 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Outside the Pool: Active Training Image Creation for Relative Attributes
Jan 08, 2019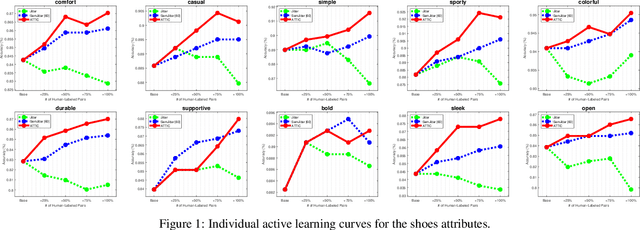
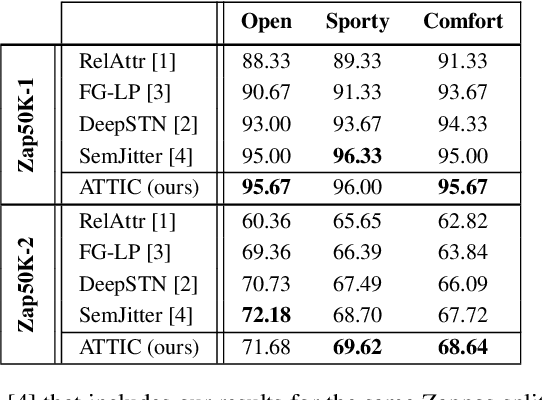

Current wisdom suggests more labeled image data is always better, and obtaining labels is the bottleneck. Yet curating a pool of sufficiently diverse and informative images is itself a challenge. In particular, training image curation is problematic for fine-grained attributes, where the subtle visual differences of interest may be rare within traditional image sources. We propose an active image generation approach to address this issue. The main idea is to jointly learn the attribute ranking task while also learning to generate novel realistic image samples that will benefit that task. We introduce an end-to-end framework that dynamically "imagines" image pairs that would confuse the current model, presents them to human annotators for labeling, then improves the predictive model with the new examples. With results on two datasets, we show that by thinking outside the pool of real images, our approach gains generalization accuracy for challenging fine-grained attribute comparisons.
Semantic Jitter: Dense Supervision for Visual Comparisons via Synthetic Images
Apr 27, 2017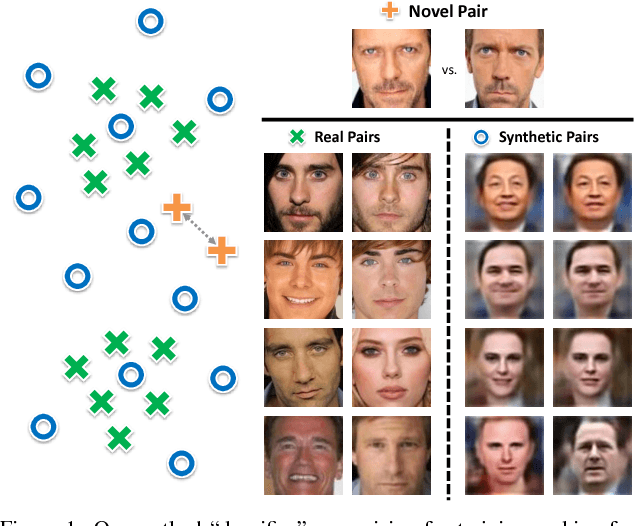
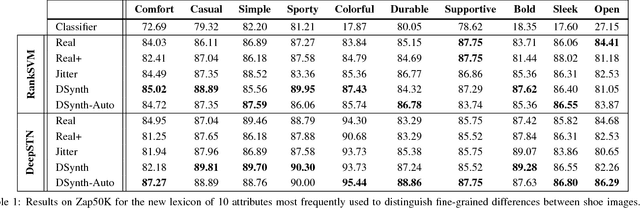
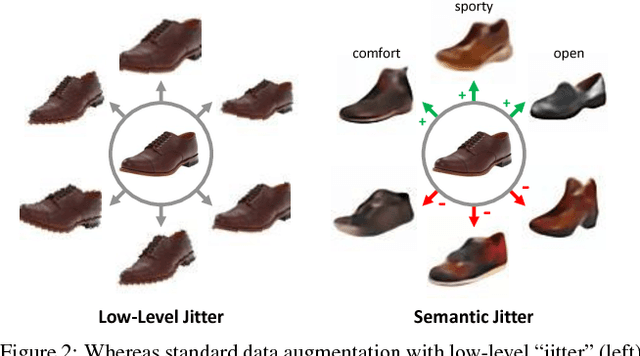
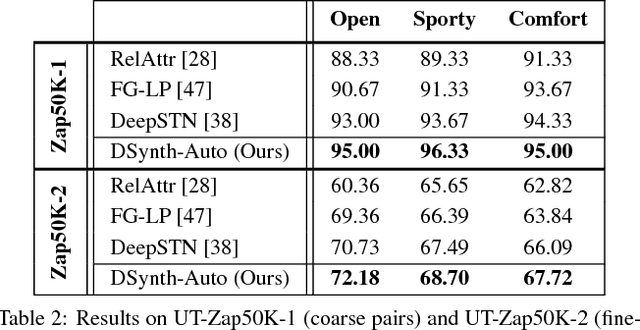
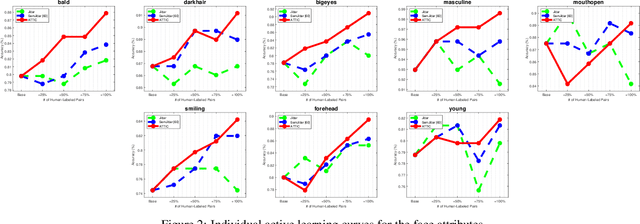
Distinguishing subtle differences in attributes is valuable, yet learning to make visual comparisons remains non-trivial. Not only is the number of possible comparisons quadratic in the number of training images, but also access to images adequately spanning the space of fine-grained visual differences is limited. We propose to overcome the sparsity of supervision problem via synthetically generated images. Building on a state-of-the-art image generation engine, we sample pairs of training images exhibiting slight modifications of individual attributes. Augmenting real training image pairs with these examples, we then train attribute ranking models to predict the relative strength of an attribute in novel pairs of real images. Our results on datasets of faces and fashion images show the great promise of bootstrapping imperfect image generators to counteract sample sparsity for learning to rank.