 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentinel: Attention Probing of Proxy Models for LLM Context Compression with an Understanding Perspective
May 29, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with external context, but retrieved passages are often lengthy, noisy, or exceed input limits. Existing compression methods typically require supervised training of dedicated compression models, increasing cost and reducing portability. We propose Sentinel, a lightweight sentence-level compression framework that reframes context filtering as an attention-based understanding task. Rather than training a compression model, Sentinel probes decoder attention from an off-the-shelf 0.5B proxy LLM using a lightweight classifier to identify sentence relevance. Empirically, we find that query-context relevance estimation is consistent across model scales, with 0.5B proxies closely matching the behaviors of larger models. On the LongBench benchmark, Sentinel achieves up to 5$\times$ compression while matching the QA performance of 7B-scale compression systems. Our results suggest that probing native attention signals enables fast, effective, and question-aware context compression. Code available at: https://github.com/yzhangchuck/Sentinel.
CRAFT: Time Series Forecasting with Cross-Future Behavior Awareness
May 20, 2025The past decades witness the significant advancements in time series forecasting (TSF) across various real-world domains, including e-commerce and disease spread prediction. However, TSF is usually constrained by the uncertainty dilemma of predicting future data with limited past observations. To settle this question, we explore the use of Cross-Future Behavior (CFB) in TSF, which occurs before the current time but takes effect in the future. We leverage CFB features and propose the CRoss-Future Behavior Awareness based Time Series Forecasting method (CRAFT). The core idea of CRAFT is to utilize the trend of cross-future behavior to mine the trend of time series data to be predicted. Specifically, to settle the sparse and partial flaws of cross-future behavior, CRAFT employs the Koopman Predictor Module to extract the key trend and the Internal Trend Mining Module to supplement the unknown area of the cross-future behavior matrix. Then, we introduce the External Trend Guide Module with a hierarchical structure to acquire more representative trends from higher levels. Finally, we apply the demand-constrained loss to calibrate the distribution deviation of prediction results. We conduct experiments on real-world dataset. Experiments on both offline large-scale dataset and online A/B test demonstrate the effectiveness of CRAFT. Our dataset and code is available at https://github.com/CRAFTinTSF/CRAFT.
UncTrack: Reliable Visual Object Tracking with Uncertainty-Aware Prototype Memory Network
Mar 17, 2025



Transformer-based trackers have achieved promising success and become the dominant tracking paradigm due to their accuracy and efficiency. Despite the substantial progress, most of the existing approaches tackle object tracking as a deterministic coordinate regression problem, while the target localization uncertainty has been greatly overlooked, which hampers trackers' ability to maintain reliable target state prediction in challenging scenarios. To address this issue, we propose UncTrack, a novel uncertainty-aware transformer tracker that predicts the target localization uncertainty and incorporates this uncertainty information for accurate target state inference. Specifically, UncTrack utilizes a transformer encoder to perform feature interaction between template and search images. The output features are passed into an uncertainty-aware localization decoder (ULD) to coarsely predict the corner-based localization and the corresponding localization uncertainty. Then the localization uncertainty is sent into a prototype memory network (PMN) to excavate valuable historical information to identify whether the target state prediction is reliable or not. To enhance the template representation, the samples with high confidence are fed back into the prototype memory bank for memory updating, making the tracker more robust to challenging appearance variations. Extensive experiments demonstrate that our method outperforms other state-of-the-art methods. Our code is available at https://github.com/ManOfStory/UncTrack.
Humor in AI: Massive Scale Crowd-Sourced Preferences and Benchmarks for Cartoon Captioning
Jun 15, 2024



We present a novel multimodal preference dataset for creative tasks, consisting of over 250 million human ratings on more than 2.2 million captions, collected through crowdsourcing rating data for The New Yorker's weekly cartoon caption contest over the past eight years. This unique dataset supports the development and evaluation of multimodal large language models and preference-based fine-tuning algorithms for humorous caption generation. We propose novel benchmarks for judging the quality of model-generated captions, utilizing both GPT4 and human judgments to establish ranking-based evaluation strategies. Our experimental results highlight the limitations of current fine-tuning methods, such as RLHF and DPO, when applied to creative tasks. Furthermore, we demonstrate that even state-of-the-art models like GPT4 and Claude currently underperform top human contestants in generating humorous captions. As we conclude this extensive data collection effort, we release the entire preference dataset to the research community, fostering further advancements in AI humor generation and evaluation.
Voucher Abuse Detection with Prompt-based Fine-tuning on Graph Neural Networks
Aug 30, 2023Voucher abuse detection is an important anomaly detection problem in E-commerce. While many GNN-based solutions have emerged, the supervised paradigm depends on a large quantity of labeled data. A popular alternative is to adopt self-supervised pre-training using label-free data, and further fine-tune on a downstream task with limited labels. Nevertheless, the "pre-train, fine-tune" paradigm is often plagued by the objective gap between pre-training and downstream tasks. Hence, we propose VPGNN, a prompt-based fine-tuning framework on GNNs for voucher abuse detection. We design a novel graph prompting function to reformulate the downstream task into a similar template as the pretext task in pre-training, thereby narrowing the objective gap. Extensive experiments on both proprietary and public datasets demonstrate the strength of VPGNN in both few-shot and semi-supervised scenarios. Moreover, an online deployment of VPGNN in a production environment shows a 23.4% improvement over two existing deployed models.
Two Heads are Better than One: Towards Better Adversarial Robustness by Combining Transduction and Rejection
May 27, 2023



Both transduction and rejection have emerged as important techniques for defending against adversarial perturbations. A recent work by Tram\`er showed that, in the rejection-only case (no transduction), a strong rejection-solution can be turned into a strong (but computationally inefficient) non-rejection solution. This detector-to-classifier reduction has been mostly applied to give evidence that certain claims of strong selective-model solutions are susceptible, leaving the benefits of rejection unclear. On the other hand, a recent work by Goldwasser et al. showed that rejection combined with transduction can give provable guarantees (for certain problems) that cannot be achieved otherwise. Nevertheless, under recent strong adversarial attacks (GMSA, which has been shown to be much more effective than AutoAttack against transduction), Goldwasser et al.'s work was shown to have low performance in a practical deep-learning setting. In this paper, we take a step towards realizing the promise of transduction+rejection in more realistic scenarios. Theoretically, we show that a novel application of Tram\`er's classifier-to-detector technique in the transductive setting can give significantly improved sample-complexity for robust generalization. While our theoretical construction is computationally inefficient, it guides us to identify an efficient transductive algorithm to learn a selective model. Extensive experiments using state of the art attacks (AutoAttack, GMSA) show that our solutions provide significantly better robust accuracy.
Automated Surface Texture Analysis via Discrete Cosine Transform and Discrete Wavelet Transform
Apr 12, 2022

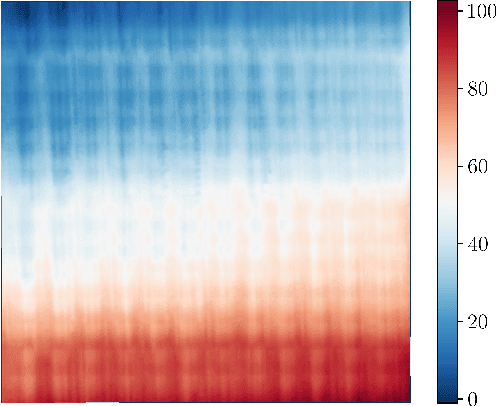

Surface roughness and texture are critical to the functional performance of engineering components. The ability to analyze roughness and texture effectively and efficiently is much needed to ensure surface quality in many surface generation processes, such as machining, surface mechanical treatment, etc. Discrete Wavelet Transform (DWT) and Discrete Cosine Transform (DCT) are two commonly used signal decomposition tools for surface roughness and texture analysis. Both methods require selecting a threshold to decompose a given surface into its three main components: form, waviness, and roughness. However, although DWT and DCT are part of the ISO surface finish standards, there exists no systematic guidance on how to compute these thresholds, and they are often manually selected on case by case basis. This makes utilizing these methods for studying surfaces dependent on the user's judgment and limits their automation potential. Therefore, we present two automatic threshold selection algorithms based on information theory and signal energy. We use machine learning to validate the success of our algorithms both using simulated surfaces as well as digital microscopy images of machined surfaces. Specifically, we generate feature vectors for each surface area or profile and apply supervised classification. Comparing our results with the heuristic threshold selection approach shows good agreement with mean accuracies as high as 95\%. We also compare our results with Gaussian filtering (GF) and show that while GF results for areas can yield slightly higher accuracies, our results outperform GF for surface profiles. We further show that our automatic threshold selection has significant advantages in terms of computational time as evidenced by decreasing the number of mode computations by an order of magnitude compared to the heuristic thresholding for DCT.
Towards Evaluating the Robustness of Neural Networks Learned by Transduction
Oct 27, 2021
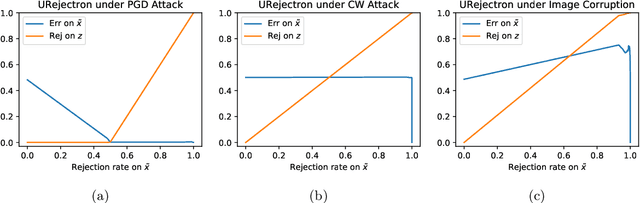

There has been emerging interest in using transductive learning for adversarial robustness (Goldwasser et al., NeurIPS 2020; Wu et al., ICML 2020; Wang et al., ArXiv 2021). Compared to traditional defenses, these defense mechanisms "dynamically learn" the model based on test-time input; and theoretically, attacking these defenses reduces to solving a bilevel optimization problem, which poses difficulty in crafting adaptive attacks. In this paper, we examine these defense mechanisms from a principled threat analysis perspective. We formulate and analyze threat models for transductive-learning based defenses, and point out important subtleties. We propose the principle of attacking model space for solving bilevel attack objectives, and present Greedy Model Space Attack (GMSA), an attack framework that can serve as a new baseline for evaluating transductive-learning based defenses. Through systematic evaluation, we show that GMSA, even with weak instantiations, can break previous transductive-learning based defenses, which were resilient to previous attacks, such as AutoAttack (Croce and Hein, ICML 2020). On the positive side, we report a somewhat surprising empirical result of "transductive adversarial training": Adversarially retraining the model using fresh randomness at the test time gives a significant increase in robustness against attacks we consider.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021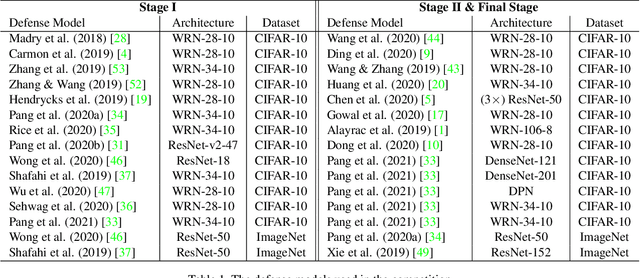
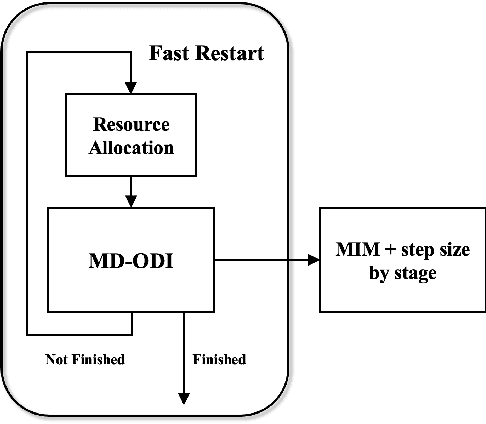
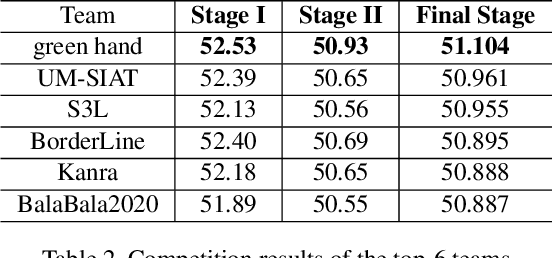
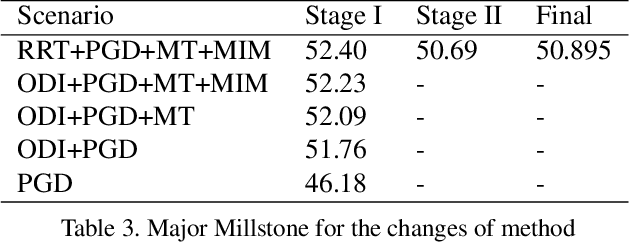
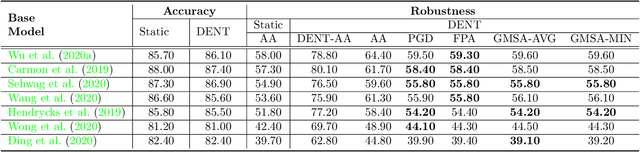
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.
A New Bidirectional Unsupervised Domain Adaptation Segmentation Framework
Aug 18, 2021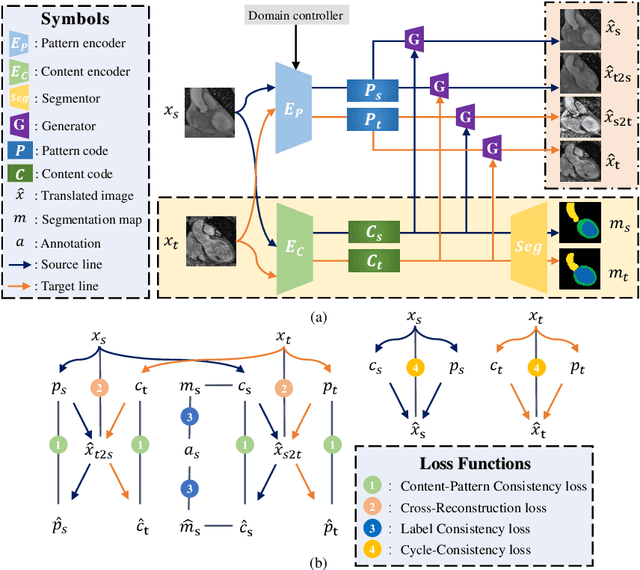
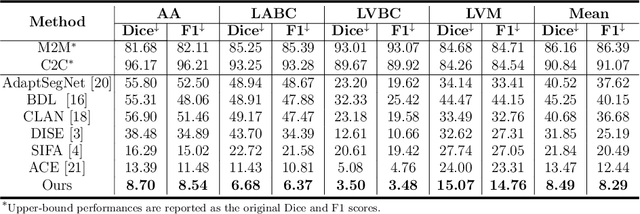
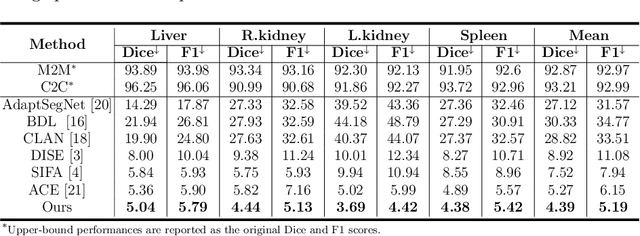
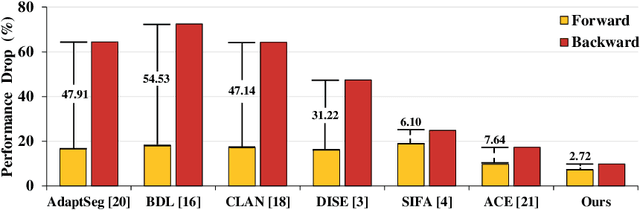
Domain shift happens in cross-domain scenarios commonly because of the wide gaps between different domains: when applying a deep learning model well-trained in one domain to another target domain, the model usually performs poorly. To tackle this problem, unsupervised domain adaptation (UDA) techniques are proposed to bridge the gap between different domains, for the purpose of improving model performance without annotation in the target domain. Particularly, UDA has a great value for multimodal medical image analysis, where annotation difficulty is a practical concern. However, most existing UDA methods can only achieve satisfactory improvements in one adaptation direction (e.g., MRI to CT), but often perform poorly in the other (CT to MRI), limiting their practical usage. In this paper, we propose a bidirectional UDA (BiUDA) framework based on disentangled representation learning for equally competent two-way UDA performances. This framework employs a unified domain-aware pattern encoder which not only can adaptively encode images in different domains through a domain controller, but also improve model efficiency by eliminating redundant parameters. Furthermore, to avoid distortion of contents and patterns of input images during the adaptation process, a content-pattern consistency loss is introduced. Additionally, for better UDA segmentation performance, a label consistency strategy is proposed to provide extra supervision by recomposing target-domain-styled images and corresponding source-domain annotations. Comparison experiments and ablation studies conducted on two public datasets demonstrate the superiority of our BiUDA framework to current state-of-the-art UDA methods and the effectiveness of its novel designs. By successfully addressing two-way adaptations, our BiUDA framework offers a flexible solution of UDA techniques to the real-world scenario.