 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarch: Learned Query Optimization for Semantic Predicates
Jun 06, 2026With the advent of Large Language Models (LLMs), many database systems introduced semantic operators that enabled analytical queries over unstructured data (e.g. text, images, videos). Semantic operators typically incur high inference costs and latencies making semantic (AI) SQL queries challenging to apply on large scale datasets. At the same time, their semantic nature leads database engines to treat them as black boxes, making AISQL queries difficult to optimize. In this paper, we introduce Larch, a framework for optimizing the execution of semantic filters in AI SQL queries. Larch was inspired by two key observations: i) the high latency of semantic operators leaves significant room for computationally-heavy runtime optimization techniques, ii) unstructured data are typically accompanied by semantic information in the form of embeddings allowing for efficient semantic comparisons between AI_FILTER prompts and data values. Based on these two key observations, we present two Larch variants: Larch-A2C and Larch-Sel. Larch-A2C encodes arbitrary semantic filters expression tree using an embedding-augmented Gated Graph Neural Network and formulates the filter evaluation order as a Markov decision process. In contrast, Larch-Sel leverages a supervised learning model to predict filter selectivities, subsequently applying dynamic programming to find a near-optimal evaluation order for each input row. Evaluated across diverse real-world datasets and comprehensive synthetic workloads, both Larch variants always outperform existing semantic filter optimization techniques in terms of token usage. Our results demonstrate that Larch is robust across diverse workloads, reducing total token cost overhead by 3x-19x compared to Palimpzest and Quest.
Cortex AISQL: A Production SQL Engine for Unstructured Data
Nov 19, 2025Snowflake's Cortex AISQL is a production SQL engine that integrates native semantic operations directly into SQL. This integration allows users to write declarative queries that combine relational operations with semantic reasoning, enabling them to query both structured and unstructured data effortlessly. However, making semantic operations efficient at production scale poses fundamental challenges. Semantic operations are more expensive than traditional SQL operations, possess distinct latency and throughput characteristics, and their cost and selectivity are unknown during query compilation. Furthermore, existing query engines are not designed to optimize semantic operations. The AISQL query execution engine addresses these challenges through three novel techniques informed by production deployment data from Snowflake customers. First, AI-aware query optimization treats AI inference cost as a first-class optimization objective, reasoning about large language model (LLM) cost directly during query planning to achieve 2-8$\times$ speedups. Second, adaptive model cascades reduce inference costs by routing most rows through a fast proxy model while escalating uncertain cases to a powerful oracle model, achieving 2-6$\times$ speedups while maintaining 90-95% of oracle model quality. Third, semantic join query rewriting lowers the quadratic time complexity of join operations to linear through reformulation as multi-label classification tasks, achieving 15-70$\times$ speedups with often improved prediction quality. AISQL is deployed in production at Snowflake, where it powers diverse customer workloads across analytics, search, and content understanding.
Eliciting In-context Retrieval and Reasoning for Long-context Large Language Models
Jan 14, 2025



Recent advancements in long-context language models (LCLMs) promise to transform Retrieval-Augmented Generation (RAG) by simplifying pipelines. With their expanded context windows, LCLMs can process entire knowledge bases and perform retrieval and reasoning directly -- a capability we define as In-Context Retrieval and Reasoning (ICR^2). However, existing benchmarks like LOFT often overestimate LCLM performance by providing overly simplified contexts. To address this, we introduce ICR^2, a benchmark that evaluates LCLMs in more realistic scenarios by including confounding passages retrieved with strong retrievers. We then propose three methods to enhance LCLM performance: (1) retrieve-then-generate fine-tuning, (2) retrieval-attention-probing, which uses attention heads to filter and de-noise long contexts during decoding, and (3) joint retrieval head training alongside the generation head. Our evaluation of five well-known LCLMs on LOFT and ICR^2 demonstrates significant gains with our best approach applied to Mistral-7B: +17 and +15 points by Exact Match on LOFT, and +13 and +2 points on ICR^2, compared to vanilla RAG and supervised fine-tuning, respectively. It even outperforms GPT-4-Turbo on most tasks despite being a much smaller model.
Time Sensitive Knowledge Editing through Efficient Finetuning
Jun 06, 2024



Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.
Think While You Write: Hypothesis Verification Promotes Faithful Knowledge-to-Text Generation
Nov 16, 2023



Neural knowledge-to-text generation models often struggle to faithfully generate descriptions for the input facts: they may produce hallucinations that contradict the given facts, or describe facts not present in the input. To reduce hallucinations, we propose a novel decoding method, TWEAK (Think While Effectively Articulating Knowledge). TWEAK treats the generated sequences at each decoding step and its future sequences as hypotheses, and ranks each generation candidate based on how well their corresponding hypotheses support the input facts using a Hypothesis Verification Model (HVM). We first demonstrate the effectiveness of TWEAK by using a Natural Language Inference (NLI) model as the HVM and report improved faithfulness with minimal impact on the quality. We then replace the NLI model with our task-specific HVM trained with a first-of-a-kind dataset, FATE (Fact-Aligned Textual Entailment), which pairs input facts with their faithful and hallucinated descriptions with the hallucinated spans marked. The new HVM improves the faithfulness and the quality further and runs faster. Overall the best TWEAK variants improve on average 2.22/7.17 points on faithfulness measured by FactKB over WebNLG and TekGen/GenWiki, respectively, with only 0.14/0.32 points degradation on quality measured by BERTScore over the same datasets. Since TWEAK is a decoding-only approach, it can be integrated with any neural generative model without retraining.
FLEEK: Factual Error Detection and Correction with Evidence Retrieved from External Knowledge
Oct 26, 2023



Detecting factual errors in textual information, whether generated by large language models (LLM) or curated by humans, is crucial for making informed decisions. LLMs' inability to attribute their claims to external knowledge and their tendency to hallucinate makes it difficult to rely on their responses. Humans, too, are prone to factual errors in their writing. Since manual detection and correction of factual errors is labor-intensive, developing an automatic approach can greatly reduce human effort. We present FLEEK, a prototype tool that automatically extracts factual claims from text, gathers evidence from external knowledge sources, evaluates the factuality of each claim, and suggests revisions for identified errors using the collected evidence. Initial empirical evaluation on fact error detection (77-85\% F1) shows the potential of FLEEK. A video demo of FLEEK can be found at https://youtu.be/NapJFUlkPdQ.
A Better Match for Drivers and Riders: Reinforcement Learning at Lyft
Oct 20, 2023To better match drivers to riders in our ridesharing application, we revised Lyft's core matching algorithm. We use a novel online reinforcement learning approach that estimates the future earnings of drivers in real time and use this information to find more efficient matches. This change was the first documented implementation of a ridesharing matching algorithm that can learn and improve in real time. We evaluated the new approach during weeks of switchback experimentation in most Lyft markets, and estimated how it benefited drivers, riders, and the platform. In particular, it enabled our drivers to serve millions of additional riders each year, leading to more than $30 million per year in incremental revenue. Lyft rolled out the algorithm globally in 2021.
Construction of Paired Knowledge Graph-Text Datasets Informed by Cyclic Evaluation
Sep 20, 2023



Datasets that pair Knowledge Graphs (KG) and text together (KG-T) can be used to train forward and reverse neural models that generate text from KG and vice versa. However models trained on datasets where KG and text pairs are not equivalent can suffer from more hallucination and poorer recall. In this paper, we verify this empirically by generating datasets with different levels of noise and find that noisier datasets do indeed lead to more hallucination. We argue that the ability of forward and reverse models trained on a dataset to cyclically regenerate source KG or text is a proxy for the equivalence between the KG and the text in the dataset. Using cyclic evaluation we find that manually created WebNLG is much better than automatically created TeKGen and T-REx. Guided by these observations, we construct a new, improved dataset called LAGRANGE using heuristics meant to improve equivalence between KG and text and show the impact of each of the heuristics on cyclic evaluation. We also construct two synthetic datasets using large language models (LLMs), and observe that these are conducive to models that perform significantly well on cyclic generation of text, but less so on cyclic generation of KGs, probably because of a lack of a consistent underlying ontology.
Document Summarization with Text Segmentation
Jan 20, 2023



In this paper, we exploit the innate document segment structure for improving the extractive summarization task. We build two text segmentation models and find the most optimal strategy to introduce their output predictions in an extractive summarization model. Experimental results on a corpus of scientific articles show that extractive summarization benefits from using a highly accurate segmentation method. In particular, most of the improvement is in documents where the most relevant information is not at the beginning thus, we conclude that segmentation helps in reducing the lead bias problem.
Semi-Supervised Few-Shot Intent Classification and Slot Filling
Sep 17, 2021
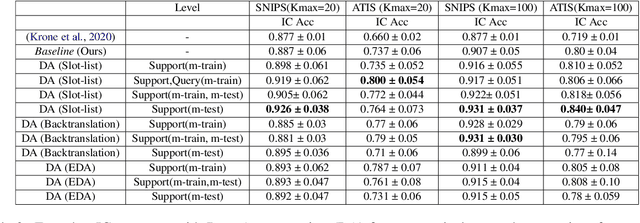
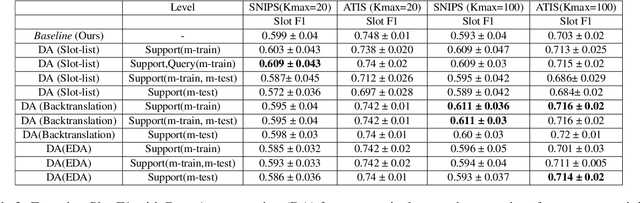

Intent classification (IC) and slot filling (SF) are two fundamental tasks in modern Natural Language Understanding (NLU) systems. Collecting and annotating large amounts of data to train deep learning models for such systems is not scalable. This problem can be addressed by learning from few examples using fast supervised meta-learning techniques such as prototypical networks. In this work, we systematically investigate how contrastive learning and unsupervised data augmentation methods can benefit these existing supervised meta-learning pipelines for jointly modelled IC/SF tasks. Through extensive experiments across standard IC/SF benchmarks (SNIPS and ATIS), we show that our proposed semi-supervised approaches outperform standard supervised meta-learning methods: contrastive losses in conjunction with prototypical networks consistently outperform the existing state-of-the-art for both IC and SF tasks, while data augmentation strategies primarily improve few-shot IC by a significant margin.