modalities. In addition, UniTime employs masking to alleviate domain convergence speed imbalance issues. Our extensive experiments demonstrate the effectiveness of UniTime in advancing state-of-the-art forecasting performance and zero-shot transferability.
CityRefer: Geography-aware 3D Visual Grounding Dataset on City-scale Point Cloud Data
Oct 28, 2023City-scale 3D point cloud is a promising way to express detailed and complicated outdoor structures. It encompasses both the appearance and geometry features of segmented city components, including cars, streets, and buildings, that can be utilized for attractive applications such as user-interactive navigation of autonomous vehicles and drones. However, compared to the extensive text annotations available for images and indoor scenes, the scarcity of text annotations for outdoor scenes poses a significant challenge for achieving these applications. To tackle this problem, we introduce the CityRefer dataset for city-level visual grounding. The dataset consists of 35k natural language descriptions of 3D objects appearing in SensatUrban city scenes and 5k landmarks labels synchronizing with OpenStreetMap. To ensure the quality and accuracy of the dataset, all descriptions and labels in the CityRefer dataset are manually verified. We also have developed a baseline system that can learn encoded language descriptions, 3D object instances, and geographical information about the city's landmarks to perform visual grounding on the CityRefer dataset. To the best of our knowledge, the CityRefer dataset is the largest city-level visual grounding dataset for localizing specific 3D objects.
UniCat: Crafting a Stronger Fusion Baseline for Multimodal Re-Identification
Oct 28, 2023Multimodal Re-Identification (ReID) is a popular retrieval task that aims to re-identify objects across diverse data streams, prompting many researchers to integrate multiple modalities into a unified representation. While such fusion promises a holistic view, our investigations shed light on potential pitfalls. We uncover that prevailing late-fusion techniques often produce suboptimal latent representations when compared to methods that train modalities in isolation. We argue that this effect is largely due to the inadvertent relaxation of the training objectives on individual modalities when using fusion, what others have termed modality laziness. We present a nuanced point-of-view that this relaxation can lead to certain modalities failing to fully harness available task-relevant information, and yet, offers a protective veil to noisy modalities, preventing them from overfitting to task-irrelevant data. Our findings also show that unimodal concatenation (UniCat) and other late-fusion ensembling of unimodal backbones, when paired with best-known training techniques, exceed the current state-of-the-art performance across several multimodal ReID benchmarks. By unveiling the double-edged sword of "modality laziness", we motivate future research in balancing local modality strengths with global representations.
TLM: Token-Level Masking for Transformers
Oct 28, 2023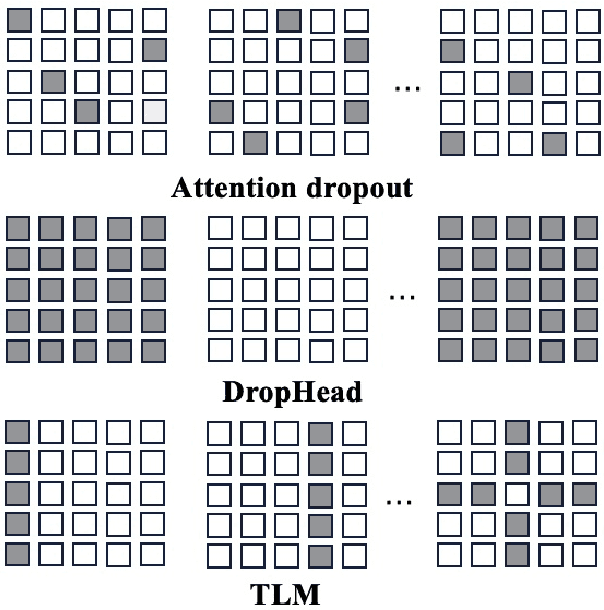

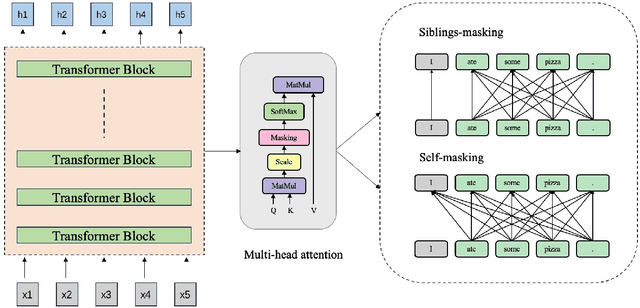
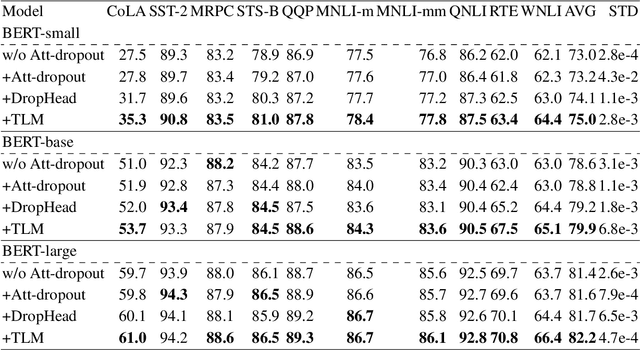
Structured dropout approaches, such as attention dropout and DropHead, have been investigated to regularize the multi-head attention mechanism in Transformers. In this paper, we propose a new regularization scheme based on token-level rather than structure-level to reduce overfitting. Specifically, we devise a novel Token-Level Masking (TLM) training strategy for Transformers to regularize the connections of self-attention, which consists of two masking techniques that are effective and easy to implement. The underlying idea is to manipulate the connections between tokens in the multi-head attention via masking, where the networks are forced to exploit partial neighbors' information to produce a meaningful representation. The generality and effectiveness of TLM are thoroughly evaluated via extensive experiments on 4 diversified NLP tasks across 18 datasets, including natural language understanding benchmark GLUE, ChineseGLUE, Chinese Grammatical Error Correction, and data-to-text generation. The results indicate that TLM can consistently outperform attention dropout and DropHead, e.g., it increases by 0.5 points relative to DropHead with BERT-large on GLUE. Moreover, TLM can establish a new record on the data-to-text benchmark Rotowire (18.93 BLEU). Our code will be publicly available at https://github.com/Young1993/tlm.
ODM3D: Alleviating Foreground Sparsity for Enhanced Semi-Supervised Monocular 3D Object Detection
Oct 28, 2023Monocular 3D object detection (M3OD) is a significant yet inherently challenging task in autonomous driving due to absence of implicit depth cues in a single RGB image. In this paper, we strive to boost currently underperforming monocular 3D object detectors by leveraging an abundance of unlabelled data via semi-supervised learning. Our proposed ODM3D framework entails cross-modal knowledge distillation at various levels to inject LiDAR-domain knowledge into a monocular detector during training. By identifying foreground sparsity as the main culprit behind existing methods' suboptimal training, we exploit the precise localisation information embedded in LiDAR points to enable more foreground-attentive and efficient distillation via the proposed BEV occupancy guidance mask, leading to notably improved knowledge transfer and M3OD performance. Besides, motivated by insights into why existing cross-modal GT-sampling techniques fail on our task at hand, we further design a novel cross-modal object-wise data augmentation strategy for effective RGB-LiDAR joint learning. Our method ranks 1st in both KITTI validation and test benchmarks, significantly surpassing all existing monocular methods, supervised or semi-supervised, on both BEV and 3D detection metrics.