 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxisGuide: Grounding Robot Action Coordinate System in RGB Observations for Robust Visuomotor Manipulation
Jun 04, 2026Visuomotor manipulation policies trained via large-scale behavior cloning have achieved strong semantic scene understanding, yet often fail to reliably execute correct low-level actions under distribution shifts. For example, even in a simple pickup task with identical scene layouts, camera viewpoints, and illumination, performance can degrade substantially when the object is placed at unseen locations. We argue that this gap arises from insufficient action understanding, namely the inability to interpret the robot's base-frame action coordinate system in image space. To address this issue, we introduce AxisGuide, a lightweight guidance method that bridges semantic scene understanding and action-coordinate interpretation. Using camera parameters and end-effector poses, AxisGuide renders the robot base-frame axes in each camera view and augments RGB observations with a small set of cue channels that explicitly visualize the meaning of the +x, +y, and +z motions in image space. Extensive evaluations in both the LIBERO simulation and real-world environments demonstrate that AxisGuide yields substantial performance gains and improved generalization, highlighting the effectiveness of explicit action-coordinate cues for learning reliable and transferable generalist visuomotor policies.
Diagnosing and Correcting Concept Omission in Multimodal Diffusion Transformers
May 14, 2026Multimodal Diffusion Transformers (MM-DiTs) have achieved remarkable progress in text-to-image generation, yet they frequently suffer from concept omission, where specified objects or attributes fail to emerge in the generated image. By performing linear probing on text tokens, we demonstrate that text embeddings can distinguish a characteristic `omission signal' representing the absence of target concepts. Leveraging this insight, we propose Omission Signal Intervention (OSI), which amplifies the omission signal to actively catalyze the generation of missing concepts. Comprehensive experiments on FLUX.1-Dev and SD3.5-Medium demonstrate that OSI significantly alleviates concept omission even in extreme scenarios.
Causality-Aware End-to-End Autonomous Driving via Ego-Centric Joint Scene Modeling
May 13, 2026End-to-end autonomous driving, which bypasses traditional modular pipelines by directly predicting future trajectories from sensor inputs, has recently achieved substantial progress. However, existing methods often overlook the causal inter-dependencies in ego-vehicle planning, ignoring the reciprocal relations between the ego vehicle and surrounding agents. This causal oversight leads to inconsistent and unreliable trajectory predictions, especially in interaction-critical scenarios where ego decisions and neighboring agent behaviors must be reasoned about jointly. To address this limitation, we propose CaAD, a Causality-aware end-to-end Autonomous Driving framework that captures these dependencies within a shared latent scene representation. First, we propose a ego-centric joint-causal modeling module that builds on the marginal prediction branch, and learns causal dependencies between the ego vehicle and interaction-relevant agents. Second, we employ a causality-aware policy alignment stage implemented with joint-mode embeddings to align the stochastic ego policy with planning-oriented closed-loop feedback computed from surrounding traffic and map context. On the Bench2Drive and NAVSIM benchmarks, CaAD demonstrates strong closed-loop planning performance, achieving a Driving Score of 87.53 and Success Rate of 71.81 on Bench2Drive, and a PDMS of 91.1 on NAVSIM.
SpatiO: Adaptive Test-Time Orchestration of Vision-Language Agents for Spatial Reasoning
Apr 23, 2026Understanding visual scenes requires not only recognizing objects but also reasoning about their spatial relationships. Unlike general vision-language tasks, spatial reasoning requires integrating multiple inductive biases, such as 2D appearance cues, depth signals, and geometric constraints, whose reliability varies across contexts. This suggests that effective spatial reasoning requires \emph{spatial adaptability}: the ability to flexibly coordinate different reasoning strategies depending on the input. However, most existing approaches rely on a single reasoning pipeline that implicitly learns a fixed spatial prior, limiting their ability to adapt under distribution changes. Multi-agent systems offer a promising alternative by aggregating diverse reasoning trajectories, but prior attempts in spatial reasoning primarily employ homogeneous agents, restricting the diversity of inductive biases they can leverage. In this work, we introduce \textbf{\textsc{SpatiO}}, a heterogeneous multi-agent framework for spatial reasoning that coordinates multiple vision-language specialists with complementary inductive biases. To enable effective collaboration, we propose \textbf{Test-Time Orchestration (TTO)}, an optimization mechanism that dynamically evaluates and reweights agents based on their observed reliability during inference, without modifying model parameters. Extensive experiments on diverse spatial reasoning benchmarks, including 3DSRBench, STVQA-7k, CV-Bench, and Omni3D-Bench, demonstrate that \textsc{SpatiO} consistently improves spatial reasoning performance over both closed-source and open-source baselines.
FlowFixer: Towards Detail-Preserving Subject-Driven Generation
Feb 24, 2026We present FlowFixer, a refinement framework for subject-driven generation (SDG) that restores fine details lost during generation caused by changes in scale and perspective of a subject. FlowFixer proposes direct image-to-image translation from visual references, avoiding ambiguities in language prompts. To enable image-to-image training, we introduce a one-step denoising scheme to generate self-supervised training data, which automatically removes high-frequency details while preserving global structure, effectively simulating real-world SDG errors. We further propose a keypoint matching-based metric to properly assess fidelity in details beyond semantic similarities usually measured by CLIP or DINO. Experimental results demonstrate that FlowFixer outperforms state-of-the-art SDG methods in both qualitative and quantitative evaluations, setting a new benchmark for high-fidelity subject-driven generation.
Know "No" Better: A Data-Driven Approach for Enhancing Negation Awareness in CLIP
Jan 19, 2025While CLIP has significantly advanced multimodal understanding by bridging vision and language, the inability to grasp negation - such as failing to differentiate concepts like "parking" from "no parking" - poses substantial challenges. By analyzing the data used in the public CLIP model's pre-training, we posit this limitation stems from a lack of negation-inclusive data. To address this, we introduce data generation pipelines that employ a large language model (LLM) and a multimodal LLM to produce negation-inclusive captions. Fine-tuning CLIP with data generated from our pipelines, we develop NegationCLIP, which enhances negation awareness while preserving the generality. Moreover, to enable a comprehensive evaluation of negation understanding, we propose NegRefCOCOg-a benchmark tailored to test VLMs' ability to interpret negation across diverse expressions and positions within a sentence. Experiments on various CLIP architectures validate the effectiveness of our data generation pipelines in enhancing CLIP's ability to perceive negation accurately. Additionally, NegationCLIP's enhanced negation awareness has practical applications across various multimodal tasks, demonstrated by performance gains in text-to-image generation and referring image segmentation.
Toward Interactive Regional Understanding in Vision-Large Language Models
Mar 27, 2024



Recent Vision-Language Pre-training (VLP) models have demonstrated significant advancements. Nevertheless, these models heavily rely on image-text pairs that capture only coarse and global information of an image, leading to a limitation in their regional understanding ability. In this work, we introduce \textbf{RegionVLM}, equipped with explicit regional modeling capabilities, allowing them to understand user-indicated image regions. To achieve this, we design a simple yet innovative architecture, requiring no modifications to the model architecture or objective function. Additionally, we leverage a dataset that contains a novel source of information, namely Localized Narratives, which has been overlooked in previous VLP research. Our experiments demonstrate that our single generalist model not only achieves an interactive dialogue system but also exhibits superior performance on various zero-shot region understanding tasks, without compromising its ability for global image understanding.
Improving Visual Prompt Tuning for Self-supervised Vision Transformers
Jun 08, 2023



Visual Prompt Tuning (VPT) is an effective tuning method for adapting pretrained Vision Transformers (ViTs) to downstream tasks. It leverages extra learnable tokens, known as prompts, which steer the frozen pretrained ViTs. Although VPT has demonstrated its applicability with supervised vision transformers, it often underperforms with self-supervised ones. Through empirical observations, we deduce that the effectiveness of VPT hinges largely on the ViT blocks with which the prompt tokens interact. Specifically, VPT shows improved performance on image classification tasks for MAE and MoCo v3 when the prompt tokens are inserted into later blocks rather than the first block. These observations suggest that there exists an optimal location of blocks for the insertion of prompt tokens. Unfortunately, identifying the optimal blocks for prompts within each self-supervised ViT for diverse future scenarios is a costly process. To mitigate this problem, we propose a simple yet effective method that learns a gate for each ViT block to adjust its intervention into the prompt tokens. With our method, prompt tokens are selectively influenced by blocks that require steering for task adaptation. Our method outperforms VPT variants in FGVC and VTAB image classification and ADE20K semantic segmentation. The code is available at https://github.com/ryongithub/GatedPromptTuning.
Anti-Adversarially Manipulated Attributions for Weakly Supervised Semantic Segmentation and Object Localization
Apr 11, 2022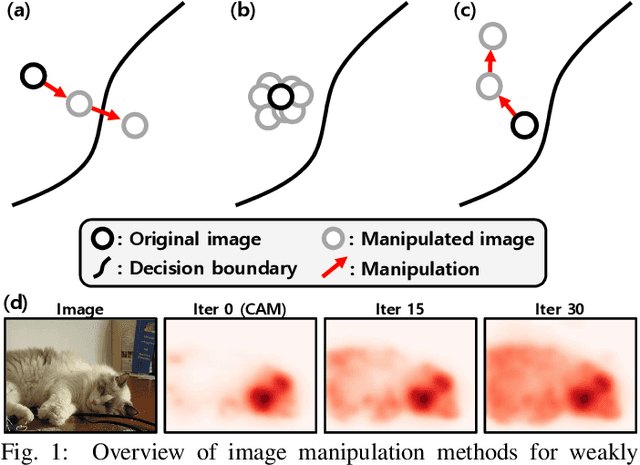
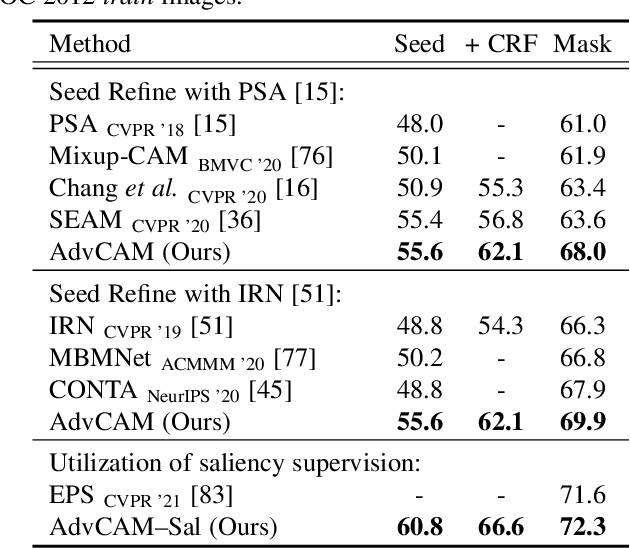
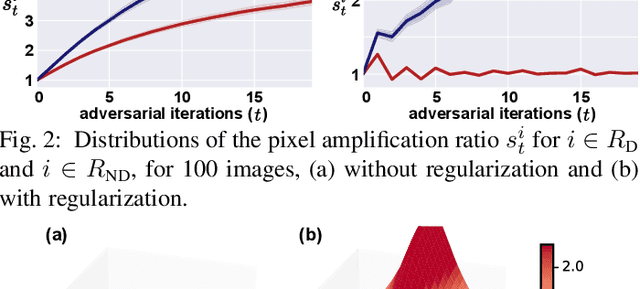

Obtaining accurate pixel-level localization from class labels is a crucial process in weakly supervised semantic segmentation and object localization. Attribution maps from a trained classifier are widely used to provide pixel-level localization, but their focus tends to be restricted to a small discriminative region of the target object. An AdvCAM is an attribution map of an image that is manipulated to increase the classification score produced by a classifier before the final softmax or sigmoid layer. This manipulation is realized in an anti-adversarial manner, so that the original image is perturbed along pixel gradients in directions opposite to those used in an adversarial attack. This process enhances non-discriminative yet class-relevant features, which make an insufficient contribution to previous attribution maps, so that the resulting AdvCAM identifies more regions of the target object. In addition, we introduce a new regularization procedure that inhibits the incorrect attribution of regions unrelated to the target object and the excessive concentration of attributions on a small region of the target object. Our method achieves a new state-of-the-art performance in weakly and semi-supervised semantic segmentation, on both the PASCAL VOC 2012 and MS COCO 2014 datasets. In weakly supervised object localization, it achieves a new state-of-the-art performance on the CUB-200-2011 and ImageNet-1K datasets.
Perception Prioritized Training of Diffusion Models
Apr 01, 2022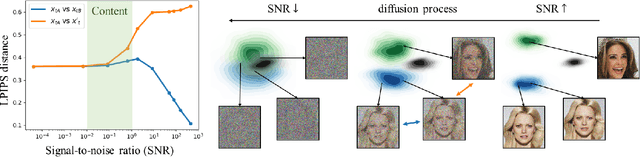
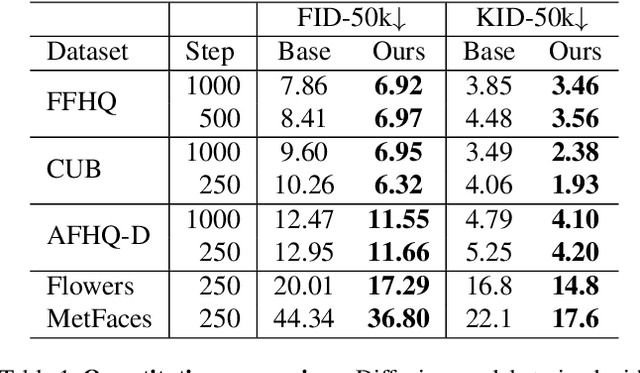

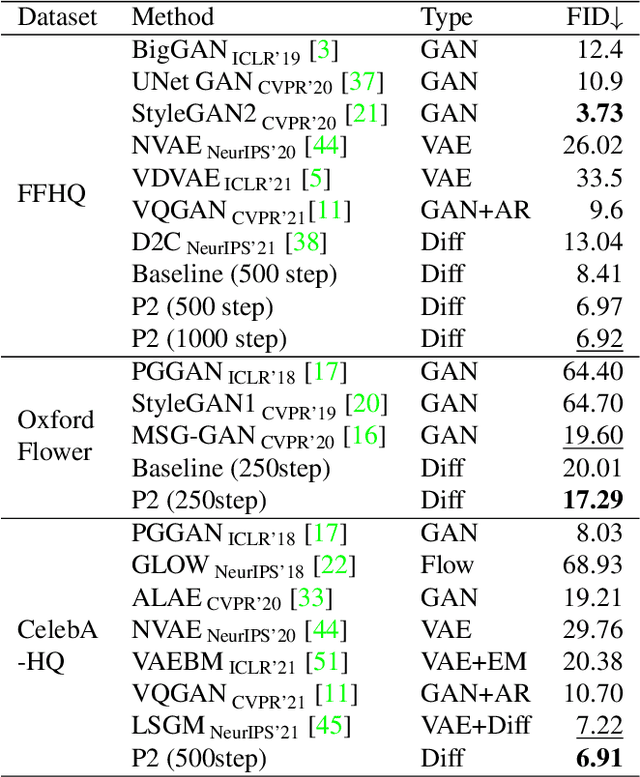
Diffusion models learn to restore noisy data, which is corrupted with different levels of noise, by optimizing the weighted sum of the corresponding loss terms, i.e., denoising score matching loss. In this paper, we show that restoring data corrupted with certain noise levels offers a proper pretext task for the model to learn rich visual concepts. We propose to prioritize such noise levels over other levels during training, by redesigning the weighting scheme of the objective function. We show that our simple redesign of the weighting scheme significantly improves the performance of diffusion models regardless of the datasets, architectures, and sampling strategies.