 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Research on Mosaic Image Data Enhancement for Overlapping Ship Targets
May 11, 2021
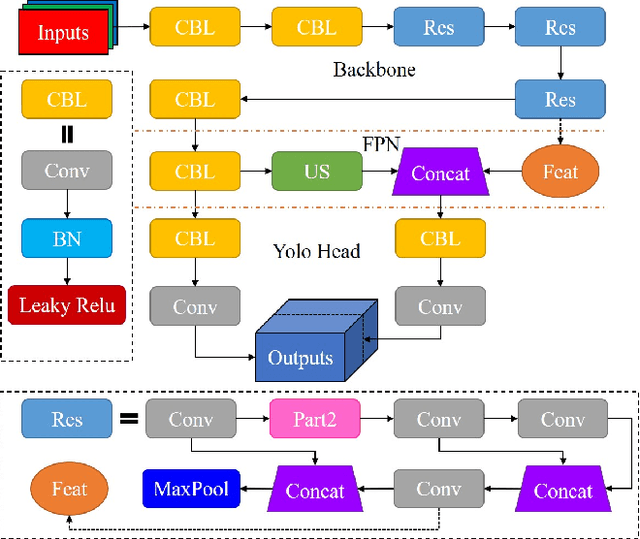

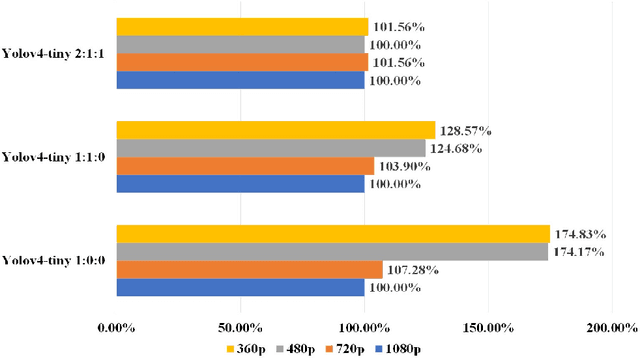
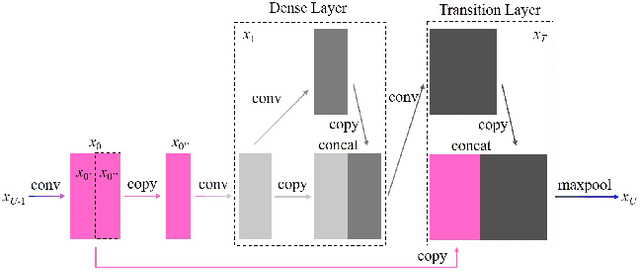
The problem of overlapping occlusion in target recognition has been a difficult research problem, and the situation of mutual occlusion of ship targets in narrow waters still exists. In this paper, an improved mosaic data enhancement method is proposed, which optimizes the reading method of the data set, strengthens the learning ability of the detection algorithm for local features, improves the recognition accuracy of overlapping targets while keeping the test speed unchanged, reduces the decay rate of recognition ability under different resolutions, and strengthens the robustness of the algorithm. The real test experiments prove that, relative to the original algorithm, the improved algorithm improves the recognition accuracy of overlapping targets by 2.5%, reduces the target loss time by 17%, and improves the recognition stability under different video resolutions by 27.01%.
On Circuit-based Hybrid Quantum Neural Networks for Remote Sensing Imagery Classification
Sep 20, 2021

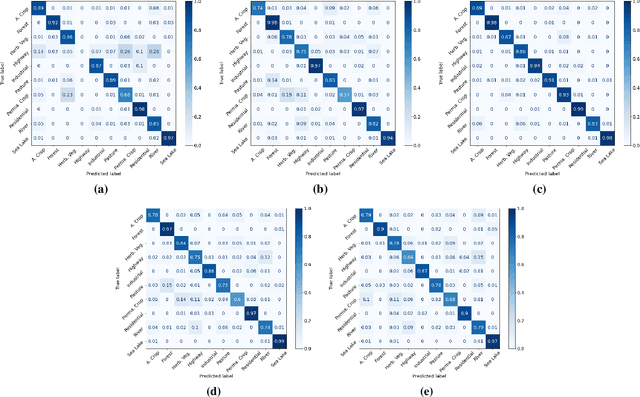
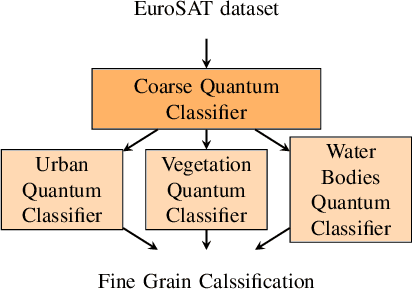
This article aims to investigate how circuit-based hybrid Quantum Convolutional Neural Networks (QCNNs) can be successfully employed as image classifiers in the context of remote sensing. The hybrid QCNNs enrich the classical architecture of CNNs by introducing a quantum layer within a standard neural network. The novel QCNN proposed in this work is applied to the Land Use and Land Cover (LULC) classification, chosen as an Earth Observation (EO) use case, and tested on the EuroSAT dataset used as reference benchmark. The results of the multiclass classification prove the effectiveness of the presented approach, by demonstrating that the QCNN performances are higher than the classical counterparts. Moreover, investigation of various quantum circuits shows that the ones exploiting quantum entanglement achieve the best classification scores. This study underlines the potentialities of applying quantum computing to an EO case study and provides the theoretical and experimental background for futures investigations.
Semi-supervised Cell Detection in Time-lapse Images Using Temporal Consistency
Jul 19, 2021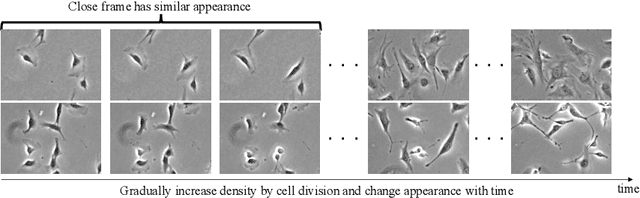
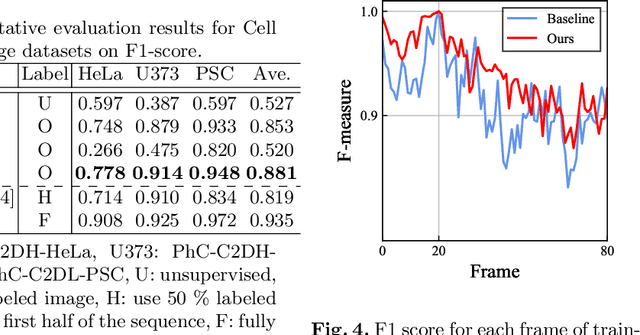
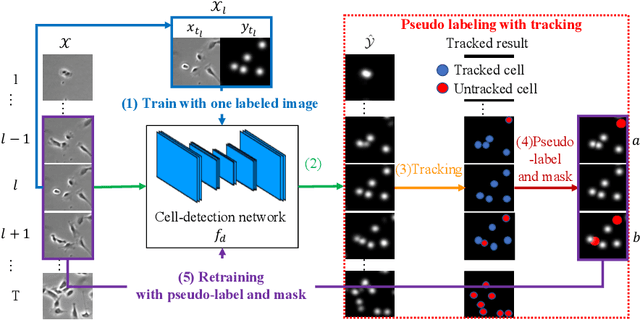
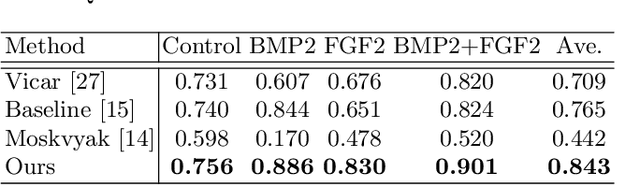
Cell detection is the task of detecting the approximate positions of cell centroids from microscopy images. Recently, convolutional neural network-based approaches have achieved promising performance. However, these methods require a certain amount of annotation for each imaging condition. This annotation is a time-consuming and labor-intensive task. To overcome this problem, we propose a semi-supervised cell-detection method that effectively uses a time-lapse sequence with one labeled image and the other images unlabeled. First, we train a cell-detection network with a one-labeled image and estimate the unlabeled images with the trained network. We then select high-confidence positions from the estimations by tracking the detected cells from the labeled frame to those far from it. Next, we generate pseudo-labels from the tracking results and train the network by using pseudo-labels. We evaluated our method for seven conditions of public datasets, and we achieved the best results relative to other semi-supervised methods. Our code is available at https://github.com/naivete5656/SCDTC
Going Beneath the Surface: Evaluating Image Captioning for Grammaticality, Truthfulness and Diversity
Dec 19, 2019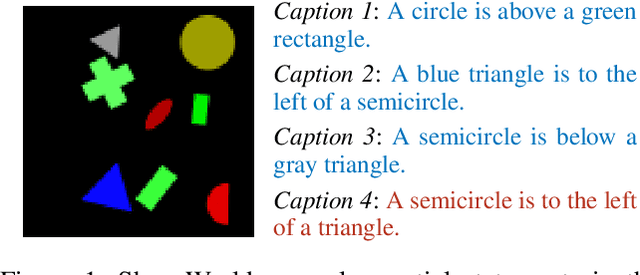
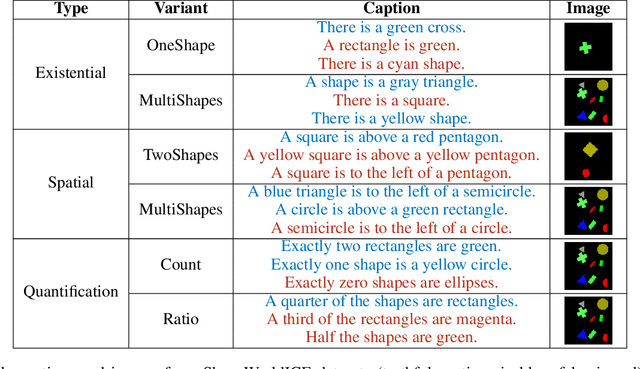
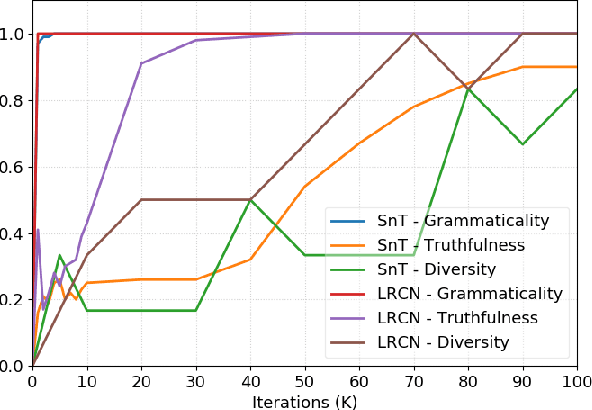
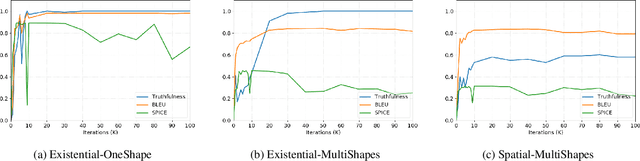
Image captioning as a multimodal task has drawn much interest in recent years. However, evaluation for this task remains a challenging problem. Existing evaluation metrics focus on surface similarity between a candidate caption and a set of reference captions, and do not check the actual relation between a caption and the underlying visual content. We introduce a new diagnostic evaluation framework for the task of image captioning, with the goal of directly assessing models for grammaticality, truthfulness and diversity (GTD) of generated captions. We demonstrate the potential of our evaluation framework by evaluating existing image captioning models on a wide ranging set of synthetic datasets that we construct for diagnostic evaluation. We empirically show how the GTD evaluation framework, in combination with diagnostic datasets, can provide insights into model capabilities and limitations to supplement standard evaluations.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021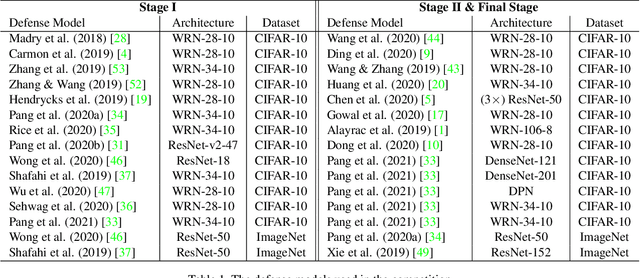
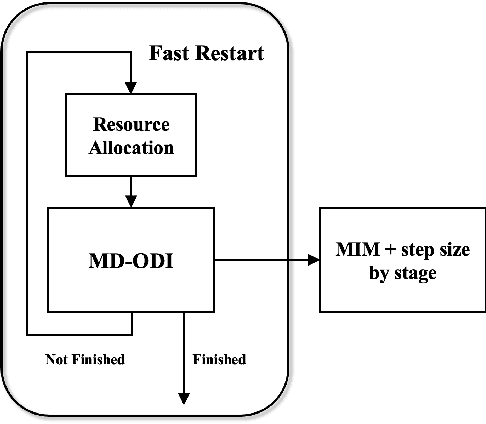
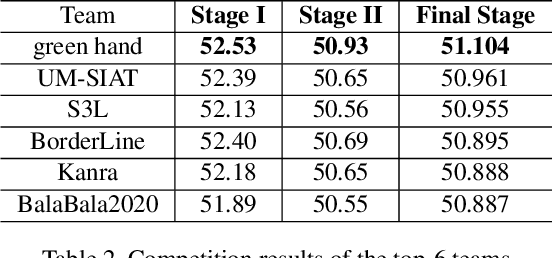
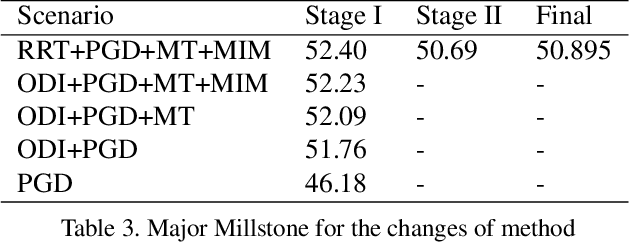
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.
Power Normalizations in Fine-grained Image, Few-shot Image and Graph Classification
Dec 27, 2020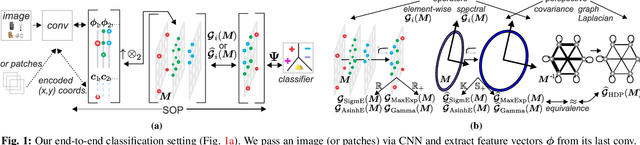
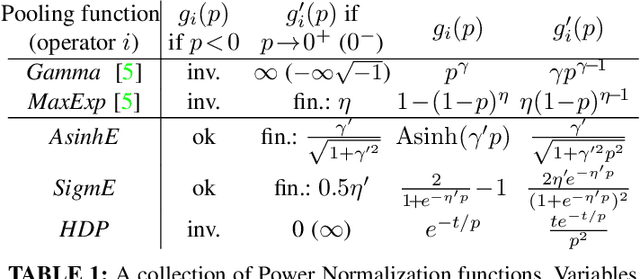
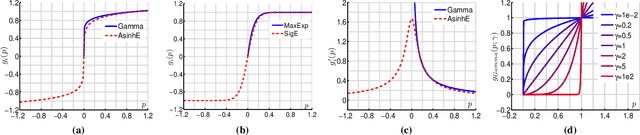

Power Normalizations (PN) are useful non-linear operators which tackle feature imbalances in classification problems. We study PNs in the deep learning setup via a novel PN layer pooling feature maps. Our layer combines the feature vectors and their respective spatial locations in the feature maps produced by the last convolutional layer of CNN into a positive definite matrix with second-order statistics to which PN operators are applied, forming so-called Second-order Pooling (SOP). As the main goal of this paper is to study Power Normalizations, we investigate the role and meaning of MaxExp and Gamma, two popular PN functions. To this end, we provide probabilistic interpretations of such element-wise operators and discover surrogates with well-behaved derivatives for end-to-end training. Furthermore, we look at the spectral applicability of MaxExp and Gamma by studying Spectral Power Normalizations (SPN). We show that SPN on the autocorrelation/covariance matrix and the Heat Diffusion Process (HDP) on a graph Laplacian matrix are closely related, thus sharing their properties. Such a finding leads us to the culmination of our work, a fast spectral MaxExp which is a variant of HDP for covariances/autocorrelation matrices. We evaluate our ideas on fine-grained recognition, scene recognition, and material classification, as well as in few-shot learning and graph classification.
EdgeFlow: Achieving Practical Interactive Segmentation with Edge-Guided Flow
Sep 20, 2021
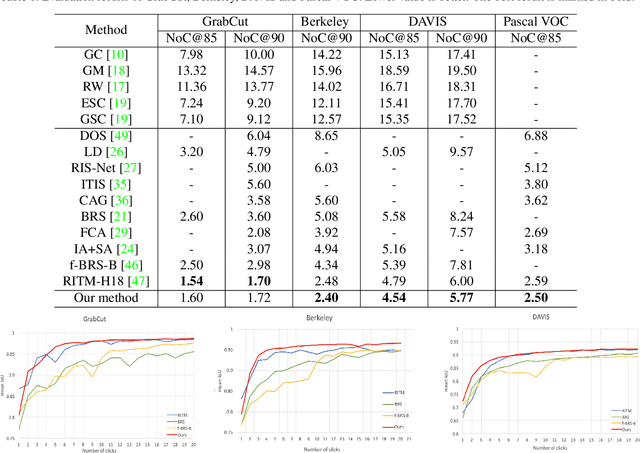
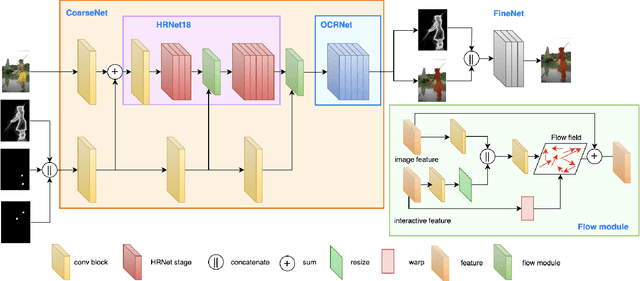

High-quality training data play a key role in image segmentation tasks. Usually, pixel-level annotations are expensive, laborious and time-consuming for the large volume of training data. To reduce labelling cost and improve segmentation quality, interactive segmentation methods have been proposed, which provide the result with just a few clicks. However, their performance does not meet the requirements of practical segmentation tasks in terms of speed and accuracy. In this work, we propose EdgeFlow, a novel architecture that fully utilizes interactive information of user clicks with edge-guided flow. Our method achieves state-of-the-art performance without any post-processing or iterative optimization scheme. Comprehensive experiments on benchmarks also demonstrate the superiority of our method. In addition, with the proposed method, we develop an efficient interactive segmentation tool for practical data annotation tasks. The source code and tool is avaliable at https://github.com/PaddlePaddle/PaddleSeg.
PSGAN++: Robust Detail-Preserving Makeup Transfer and Removal
May 26, 2021
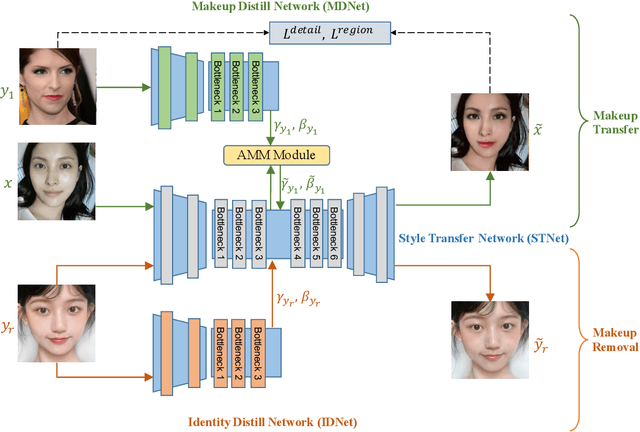
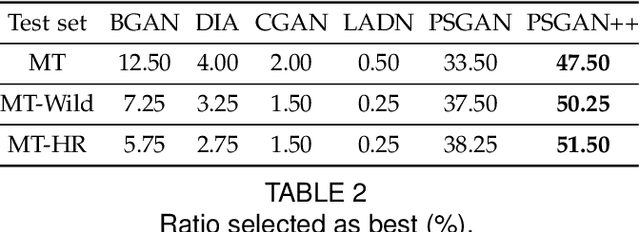
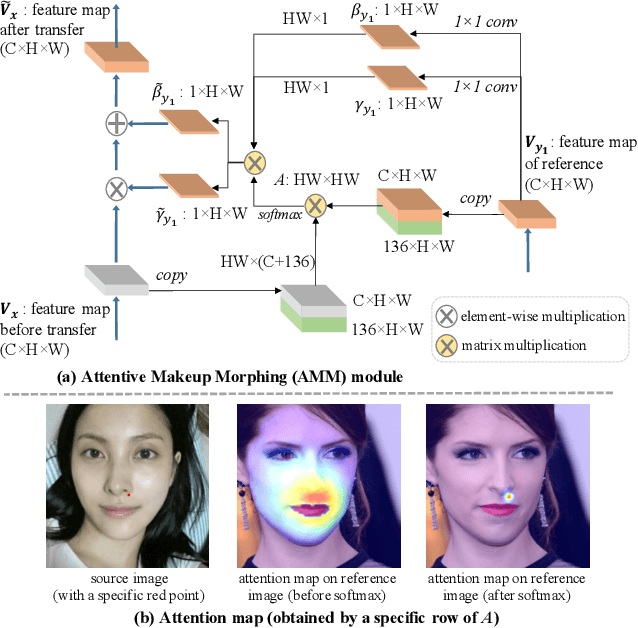
In this paper, we address the makeup transfer and removal tasks simultaneously, which aim to transfer the makeup from a reference image to a source image and remove the makeup from the with-makeup image respectively. Existing methods have achieved much advancement in constrained scenarios, but it is still very challenging for them to transfer makeup between images with large pose and expression differences, or handle makeup details like blush on cheeks or highlight on the nose. In addition, they are hardly able to control the degree of makeup during transferring or to transfer a specified part in the input face. In this work, we propose the PSGAN++, which is capable of performing both detail-preserving makeup transfer and effective makeup removal. For makeup transfer, PSGAN++ uses a Makeup Distill Network to extract makeup information, which is embedded into spatial-aware makeup matrices. We also devise an Attentive Makeup Morphing module that specifies how the makeup in the source image is morphed from the reference image, and a makeup detail loss to supervise the model within the selected makeup detail area. On the other hand, for makeup removal, PSGAN++ applies an Identity Distill Network to embed the identity information from with-makeup images into identity matrices. Finally, the obtained makeup/identity matrices are fed to a Style Transfer Network that is able to edit the feature maps to achieve makeup transfer or removal. To evaluate the effectiveness of our PSGAN++, we collect a Makeup Transfer In the Wild dataset that contains images with diverse poses and expressions and a Makeup Transfer High-Resolution dataset that contains high-resolution images. Experiments demonstrate that PSGAN++ not only achieves state-of-the-art results with fine makeup details even in cases of large pose/expression differences but also can perform partial or degree-controllable makeup transfer.
Hepatic vessel segmentation based on 3Dswin-transformer with inductive biased multi-head self-attention
Nov 05, 2021
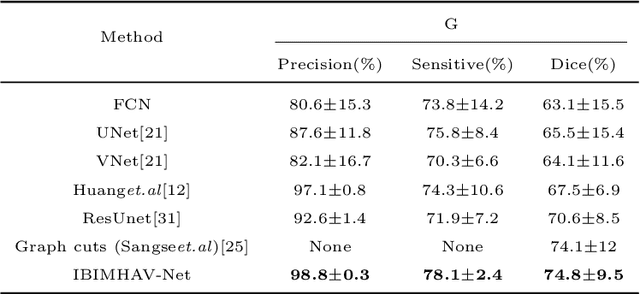
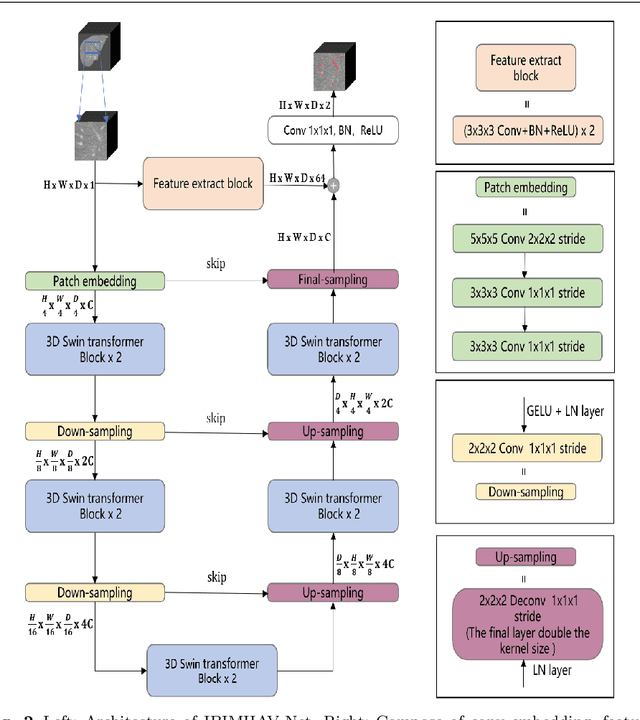
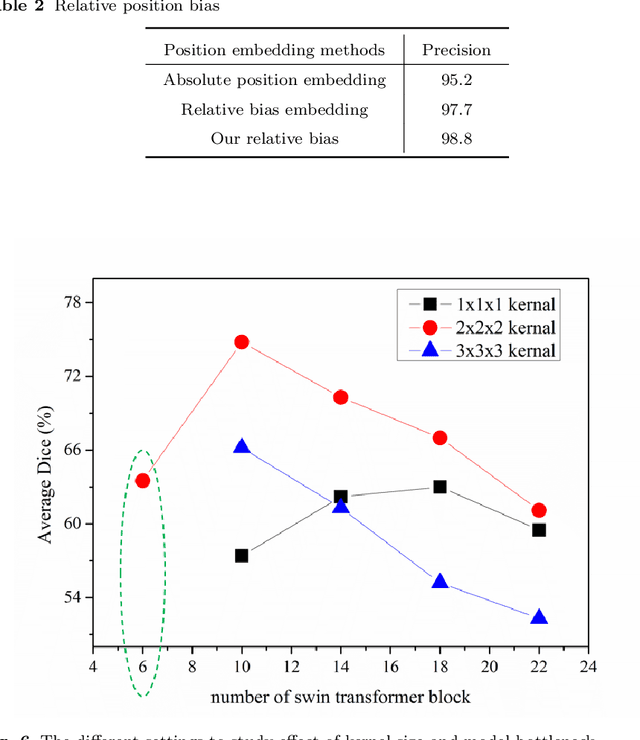
Purpose: Segmentation of liver vessels from CT images is indispensable prior to surgical planning and aroused broad range of interests in the medical image analysis community. Due to the complex structure and low contrast background, automatic liver vessel segmentation remains particularly challenging. Most of the related researches adopt FCN, U-net, and V-net variants as a backbone. However, these methods mainly focus on capturing multi-scale local features which may produce misclassified voxels due to the convolutional operator's limited locality reception field. Methods: We propose a robust end-to-end vessel segmentation network called Inductive BIased Multi-Head Attention Vessel Net(IBIMHAV-Net) by expanding swin transformer to 3D and employing an effective combination of convolution and self-attention. In practice, we introduce the voxel-wise embedding rather than patch-wise embedding to locate precise liver vessel voxels, and adopt multi-scale convolutional operators to gain local spatial information. On the other hand, we propose the inductive biased multi-head self-attention which learns inductive biased relative positional embedding from initialized absolute position embedding. Based on this, we can gain a more reliable query and key matrix. To validate the generalization of our model, we test on samples which have different structural complexity. Results: We conducted experiments on the 3DIRCADb datasets. The average dice and sensitivity of the four tested cases were 74.8% and 77.5%, which exceed results of existing deep learning methods and improved graph cuts method. Conclusion: The proposed model IBIMHAV-Net provides an automatic, accurate 3D liver vessel segmentation with an interleaved architecture that better utilizes both global and local spatial features in CT volumes. It can be further extended for other clinical data.
OneGAN: Simultaneous Unsupervised Learning of Conditional Image Generation, Foreground Segmentation, and Fine-Grained Clustering
Dec 31, 2019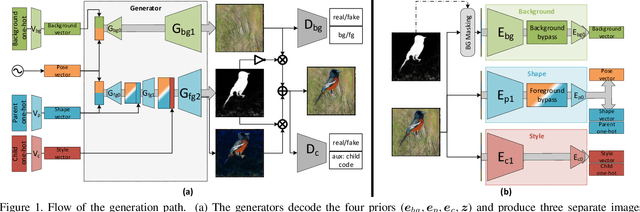
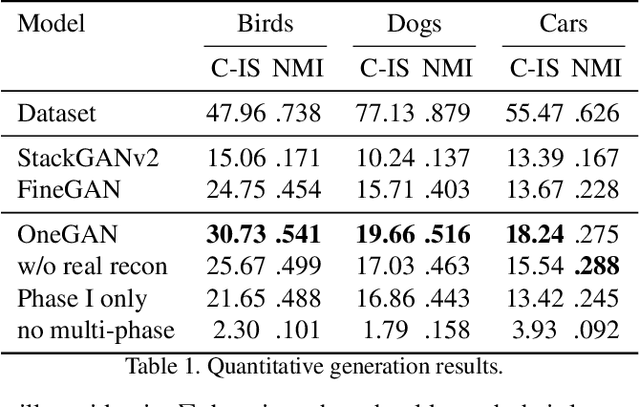
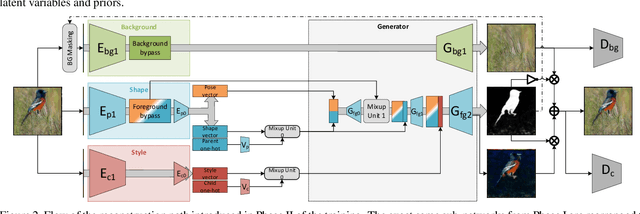
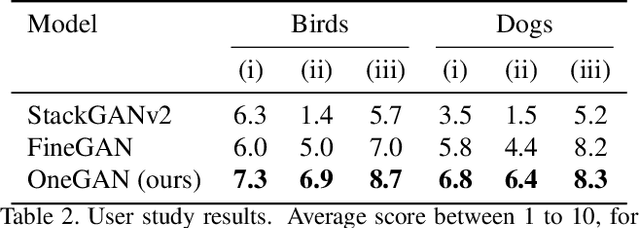
We present a method for simultaneously learning, in an unsupervised manner, (i) a conditional image generator, (ii) foreground extraction and segmentation, (iii) clustering into a two-level class hierarchy, and (iv) object removal and background completion, all done without any use of annotation. The method combines a generative adversarial network and a variational autoencoder, with multiple encoders, generators and discriminators, and benefits from solving all tasks at once. The input to the training scheme is a varied collection of unlabeled images from the same domain, as well as a set of background images without a foreground object. In addition, the image generator can mix the background from one image, with a foreground that is conditioned either on that of a second image or on the index of a desired cluster. The method obtains state of the art results in comparison to the literature methods, when compared to the current state of the art in each of the tasks.