 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convergence of Deep ReLU Networks
Jul 27, 2021
We explore convergence of deep neural networks with the popular ReLU activation function, as the depth of the networks tends to infinity. To this end, we introduce the notion of activation domains and activation matrices of a ReLU network. By replacing applications of the ReLU activation function by multiplications with activation matrices on activation domains, we obtain an explicit expression of the ReLU network. We then identify the convergence of the ReLU networks as convergence of a class of infinite products of matrices. Sufficient and necessary conditions for convergence of these infinite products of matrices are studied. As a result, we establish necessary conditions for ReLU networks to converge that the sequence of weight matrices converges to the identity matrix and the sequence of the bias vectors converges to zero as the depth of ReLU networks increases to infinity. Moreover, we obtain sufficient conditions in terms of the weight matrices and bias vectors at hidden layers for pointwise convergence of deep ReLU networks. These results provide mathematical insights to the design strategy of the well-known deep residual networks in image classification.
Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation
Aug 17, 2021
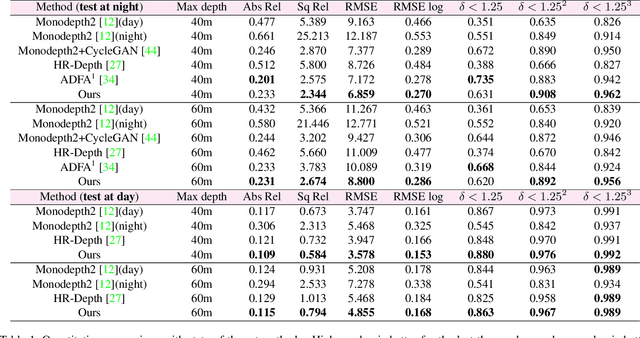
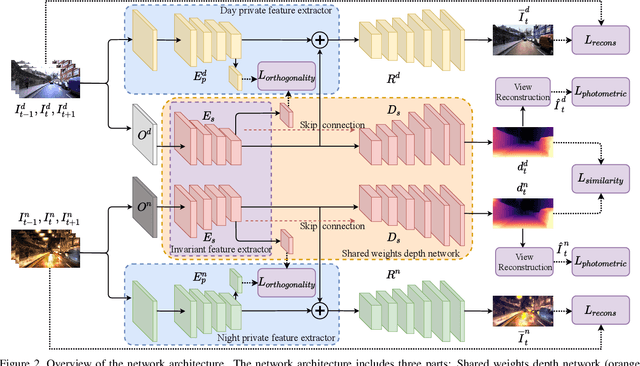
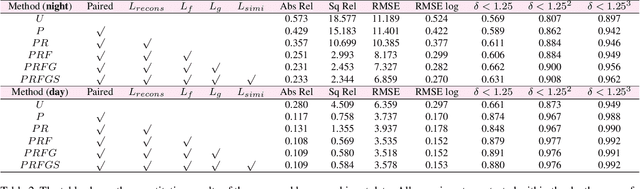
Remarkable results have been achieved by DCNN based self-supervised depth estimation approaches. However, most of these approaches can only handle either day-time or night-time images, while their performance degrades for all-day images due to large domain shift and the variation of illumination between day and night images. To relieve these limitations, we propose a domain-separated network for self-supervised depth estimation of all-day images. Specifically, to relieve the negative influence of disturbing terms (illumination, etc.), we partition the information of day and night image pairs into two complementary sub-spaces: private and invariant domains, where the former contains the unique information (illumination, etc.) of day and night images and the latter contains essential shared information (texture, etc.). Meanwhile, to guarantee that the day and night images contain the same information, the domain-separated network takes the day-time images and corresponding night-time images (generated by GAN) as input, and the private and invariant feature extractors are learned by orthogonality and similarity loss, where the domain gap can be alleviated, thus better depth maps can be expected. Meanwhile, the reconstruction and photometric losses are utilized to estimate complementary information and depth maps effectively. Experimental results demonstrate that our approach achieves state-of-the-art depth estimation results for all-day images on the challenging Oxford RobotCar dataset, proving the superiority of our proposed approach.
FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference
Mar 02, 2019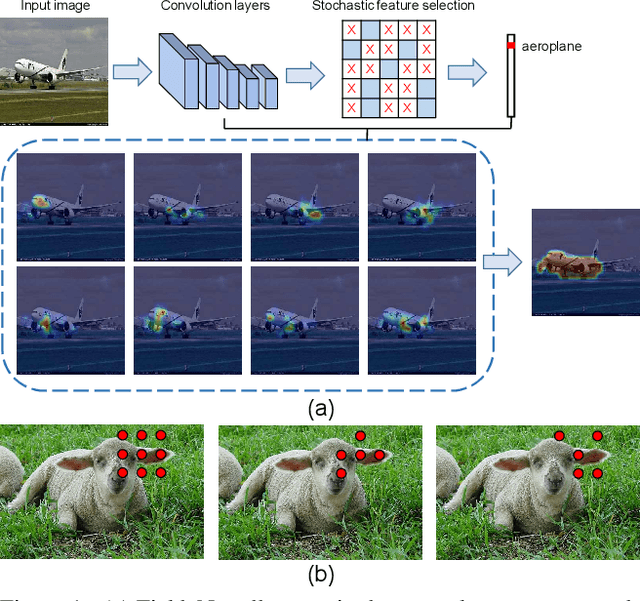
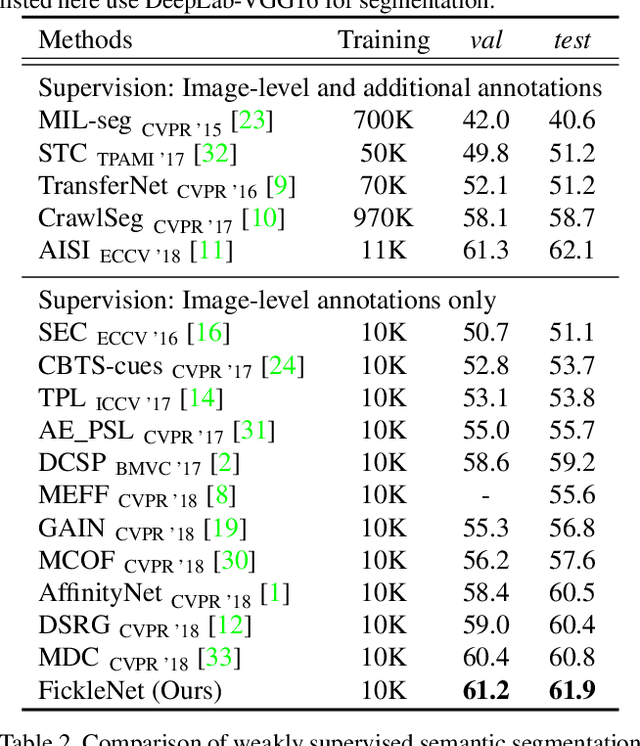
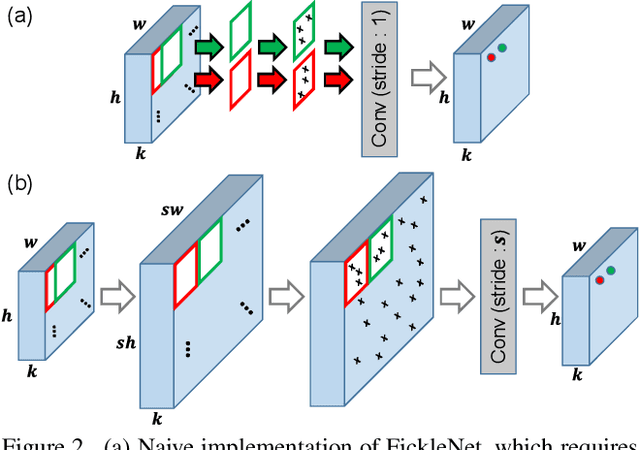

The main obstacle to weakly supervised semantic image segmentation is the difficulty of obtaining pixel-level information from coarse image-level annotations. Most methods based on image-level annotations use localization maps obtained from the classifier, but these only focus on the small discriminative parts of objects and do not capture precise boundaries. FickleNet explores diverse combinations of locations on feature maps created by generic deep neural networks. It selects hidden units randomly and then uses them to obtain activation scores for image classification. FickleNet implicitly learns the coherence of each location in the feature maps, resulting in a localization map which identifies both discriminative and other parts of objects. The ensemble effects are obtained from a single network by selecting random hidden unit pairs, which means that a variety of localization maps are generated from a single image. Our approach does not require any additional training steps and only adds a simple layer to a standard convolutional neural network; nevertheless it outperforms recent comparable techniques on the Pascal VOC 2012 benchmark in both weakly and semi-supervised settings.
Thinking Outside the Pool: Active Training Image Creation for Relative Attributes
Jan 08, 2019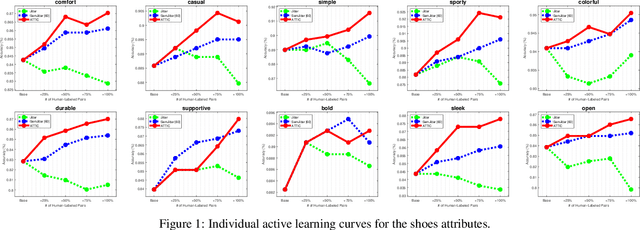
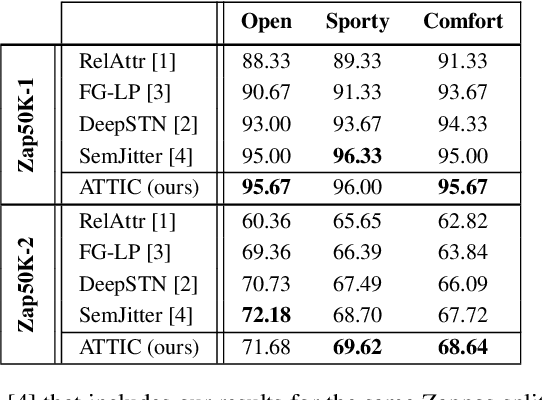
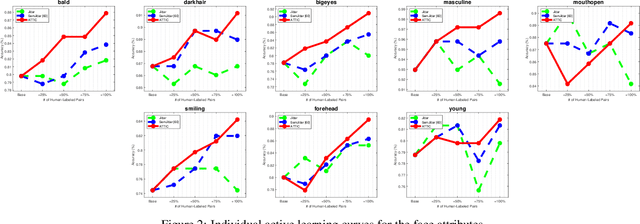

Current wisdom suggests more labeled image data is always better, and obtaining labels is the bottleneck. Yet curating a pool of sufficiently diverse and informative images is itself a challenge. In particular, training image curation is problematic for fine-grained attributes, where the subtle visual differences of interest may be rare within traditional image sources. We propose an active image generation approach to address this issue. The main idea is to jointly learn the attribute ranking task while also learning to generate novel realistic image samples that will benefit that task. We introduce an end-to-end framework that dynamically "imagines" image pairs that would confuse the current model, presents them to human annotators for labeling, then improves the predictive model with the new examples. With results on two datasets, we show that by thinking outside the pool of real images, our approach gains generalization accuracy for challenging fine-grained attribute comparisons.
On the Practicality of Deterministic Epistemic Uncertainty
Jul 13, 2021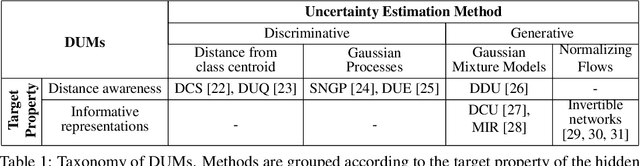
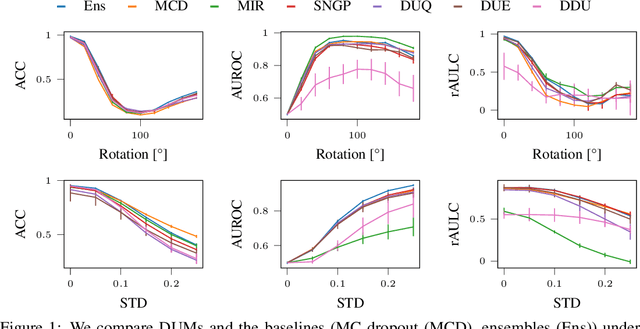
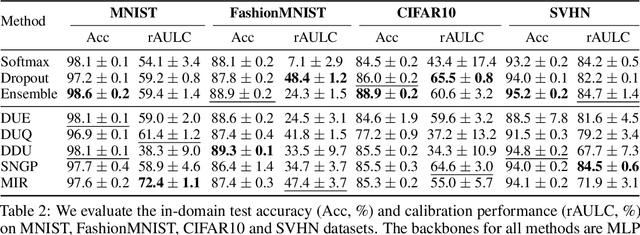
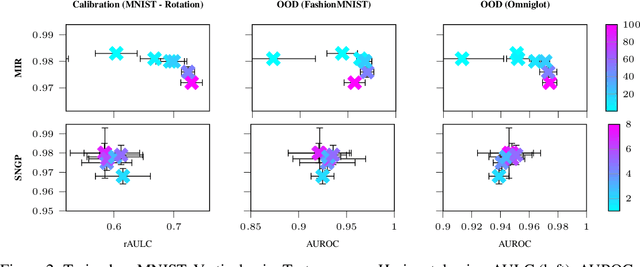
A set of novel approaches for estimating epistemic uncertainty in deep neural networks with a single forward pass has recently emerged as a valid alternative to Bayesian Neural Networks. On the premise of informative representations, these deterministic uncertainty methods (DUMs) achieve strong performance on detecting out-of-distribution (OOD) data while adding negligible computational costs at inference time. However, it remains unclear whether DUMs are well calibrated and can seamlessly scale to real-world applications - both prerequisites for their practical deployment. To this end, we first provide a taxonomy of DUMs, evaluate their calibration under continuous distributional shifts and their performance on OOD detection for image classification tasks. Then, we extend the most promising approaches to semantic segmentation. We find that, while DUMs scale to realistic vision tasks and perform well on OOD detection, the practicality of current methods is undermined by poor calibration under realistic distributional shifts.
Vision Transformer with Progressive Sampling
Aug 03, 2021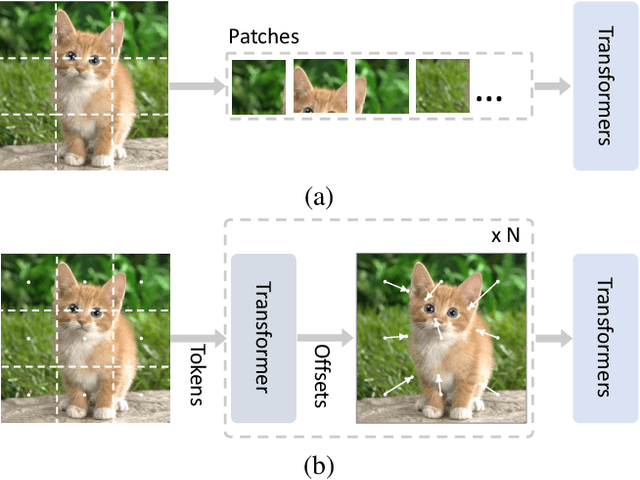
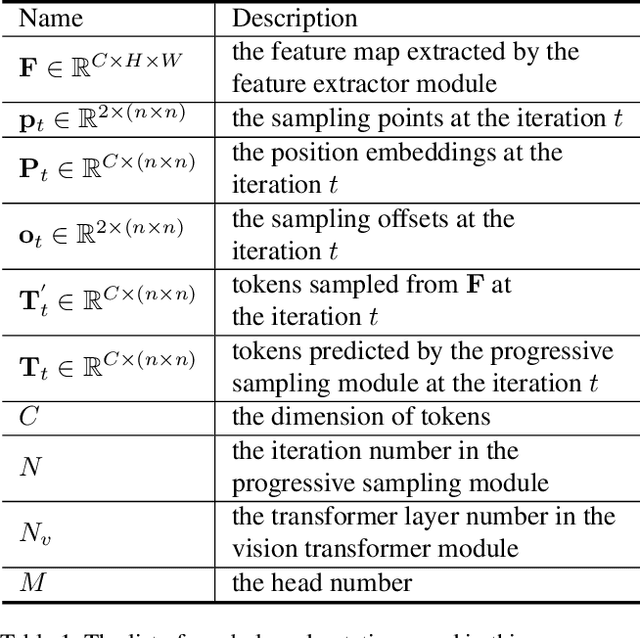
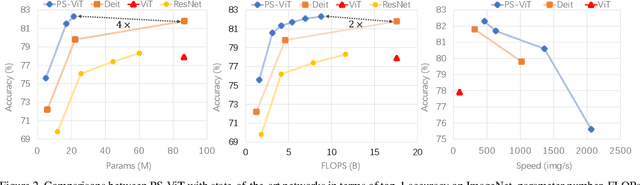
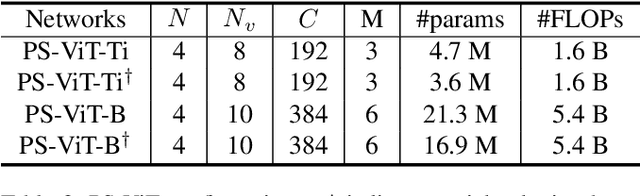
Transformers with powerful global relation modeling abilities have been introduced to fundamental computer vision tasks recently. As a typical example, the Vision Transformer (ViT) directly applies a pure transformer architecture on image classification, by simply splitting images into tokens with a fixed length, and employing transformers to learn relations between these tokens. However, such naive tokenization could destruct object structures, assign grids to uninterested regions such as background, and introduce interference signals. To mitigate the above issues, in this paper, we propose an iterative and progressive sampling strategy to locate discriminative regions. At each iteration, embeddings of the current sampling step are fed into a transformer encoder layer, and a group of sampling offsets is predicted to update the sampling locations for the next step. The progressive sampling is differentiable. When combined with the Vision Transformer, the obtained PS-ViT network can adaptively learn where to look. The proposed PS-ViT is both effective and efficient. When trained from scratch on ImageNet, PS-ViT performs 3.8% higher than the vanilla ViT in terms of top-1 accuracy with about $4\times$ fewer parameters and $10\times$ fewer FLOPs. Code is available at https://github.com/yuexy/PS-ViT.
Unsupervised Domain Adaptation for Image Classification via Structure-Conditioned Adversarial Learning
Mar 04, 2021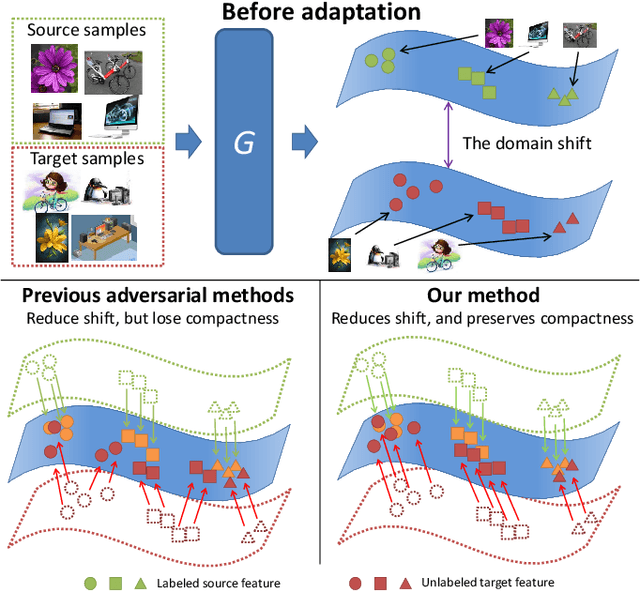
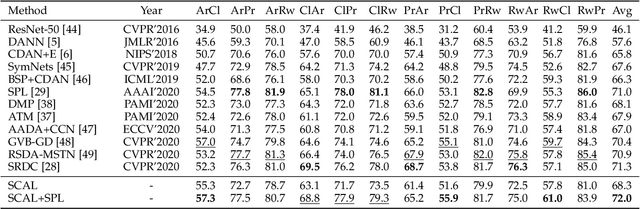
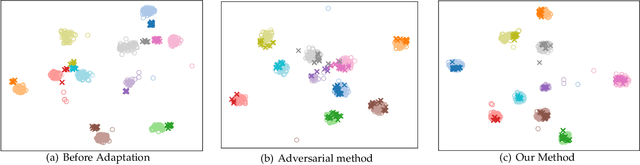
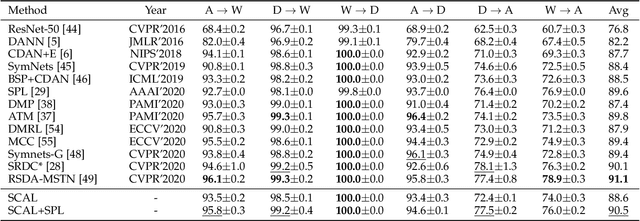
Unsupervised domain adaptation (UDA) typically carries out knowledge transfer from a label-rich source domain to an unlabeled target domain by adversarial learning. In principle, existing UDA approaches mainly focus on the global distribution alignment between domains while ignoring the intrinsic local distribution properties. Motivated by this observation, we propose an end-to-end structure-conditioned adversarial learning scheme (SCAL) that is able to preserve the intra-class compactness during domain distribution alignment. By using local structures as structure-aware conditions, the proposed scheme is implemented in a structure-conditioned adversarial learning pipeline. The above learning procedure is iteratively performed by alternating between local structures establishment and structure-conditioned adversarial learning. Experimental results demonstrate the effectiveness of the proposed scheme in UDA scenarios.
NeRD: Neural Reflectance Decomposition from Image Collections
Dec 08, 2020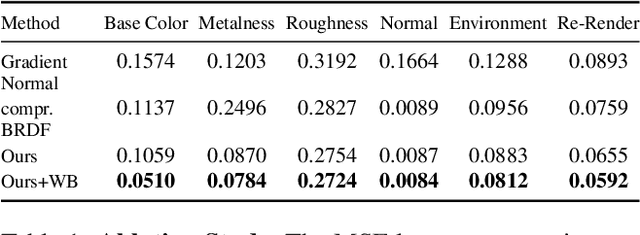
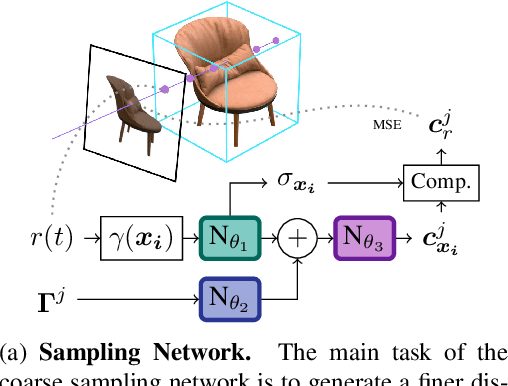
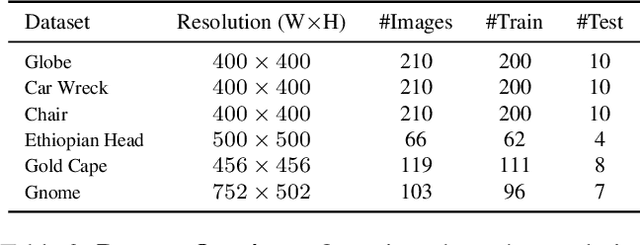

Decomposing a scene into its shape, reflectance, and illumination is a challenging but essential problem in computer vision and graphics. This problem is inherently more challenging when the illumination is not a single light source under laboratory conditions but is instead an unconstrained environmental illumination. Though recent work has shown that implicit representations can be used to model the radiance field of an object, these techniques only enable view synthesis and not relighting. Additionally, evaluating these radiance fields is resource and time-intensive. By decomposing a scene into explicit representations, any rendering framework can be leveraged to generate novel views under any illumination in real-time. NeRD is a method that achieves this decomposition by introducing physically-based rendering to neural radiance fields. Even challenging non-Lambertian reflectances, complex geometry, and unknown illumination can be decomposed to high-quality models. The datasets and code is available at the project page: https://markboss.me/publication/2021-nerd/
Deep Direct Volume Rendering: Learning Visual Feature Mappings From Exemplary Images
Jun 09, 2021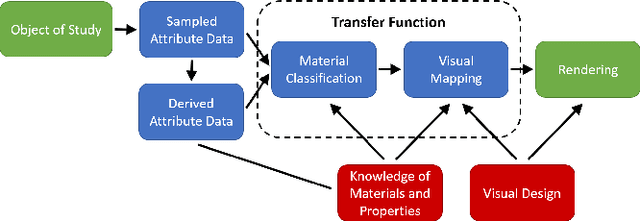
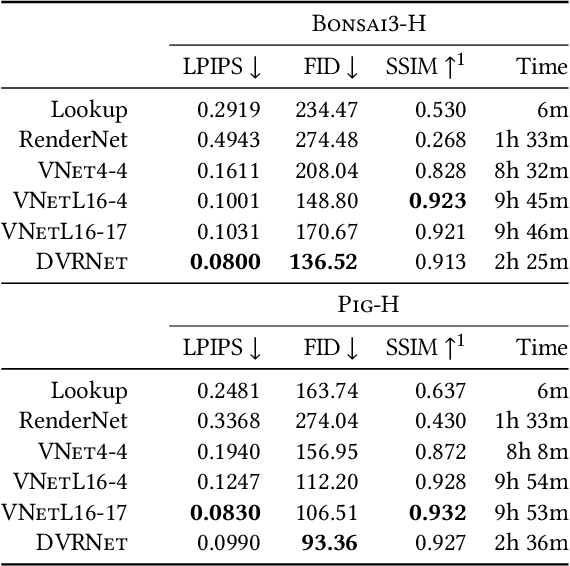
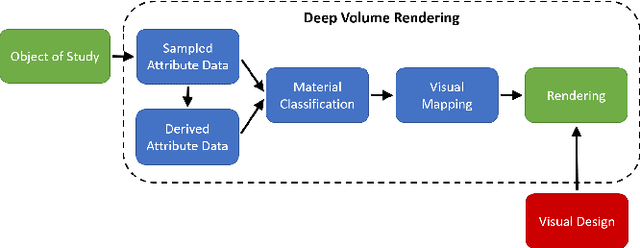
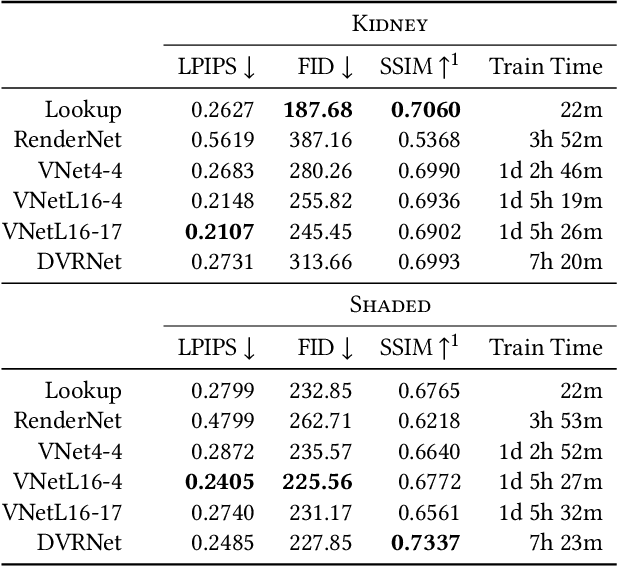
Volume Rendering is an important technique for visualizing three-dimensional scalar data grids and is commonly employed for scientific and medical image data. Direct Volume Rendering (DVR) is a well established and efficient rendering algorithm for volumetric data. Neural rendering uses deep neural networks to solve inverse rendering tasks and applies techniques similar to DVR. However, it has not been demonstrated successfully for the rendering of scientific volume data. In this work, we introduce Deep Direct Volume Rendering (DeepDVR), a generalization of DVR that allows for the integration of deep neural networks into the DVR algorithm. We conceptualize the rendering in a latent color space, thus enabling the use of deep architectures to learn implicit mappings for feature extraction and classification, replacing explicit feature design and hand-crafted transfer functions. Our generalization serves to derive novel volume rendering architectures that can be trained end-to-end directly from examples in image space, obviating the need to manually define and fine-tune multidimensional transfer functions while providing superior classification strength. We further introduce a novel stepsize annealing scheme to accelerate the training of DeepDVR models and validate its effectiveness in a set of experiments. We validate our architectures on two example use cases: (1) learning an optimized rendering from manually adjusted reference images for a single volume and (2) learning advanced visualization concepts like shading and semantic colorization that generalize to unseen volume data. We find that deep volume rendering architectures with explicit modeling of the DVR pipeline effectively enable end-to-end learning of scientific volume rendering tasks from target images.
Meta-repository of screening mammography classifiers
Aug 10, 2021
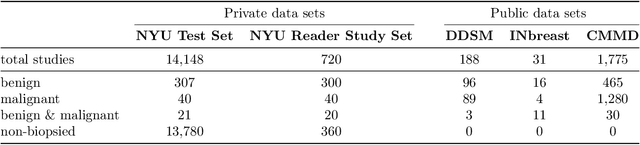
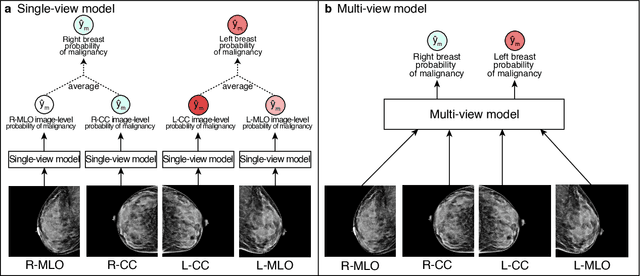
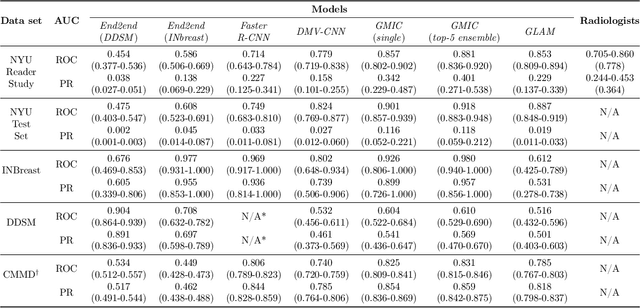
Artificial intelligence (AI) is transforming medicine and showing promise in improving clinical diagnosis. In breast cancer screening, several recent studies show that AI has the potential to improve radiologists' accuracy, subsequently helping in early cancer diagnosis and reducing unnecessary workup. As the number of proposed models and their complexity grows, it is becoming increasingly difficult to re-implement them in order to reproduce the results and to compare different approaches. To enable reproducibility of research in this application area and to enable comparison between different methods, we release a meta-repository containing deep learning models for classification of screening mammograms. This meta-repository creates a framework that enables the evaluation of machine learning models on any private or public screening mammography data set. At its inception, our meta-repository contains five state-of-the-art models with open-source implementations and cross-platform compatibility. We compare their performance on five international data sets: two private New York University breast cancer screening data sets as well as three public (DDSM, INbreast and Chinese Mammography Database) data sets. Our framework has a flexible design that can be generalized to other medical image analysis tasks. The meta-repository is available at https://www.github.com/nyukat/mammography_metarepository.