 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflective Prompt Tuning through Language Model Function-Calling
May 20, 2026Large language models (LLMs) have become increasingly capable of following instructions and complex reasoning, making prompting a flexible interface for adapting models without parameter updates. Yet prompt design remains labor-intensive and highly sensitive to formatting, phrasing, and instruction order, motivating automated prompt optimization methods that reduce manual effort while preserving inference-time flexibility. However, existing methods often search over prompt candidates or use fixed critique-refine pipelines driven by individual examples or small batches, limiting their ability to capture systematic error patterns and make targeted edits grounded in failure history. We propose Reflective Prompt Tuning (RPT), a framework that uses LLM function calling to simulate the iterative workflow of human prompt engineers. An LLM optimizer calls a diagnostic function that evaluates the target model over an entire optimization set, summarizes recurring failure modes, and returns a structured diagnostic report. The optimizer uses this report, together with an accumulated memory of prior reports, to revise the prompt for the next iteration. RPT further supports confidence-aware optimization by using calibration signals in diagnostic feedback and final prompt selection. Across three reasoning tasks, RPT improves over initial prompts by up to 12.9 points, remains competitive with state of the art, and improves confidence calibration. Our analyses show that RPT is especially effective on multi-hop and mathematical reasoning, producing targeted prompt revisions that align with diagnosed failure patterns and lead to gains in task performance and calibration.
Blue Data Intelligence Layer: Streaming Data and Agents for Multi-source Multi-modal Data-Centric Applications
Apr 16, 2026NL2SQL systems aim to address the growing need for natural language interaction with data. However, real-world information rarely maps to a single SQL query because (1) users express queries iteratively (2) questions often span multiple data sources beyond the closed-world assumption of a single database, and (3) queries frequently rely on commonsense or external knowledge. Consequently, satisfying realistic data needs require integrating heterogeneous sources, modalities, and contextual data. In this paper, we present Blue's Data Intelligence Layer (DIL) designed to support multi-source, multi-modal, and data-centric applications. Blue is a compound AI system that orchestrates agents and data for enterprise settings. DIL serves as the data intelligence layer for agentic data processing, to bridge the semantic gap between user intent and available information by unifying structured enterprise data, world knowledge accessible through LLMs, and personal context obtained through interaction. At the core of DIL is a data registry that stores metadata for diverse data sources and modalities to enable both native and natural language queries. DIL treats LLMs, the Web, and the User as source 'databases', each with their own query interface, elevating them to first-class data sources. DIL relies on data planners to transform user queries into executable query plans. These plans are declarative abstractions that unify relational operators with other operators spanning multiple modalities. DIL planners support decomposition of complex requests into subqueries, retrieval from diverse sources, and finally reasoning and integration to produce final results. We demonstrate DIL through two interactive scenarios in which user queries dynamically trigger multi-source retrieval, cross-modal reasoning, and result synthesis, illustrating how compound AI systems can move beyond single database NL2SQL.
From Proof to Program: Characterizing Tool-Induced Reasoning Hallucinations in Large Language Models
Nov 14, 2025
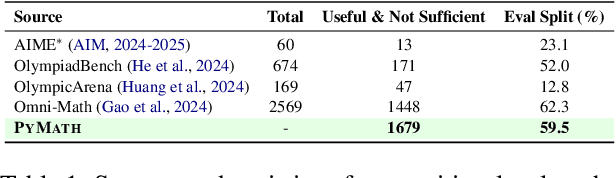
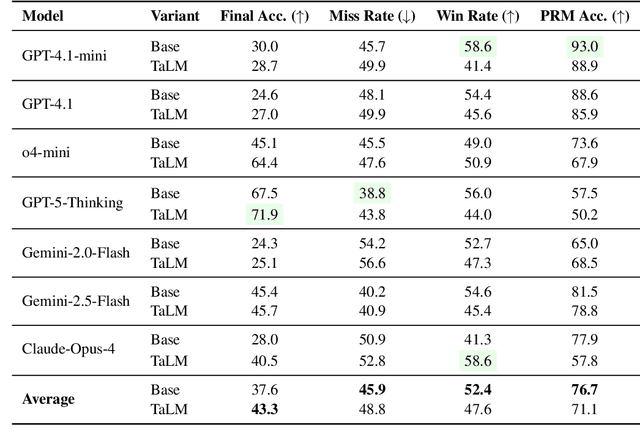
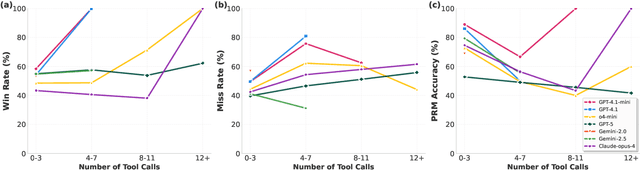
Tool-augmented Language Models (TaLMs) can invoke external tools to solve problems beyond their parametric capacity. However, it remains unclear whether these tool-enabled gains reflect trustworthy reasoning. Focusing on the Code Interpreter tool, we show that even when tools are selected and executed correctly, TaLMs treat tool outputs as substitutes for reasoning, producing solutions that appear correct but lack coherent justification. We term this failure mode Tool-Induced Myopia (TIM), and study it using PYMATH, a benchmark of 1,679 competition-level mathematical problems for which Python code is helpful but not sufficient. We further develop a multi-dimensional evaluation suite to quantify reasoning degradation in TaLMs relative to their non-tool counterparts. Our findings reveal that while TaLMs achieve up to a 19.3 percentage point gain in final-answer accuracy, their reasoning behavior consistently deteriorates (e.g., non-tool LLMs win up to 41.5% more often in pairwise comparisons of the reasoning process). This degradation intensifies with tool use; the more frequently a model invokes tools, the less coherent its reasoning becomes. Moreover, tool use shifts errors from arithmetic mistakes toward global reasoning failures (logic, assumption, creativity); with TIM present in ~55% of high-risk cases. Finally, we propose a preference-optimization-based framework that realigns TaLMs to use tools as assistive evidence, improving both final-answer accuracy and reasoning depth under tool use. Codes and data are available at: https://github.com/megagonlabs/TIM.
FactBench: A Dynamic Benchmark for In-the-Wild Language Model Factuality Evaluation
Oct 29, 2024



Language models (LMs) are widely used by an increasing number of users, underscoring the challenge of maintaining factuality across a broad range of topics. We first present VERIFY (Verification and Evidence RetrIeval for FactualitY evaluation), a pipeline to evaluate LMs' factuality in real-world user interactions. VERIFY considers the verifiability of LM-generated content and categorizes content units as supported, unsupported, or undecidable based on the retrieved evidence from the Web. Importantly, factuality judgment by VERIFY correlates better with human evaluations than existing methods. Using VERIFY, we identify "hallucination prompts" across diverse topics, i.e., those eliciting the highest rates of incorrect and inconclusive LM responses. These prompts form FactBench, a dataset of 1K prompts across 150 fine-grained topics. Our dataset captures emerging factuality challenges in real-world LM interactions and can be regularly updated with new prompts. We benchmark widely-used LMs from GPT, Gemini, and Llama3.1 family on FactBench, yielding the following key findings: (i) Proprietary models exhibit better factuality, with performance declining from Easy to Hard hallucination prompts. (ii) Llama3.1-405B-Instruct shows comparable or lower factual accuracy than Llama3.1-70B-Instruct across all evaluation methods due to its higher subjectivity that leads to more content labeled as undecidable. (iii) Gemini1.5-Pro shows a significantly higher refusal rate, with over-refusal in 25% of cases. Our code and data are publicly available at https://huggingface.co/spaces/launch/factbench.
APE: Active Learning-based Tooling for Finding Informative Few-shot Examples for LLM-based Entity Matching
Jul 29, 2024
Prompt engineering is an iterative procedure often requiring extensive manual effort to formulate suitable instructions for effectively directing large language models (LLMs) in specific tasks. Incorporating few-shot examples is a vital and effective approach to providing LLMs with precise instructions, leading to improved LLM performance. Nonetheless, identifying the most informative demonstrations for LLMs is labor-intensive, frequently entailing sifting through an extensive search space. In this demonstration, we showcase a human-in-the-loop tool called APE (Active Prompt Engineering) designed for refining prompts through active learning. Drawing inspiration from active learning, APE iteratively selects the most ambiguous examples for human feedback, which will be transformed into few-shot examples within the prompt. The demo recording can be found with the submission or be viewed at https://youtu.be/OwQ6MQx53-Y.
Enhancing Language Model Factuality via Activation-Based Confidence Calibration and Guided Decoding
Jun 19, 2024Calibrating language models (LMs) aligns their generation confidence with the actual likelihood of answer correctness, which can inform users about LMs' reliability and mitigate hallucinated content. However, prior calibration methods, such as self-consistency-based and logit-based approaches, are either limited in inference-time efficiency or fall short of providing informative signals. Moreover, simply filtering out low-confidence responses reduces the LM's helpfulness when the answers are correct. Therefore, effectively using calibration techniques to enhance an LM's factuality remains an unsolved challenge. In this paper, we first propose an activation-based calibration method, ActCab, which trains a linear layer on top of the LM's last-layer activations that can better capture the representations of knowledge. Built on top of ActCab, we further propose CoDec, a confidence-guided decoding strategy to elicit truthful answers with high confidence from LMs. By evaluating on five popular QA benchmarks, ActCab achieves superior calibration performance than all competitive baselines, e.g., by reducing the average expected calibration error (ECE) score by up to 39%. Further experiments on CoDec show consistent improvements in several LMs' factuality on challenging QA datasets, such as TruthfulQA, highlighting the value of confidence signals in enhancing factuality.
LITO: Learnable Intervention for Truthfulness Optimization
May 01, 2024



Large language models (LLMs) can generate long-form and coherent text, but they still frequently hallucinate facts, thus limiting their reliability. To address this issue, inference-time methods that elicit truthful responses have been proposed by shifting LLM representations towards learned "truthful directions". However, applying the truthful directions with the same intensity fails to generalize across different question contexts. We propose LITO, a Learnable Intervention method for Truthfulness Optimization that automatically identifies the optimal intervention intensity tailored to a specific context. LITO explores a sequence of model generations based on increasing levels of intervention intensities. It selects the most accurate response or refuses to answer when the predictions are highly uncertain. Experiments on multiple LLMs and question-answering datasets demonstrate that LITO improves truthfulness while preserving task accuracy. The adaptive nature of LITO counters issues with one-size-fits-all intervention-based solutions, maximizing model truthfulness by reflecting internal knowledge only when the model is confident.
FLEEK: Factual Error Detection and Correction with Evidence Retrieved from External Knowledge
Oct 26, 2023



Detecting factual errors in textual information, whether generated by large language models (LLM) or curated by humans, is crucial for making informed decisions. LLMs' inability to attribute their claims to external knowledge and their tendency to hallucinate makes it difficult to rely on their responses. Humans, too, are prone to factual errors in their writing. Since manual detection and correction of factual errors is labor-intensive, developing an automatic approach can greatly reduce human effort. We present FLEEK, a prototype tool that automatically extracts factual claims from text, gathers evidence from external knowledge sources, evaluates the factuality of each claim, and suggests revisions for identified errors using the collected evidence. Initial empirical evaluation on fact error detection (77-85\% F1) shows the potential of FLEEK. A video demo of FLEEK can be found at https://youtu.be/NapJFUlkPdQ.
CompactIE: Compact Facts in Open Information Extraction
May 05, 2022
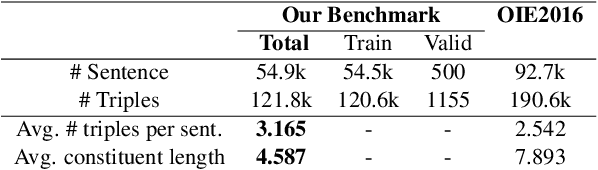
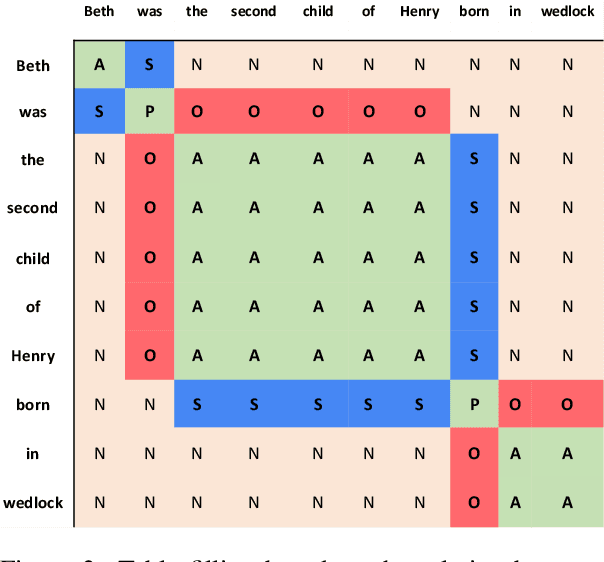

A major drawback of modern neural OpenIE systems and benchmarks is that they prioritize high coverage of information in extractions over compactness of their constituents. This severely limits the usefulness of OpenIE extractions in many downstream tasks. The utility of extractions can be improved if extractions are compact and share constituents. To this end, we study the problem of identifying compact extractions with neural-based methods. We propose CompactIE, an OpenIE system that uses a novel pipelined approach to produce compact extractions with overlapping constituents. It first detects constituents of the extractions and then links them to build extractions. We train our system on compact extractions obtained by processing existing benchmarks. Our experiments on CaRB and Wire57 datasets indicate that CompactIE finds 1.5x-2x more compact extractions than previous systems, with high precision, establishing a new state-of-the-art performance in OpenIE.