 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE3VS-Bench: A Benchmark for Viewpoint-Dependent Active Perception in 3D Gaussian Splatting Scenes
Apr 20, 2026Visual search in 3D environments requires embodied agents to actively explore their surroundings and acquire task-relevant evidence. However, existing visual search and embodied AI benchmarks, including EQA, typically rely on static observations or constrained egocentric motion, and thus do not explicitly evaluate fine-grained viewpoint-dependent phenomena that arise under unrestricted 5-DoF viewpoint control in real-world 3D environments, such as visibility changes caused by vertical viewpoint shifts, revealing contents inside containers, and disambiguating object attributes that are only observable from specific angles. To address this limitation, we introduce {E3VS-Bench}, a benchmark for embodied 3D visual search where agents must control their viewpoints in 5-DoF to gather viewpoint-dependent evidence for question answering. E3VS-Bench consists of 99 high-fidelity 3D scenes reconstructed using 3D Gaussian Splatting and 2,014 question-driven episodes. 3D Gaussian Splatting enables photorealistic free-viewpoint rendering that preserves fine-grained visual details (e.g., small text and subtle attributes) often degraded in mesh-based simulators, thereby allowing the construction of questions that cannot be answered from a single view and instead require active inspection across viewpoints in 5-DoF. We evaluate multiple state-of-the-art VLMs and compare their performance with humans. Despite strong 2D reasoning ability, all models exhibit a substantial gap from humans, highlighting limitations in active perception and coherent viewpoint planning specifically under full 5-DoF viewpoint changes.
EEG-Based Multimodal Learning via Hyperbolic Mixture-of-Curvature Experts
Apr 14, 2026Electroencephalography (EEG)-based multimodal learning integrates brain signals with complementary modalities to improve mental state assessment, providing great clinical potential. The effectiveness of such paradigms largely depends on the representation learning on heterogeneous modalities. For EEG-based paradigms, one promising approach is to leverage their hierarchical structures, as recent studies have shown that both EEG and associated modalities (e.g., facial expressions) exhibit hierarchical structures reflecting complex cognitive processes. However, Euclidean embeddings struggle to represent these hierarchical structures due to their flat geometry, while hyperbolic spaces, with their exponential growth property, are naturally suited for them. In this work, we propose EEG-MoCE, a novel hyperbolic mixture-of-curvature experts framework designed for multimodal neurotechnology. EEG-MoCE assigns each modality to an expert in a learnable-curvature hyperbolic space, enabling adaptive modeling of its intrinsic geometry. A curvature-aware fusion strategy then dynamically weights experts, emphasizing modalities with richer hierarchical information. Extensive experiments on benchmark datasets demonstrate that EEG-MoCE achieves state-of-the-art performance, including emotion recognition, sleep staging, and cognitive assessment.
HEEGNet: Hyperbolic Embeddings for EEG
Jan 06, 2026Electroencephalography (EEG)-based brain-computer interfaces facilitate direct communication with a computer, enabling promising applications in human-computer interactions. However, their utility is currently limited because EEG decoding often suffers from poor generalization due to distribution shifts across domains (e.g., subjects). Learning robust representations that capture underlying task-relevant information would mitigate these shifts and improve generalization. One promising approach is to exploit the underlying hierarchical structure in EEG, as recent studies suggest that hierarchical cognitive processes, such as visual processing, can be encoded in EEG. While many decoding methods still rely on Euclidean embeddings, recent work has begun exploring hyperbolic geometry for EEG. Hyperbolic spaces, regarded as the continuous analogue of tree structures, provide a natural geometry for representing hierarchical data. In this study, we first empirically demonstrate that EEG data exhibit hyperbolicity and show that hyperbolic embeddings improve generalization. Motivated by these findings, we propose HEEGNet, a hybrid hyperbolic network architecture to capture the hierarchical structure in EEG and learn domain-invariant hyperbolic embeddings. To this end, HEEGNet combines both Euclidean and hyperbolic encoders and employs a novel coarse-to-fine domain adaptation strategy. Extensive experiments on multiple public EEG datasets, covering visual evoked potentials, emotion recognition, and intracranial EEG, demonstrate that HEEGNet achieves state-of-the-art performance.
SPD Learning for Covariance-Based Neuroimaging Analysis: Perspectives, Methods, and Challenges
Apr 26, 2025



Neuroimaging provides a critical framework for characterizing brain activity by quantifying connectivity patterns and functional architecture across modalities. While modern machine learning has significantly advanced our understanding of neural processing mechanisms through these datasets, decoding task-specific signatures must contend with inherent neuroimaging constraints, for example, low signal-to-noise ratios in raw electrophysiological recordings, cross-session non-stationarity, and limited sample sizes. This review focuses on machine learning approaches for covariance-based neuroimaging data, where often symmetric positive definite (SPD) matrices under full-rank conditions encode inter-channel relationships. By equipping the space of SPD matrices with Riemannian metrics (e.g., affine-invariant or log-Euclidean), their space forms a Riemannian manifold enabling geometric analysis. We unify methodologies operating on this manifold under the SPD learning framework, which systematically leverages the SPD manifold's geometry to process covariance features, thereby advancing brain imaging analytics.
Answerability Fields: Answerable Location Estimation via Diffusion Models
Jul 26, 2024



In an era characterized by advancements in artificial intelligence and robotics, enabling machines to interact with and understand their environment is a critical research endeavor. In this paper, we propose Answerability Fields, a novel approach to predicting answerability within complex indoor environments. Leveraging a 3D question answering dataset, we construct a comprehensive Answerability Fields dataset, encompassing diverse scenes and questions from ScanNet. Using a diffusion model, we successfully infer and evaluate these Answerability Fields, demonstrating the importance of objects and their locations in answering questions within a scene. Our results showcase the efficacy of Answerability Fields in guiding scene-understanding tasks, laying the foundation for their application in enhancing interactions between intelligent agents and their environments.
Map-based Modular Approach for Zero-shot Embodied Question Answering
May 26, 2024Building robots capable of interacting with humans through natural language in the visual world presents a significant challenge in the field of robotics. To overcome this challenge, Embodied Question Answering (EQA) has been proposed as a benchmark task to measure the ability to identify an object navigating through a previously unseen environment in response to human-posed questions. Although some methods have been proposed, their evaluations have been limited to simulations, without experiments in real-world scenarios. Furthermore, all of these methods are constrained by a limited vocabulary for question-and-answer interactions, making them unsuitable for practical applications. In this work, we propose a map-based modular EQA method that enables real robots to navigate unknown environments through frontier-based map creation and address unknown QA pairs using foundation models that support open vocabulary. Unlike the questions of the previous EQA dataset on Matterport 3D (MP3D), questions in our real-world experiments contain various question formats and vocabularies not included in the training data. We conduct comprehensive experiments on virtual environments (MP3D-EQA) and two real-world house environments and demonstrate that our method can perform EQA even in the real world.
CityRefer: Geography-aware 3D Visual Grounding Dataset on City-scale Point Cloud Data
Oct 28, 2023City-scale 3D point cloud is a promising way to express detailed and complicated outdoor structures. It encompasses both the appearance and geometry features of segmented city components, including cars, streets, and buildings, that can be utilized for attractive applications such as user-interactive navigation of autonomous vehicles and drones. However, compared to the extensive text annotations available for images and indoor scenes, the scarcity of text annotations for outdoor scenes poses a significant challenge for achieving these applications. To tackle this problem, we introduce the CityRefer dataset for city-level visual grounding. The dataset consists of 35k natural language descriptions of 3D objects appearing in SensatUrban city scenes and 5k landmarks labels synchronizing with OpenStreetMap. To ensure the quality and accuracy of the dataset, all descriptions and labels in the CityRefer dataset are manually verified. We also have developed a baseline system that can learn encoded language descriptions, 3D object instances, and geographical information about the city's landmarks to perform visual grounding on the CityRefer dataset. To the best of our knowledge, the CityRefer dataset is the largest city-level visual grounding dataset for localizing specific 3D objects.
SPD domain-specific batch normalization to crack interpretable unsupervised domain adaptation in EEG
Jun 02, 2022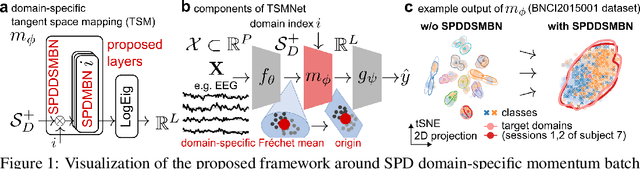
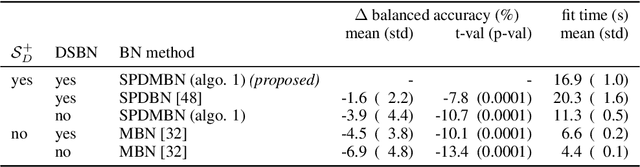
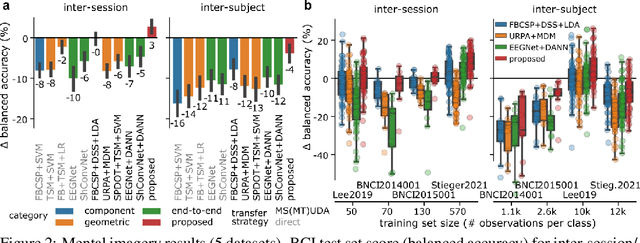
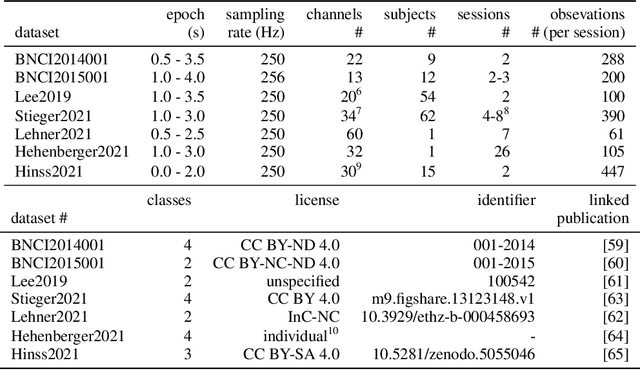
Electroencephalography (EEG) provides access to neuronal dynamics non-invasively with millisecond resolution, rendering it a viable method in neuroscience and healthcare. However, its utility is limited as current EEG technology does not generalize well across domains (i.e., sessions and subjects) without expensive supervised re-calibration. Contemporary methods cast this transfer learning (TL) problem as a multi-source/-target unsupervised domain adaptation (UDA) problem and address it with deep learning or shallow, Riemannian geometry aware alignment methods. Both directions have, so far, failed to consistently close the performance gap to state-of-the-art domain-specific methods based on tangent space mapping (TSM) on the symmetric positive definite (SPD) manifold. Here, we propose a theory-based machine learning framework that enables, for the first time, learning domain-invariant TSM models in an end-to-end fashion. To achieve this, we propose a new building block for geometric deep learning, which we denote SPD domain-specific momentum batch normalization (SPDDSMBN). A SPDDSMBN layer can transform domain-specific SPD inputs into domain-invariant SPD outputs, and can be readily applied to multi-source/-target and online UDA scenarios. In extensive experiments with 6 diverse EEG brain-computer interface (BCI) datasets, we obtain state-of-the-art performance in inter-session and -subject TL with a simple, intrinsically interpretable network architecture, which we denote TSMNet.
On the interpretation of linear Riemannian tangent space model parameters in M/EEG
Jul 30, 2021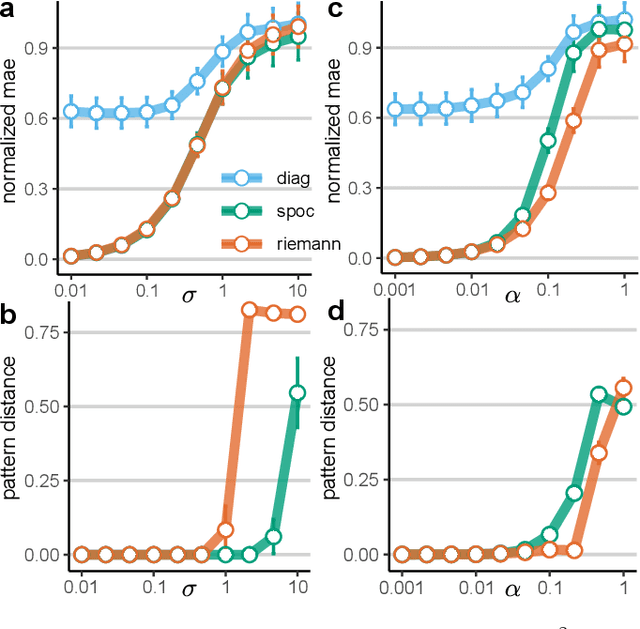
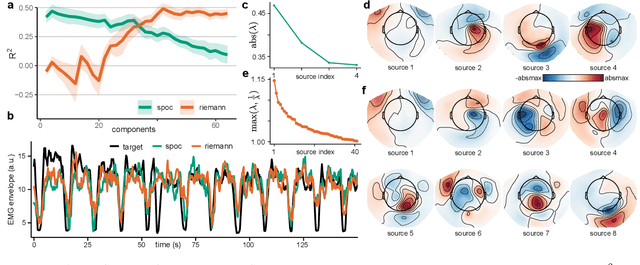
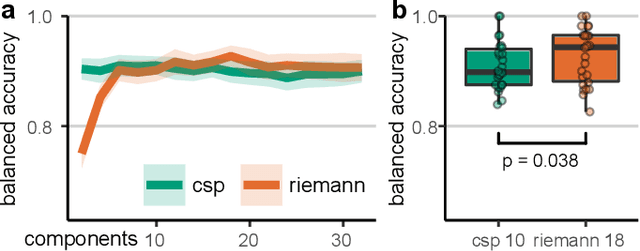
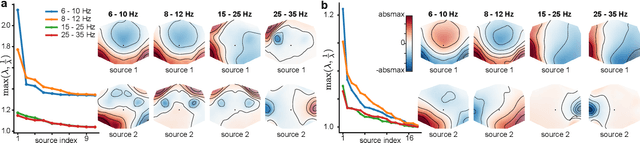
Riemannian tangent space methods offer state-of-the-art performance in magnetoencephalography (MEG) and electroencephalography (EEG) based applications such as brain-computer interfaces and biomarker development. One limitation, particularly relevant for biomarker development, is limited model interpretability compared to established component-based methods. Here, we propose a method to transform the parameters of linear tangent space models into interpretable patterns. Using typical assumptions, we show that this approach identifies the true patterns of latent sources, encoding a target signal. In simulations and two real MEG and EEG datasets, we demonstrate the validity of the proposed approach and investigate its behavior when the model assumptions are violated. Our results confirm that Riemannian tangent space methods are robust to differences in the source patterns across observations. We found that this robustness property also transfers to the associated patterns.
Insights from Classifying Visual Concepts with Multiple Kernel Learning
Dec 16, 2011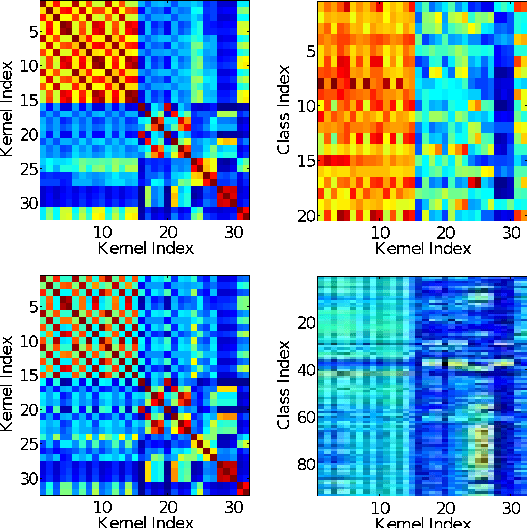
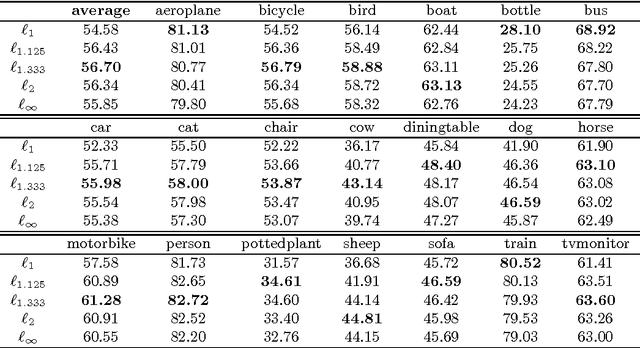
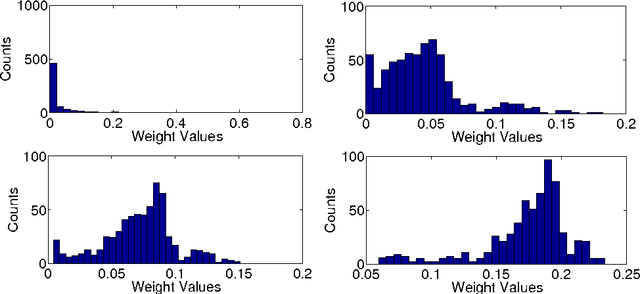
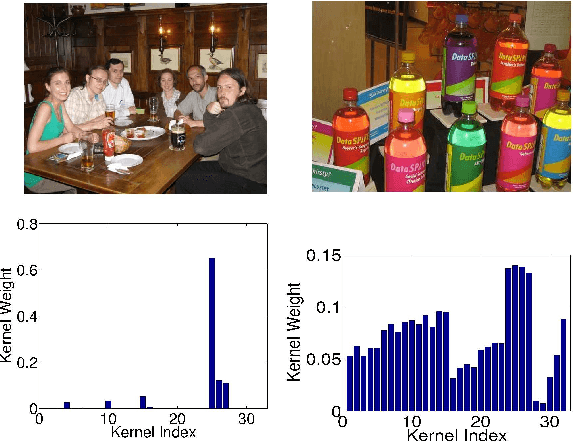
Combining information from various image features has become a standard technique in concept recognition tasks. However, the optimal way of fusing the resulting kernel functions is usually unknown in practical applications. Multiple kernel learning (MKL) techniques allow to determine an optimal linear combination of such similarity matrices. Classical approaches to MKL promote sparse mixtures. Unfortunately, so-called 1-norm MKL variants are often observed to be outperformed by an unweighted sum kernel. The contribution of this paper is twofold: We apply a recently developed non-sparse MKL variant to state-of-the-art concept recognition tasks within computer vision. We provide insights on benefits and limits of non-sparse MKL and compare it against its direct competitors, the sum kernel SVM and the sparse MKL. We report empirical results for the PASCAL VOC 2009 Classification and ImageCLEF2010 Photo Annotation challenge data sets. About to be submitted to PLoS ONE.
* 18 pages, 8 tables, 4 figures, format deviating from plos one submission format requirements for aesthetic reasons