 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026Cross-lingual sentence encoders typically cover only a few hundred languages and often trade downstream quality for stronger alignment, limiting their adoption. We introduce OmniSONAR, a new family of omnilingual, cross-lingual and cross-modal sentence embedding models that natively embed text, speech, code, and mathematical expressions in a single semantic space, while delivering state-of-the-art downstream performance at the scale of thousands of languages, from high-resource to extremely low-resource varieties. To reach this scale without representation collapse, we use progressive training. We first learn a strong foundational space for 200 languages with an LLM-initialized encoder-decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Building on this foundation, we expand to several thousands language varieties via a two-stage teacher-student encoder distillation framework. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR halves cross-lingual similarity search error on the 200-language FLORES dataset and reduces error by a factor of 15 on the 1,560-language BIBLE benchmark. It also enables strong translation, outperforming NLLB-3B on multilingual benchmarks and exceeding prior models (including much larger LLMs) by 15 chrF++ points on 1,560 languages into English BIBLE translation. OmniSONAR also performs strongly on MTEB and XLCoST. For speech, OmniSONAR achieves a 43% lower similarity-search error and reaches 97% of SeamlessM4T speech-to-text quality, despite being zero-shot for translation (trained only on ASR data). Finally, by training an encoder-decoder LM, Spectrum, exclusively on English text processing OmniSONAR embedding sequences, we unlock high-performance transfer to thousands of languages and speech for complex downstream tasks.
XL-Instruct: Synthetic Data for Cross-Lingual Open-Ended Generation
Mar 29, 2025Cross-lingual open-ended generation -- i.e. generating responses in a desired language different from that of the user's query -- is an important yet understudied problem. We introduce XL-AlpacaEval, a new benchmark for evaluating cross-lingual generation capabilities in Large Language Models (LLMs), and propose XL-Instruct, a high-quality synthetic data generation method. Fine-tuning with just 8K XL-Instruct-generated instructions significantly improves model performance, increasing the win rate against GPT-4o-Mini from 7.4% to 21.5%, and improving on several fine-grained quality metrics. Additionally, models fine-tuned on XL-Instruct exhibit strong zero-shot transfer to both English-only and multilingual generation tasks. Given its consistent gains across the board, we strongly recommend incorporating XL-Instruct in the post-training pipeline of future multilingual LLMs. To facilitate further research, we will publicly and freely release the XL-Instruct and XL-AlpacaEval datasets, which constitute two of the few cross-lingual resources currently available in the literature.
Towards Automatic Evaluation for Image Transcreation
Dec 18, 2024



Beyond conventional paradigms of translating speech and text, recently, there has been interest in automated transcreation of images to facilitate localization of visual content across different cultures. Attempts to define this as a formal Machine Learning (ML) problem have been impeded by the lack of automatic evaluation mechanisms, with previous work relying solely on human evaluation. In this paper, we seek to close this gap by proposing a suite of automatic evaluation metrics inspired by machine translation (MT) metrics, categorized into: a) Object-based, b) Embedding-based, and c) VLM-based. Drawing on theories from translation studies and real-world transcreation practices, we identify three critical dimensions of image transcreation: cultural relevance, semantic equivalence and visual similarity, and design our metrics to evaluate systems along these axes. Our results show that proprietary VLMs best identify cultural relevance and semantic equivalence, while vision-encoder representations are adept at measuring visual similarity. Meta-evaluation across 7 countries shows our metrics agree strongly with human ratings, with average segment-level correlations ranging from 0.55-0.87. Finally, through a discussion of the merits and demerits of each metric, we offer a robust framework for automated image transcreation evaluation, grounded in both theoretical foundations and practical application. Our code can be found here: https://github.com/simran-khanuja/automatic-eval-transcreation
Cultural Adaptation of Menus: A Fine-Grained Approach
Aug 24, 2024



Machine Translation of Culture-Specific Items (CSIs) poses significant challenges. Recent work on CSI translation has shown some success using Large Language Models (LLMs) to adapt to different languages and cultures; however, a deeper analysis is needed to examine the benefits and pitfalls of each method. In this paper, we introduce the ChineseMenuCSI dataset, the largest for Chinese-English menu corpora, annotated with CSI vs Non-CSI labels and a fine-grained test set. We define three levels of CSI figurativeness for a more nuanced analysis and develop a novel methodology for automatic CSI identification, which outperforms GPT-based prompts in most categories. Importantly, we are the first to integrate human translation theories into LLM-driven translation processes, significantly improving translation accuracy, with COMET scores increasing by up to 7 points.
Quality or Quantity? On Data Scale and Diversity in Adapting Large Language Models for Low-Resource Translation
Aug 23, 2024



Despite the recent popularity of Large Language Models (LLMs) in Machine Translation (MT), their performance in low-resource translation still lags significantly behind Neural Machine Translation (NMT) models. In this paper, we explore what it would take to adapt LLMs for low-resource settings. In particular, we re-examine the role of two factors: a) the importance and application of parallel data, and b) diversity in Supervised Fine-Tuning (SFT). Recently, parallel data has been shown to be less important for MT using LLMs than in previous MT research. Similarly, diversity during SFT has been shown to promote significant transfer in LLMs across languages and tasks. However, for low-resource LLM-MT, we show that the opposite is true for both of these considerations: a) parallel data is critical during both pretraining and SFT, and b) diversity tends to cause interference, not transfer. Our experiments, conducted with 3 LLMs across 2 low-resourced language groups - indigenous American and North-East Indian - reveal consistent patterns in both cases, underscoring the generalizability of our findings. We believe these insights will be valuable for scaling to massively multilingual LLM-MT models that can effectively serve lower-resource languages.
mHuBERT-147: A Compact Multilingual HuBERT Model
Jun 11, 2024



We present mHuBERT-147, the first general-purpose massively multilingual HuBERT speech representation model trained on 90K hours of clean, open-license data. To scale up the multi-iteration HuBERT approach, we use faiss-based clustering, achieving 5.2x faster label assignment than the original method. We also apply a new multilingual batching up-sampling strategy, leveraging both language and dataset diversity. After 3 training iterations, our compact 95M parameter mHuBERT-147 outperforms larger models trained on substantially more data. We rank second and first on the ML-SUPERB 10min and 1h leaderboards, with SOTA scores for 3 tasks. Across ASR/LID tasks, our model consistently surpasses XLS-R (300M params; 436K hours) and demonstrates strong competitiveness against the much larger MMS (1B params; 491K hours). Our findings indicate that mHuBERT-147 is a promising model for multilingual speech tasks, offering an unprecedented balance between high performance and parameter efficiency.
Code-Switching with Word Senses for Pretraining in Neural Machine Translation
Oct 21, 2023Lexical ambiguity is a significant and pervasive challenge in Neural Machine Translation (NMT), with many state-of-the-art (SOTA) NMT systems struggling to handle polysemous words (Campolungo et al., 2022). The same holds for the NMT pretraining paradigm of denoising synthetic "code-switched" text (Pan et al., 2021; Iyer et al., 2023), where word senses are ignored in the noising stage -- leading to harmful sense biases in the pretraining data that are subsequently inherited by the resulting models. In this work, we introduce Word Sense Pretraining for Neural Machine Translation (WSP-NMT) - an end-to-end approach for pretraining multilingual NMT models leveraging word sense-specific information from Knowledge Bases. Our experiments show significant improvements in overall translation quality. Then, we show the robustness of our approach to scale to various challenging data and resource-scarce scenarios and, finally, report fine-grained accuracy improvements on the DiBiMT disambiguation benchmark. Our studies yield interesting and novel insights into the merits and challenges of integrating word sense information and structured knowledge in multilingual pretraining for NMT.
Towards Effective Disambiguation for Machine Translation with Large Language Models
Sep 20, 2023


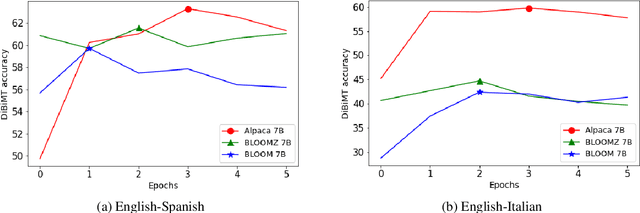
Resolving semantic ambiguity has long been recognised as a central challenge in the field of machine translation. Recent work on benchmarking translation performance on ambiguous sentences has exposed the limitations of conventional Neural Machine Translation (NMT) systems, which fail to capture many of these cases. Large language models (LLMs) have emerged as a promising alternative, demonstrating comparable performance to traditional NMT models while introducing new paradigms for controlling the target outputs. In this paper, we study the capabilities of LLMs to translate ambiguous sentences containing polysemous words and rare word senses. We also propose two ways to improve the handling of such ambiguity through in-context learning and fine-tuning on carefully curated ambiguous datasets. Experiments show that our methods can match or outperform state-of-the-art systems such as DeepL and NLLB in four out of five language directions. Our research provides valuable insights into effectively adapting LLMs for disambiguation during machine translation.
The University of Edinburgh's Submission to the WMT22 Code-Mixing Shared Task
Oct 20, 2022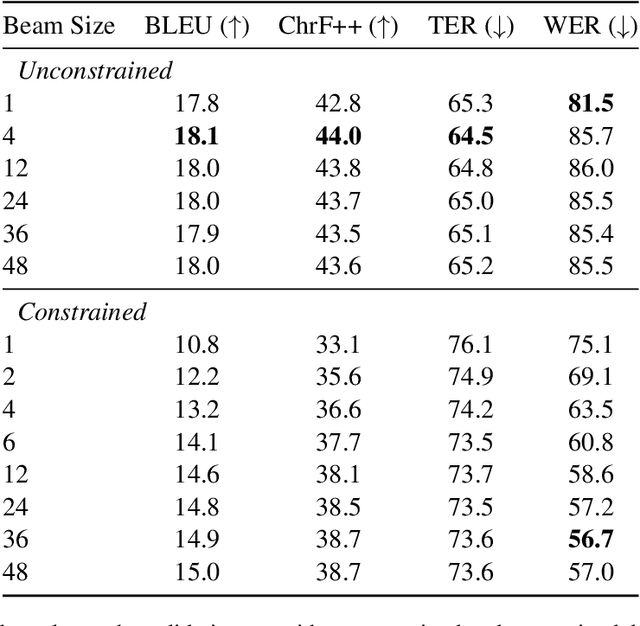
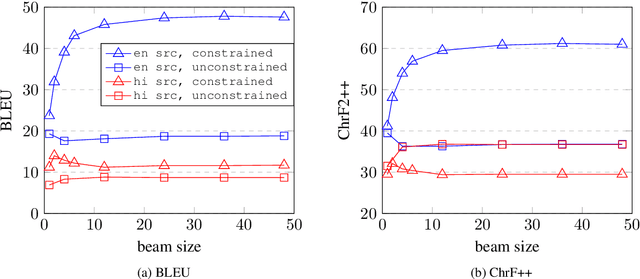
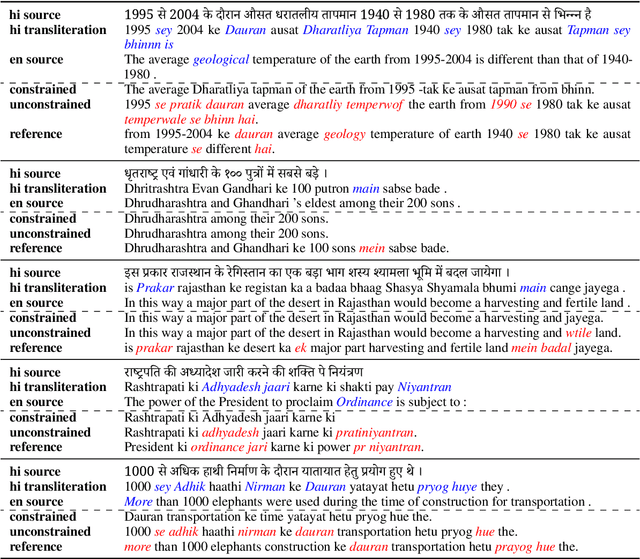
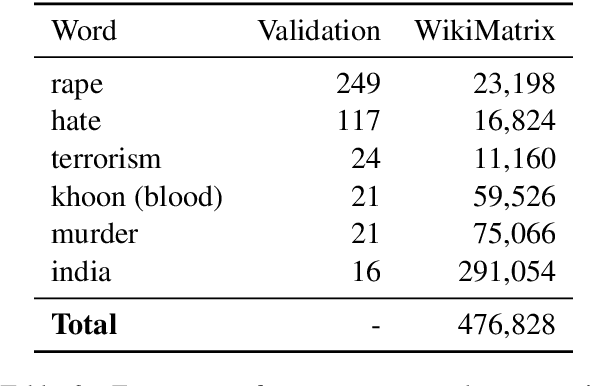
The University of Edinburgh participated in the WMT22 shared task on code-mixed translation. This consists of two subtasks: i) generating code-mixed Hindi/English (Hinglish) text generation from parallel Hindi and English sentences and ii) machine translation from Hinglish to English. As both subtasks are considered low-resource, we focused our efforts on careful data generation and curation, especially the use of backtranslation from monolingual resources. For subtask 1 we explored the effects of constrained decoding on English and transliterated subwords in order to produce Hinglish. For subtask 2, we investigated different pretraining techniques, namely comparing simple initialisation from existing machine translation models and aligned augmentation. For both subtasks, we found that our baseline systems worked best. Our systems for both subtasks were one of the overall top-performing submissions.
A Deep Learning Approach for Ontology Enrichment from Unstructured Text
Dec 16, 2021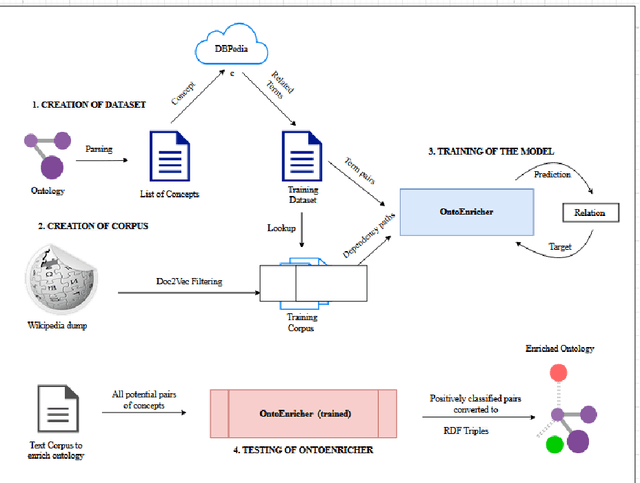
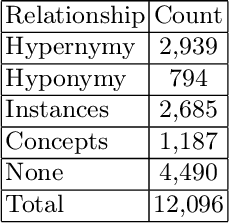
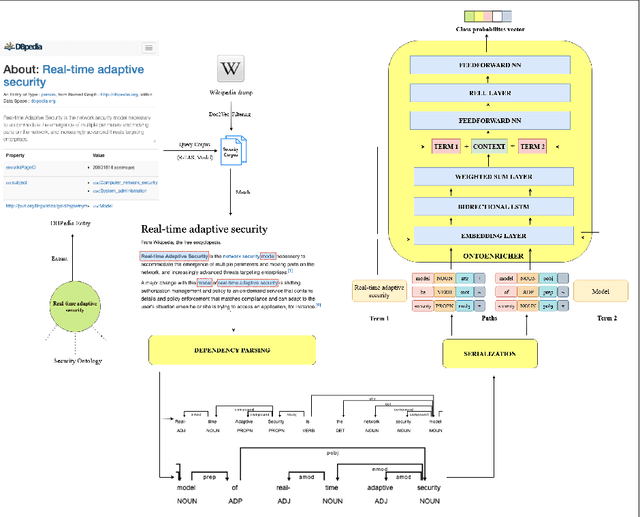
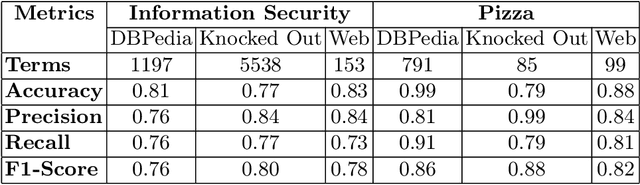
Information Security in the cyber world is a major cause for concern, with a significant increase in the number of attack surfaces. Existing information on vulnerabilities, attacks, controls, and advisories available on the web provides an opportunity to represent knowledge and perform security analytics to mitigate some of the concerns. Representing security knowledge in the form of ontology facilitates anomaly detection, threat intelligence, reasoning and relevance attribution of attacks, and many more. This necessitates dynamic and automated enrichment of information security ontologies. However, existing ontology enrichment algorithms based on natural language processing and ML models have issues with contextual extraction of concepts in words, phrases, and sentences. This motivates the need for sequential Deep Learning architectures that traverse through dependency paths in text and extract embedded vulnerabilities, threats, controls, products, and other security-related concepts and instances from learned path representations. In the proposed approach, Bidirectional LSTMs trained on a large DBpedia dataset and Wikipedia corpus of 2.8 GB along with Universal Sentence Encoder is deployed to enrich ISO 27001-based information security ontology. The model is trained and tested on a high-performance computing (HPC) environment to handle Wiki text dimensionality. The approach yielded a test accuracy of over 80% when tested with knocked-out concepts from ontology and web page instances to validate the robustness.