 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Saliency based Feature Fusion Model for EEG Emotion Estimation
Jan 26, 2022
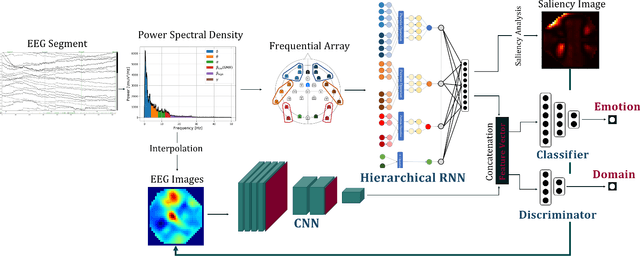

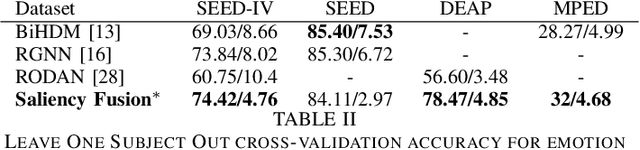
Among the different modalities to assess emotion, electroencephalogram (EEG), representing the electrical brain activity, achieved motivating results over the last decade. Emotion estimation from EEG could help in the diagnosis or rehabilitation of certain diseases. In this paper, we propose a dual model considering two different representations of EEG feature maps: 1) a sequential based representation of EEG band power, 2) an image-based representation of the feature vectors. We also propose an innovative method to combine the information based on a saliency analysis of the image-based model to promote joint learning of both model parts. The model has been evaluated on four publicly available datasets and achieves similar results to the state-of-the-art approaches. It outperforms results for two of the proposed datasets with a lower standard deviation that reflects higher stability. For sake of reproducibility, the codes and models proposed in this paper are available at https://github.com/VDelv/Emotion-EEG.
Weakly-Supervised Feature Learning via Text and Image Matching
Oct 06, 2020

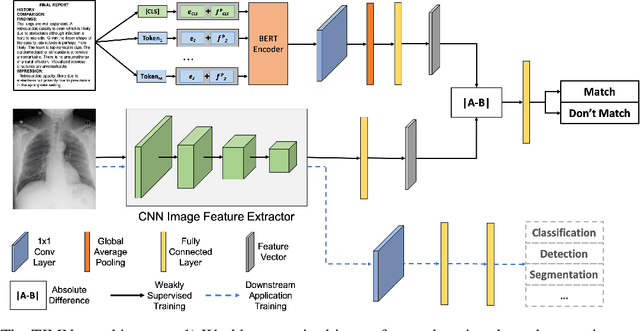
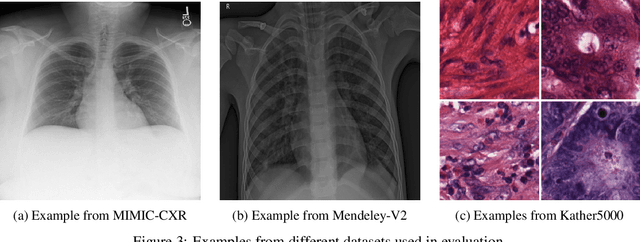
When training deep neural networks for medical image classification, obtaining a sufficient number of manually annotated images is often a significant challenge. We propose to use textual findings, which are routinely written by clinicians during manual image analysis, to help overcome this problem. The key idea is to use a contrastive loss to train image and text feature extractors to recognize if a given image-finding pair is a true match. The learned image feature extractor is then fine-tuned, in a transfer learning setting, for a supervised classification task. This approach makes it possible to train using large datasets because pairs of images and textual findings are widely available in medical records. We evaluate our method on three datasets and find consistent performance improvements. The biggest gains are realized when fewer manually labeled examples are available. In some cases, our method achieves the same performance as the baseline even when using 70\%--98\% fewer labeled examples.
Generative Max-Mahalanobis Classifiers for Image Classification, Generation and More
Jan 01, 2021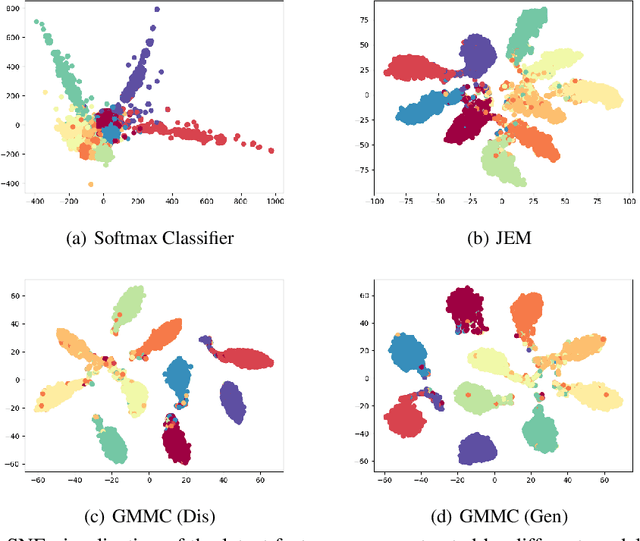
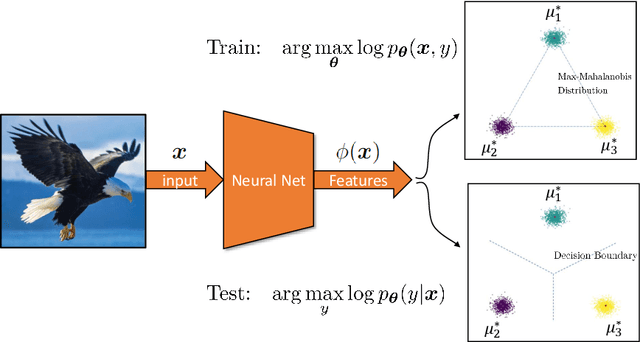

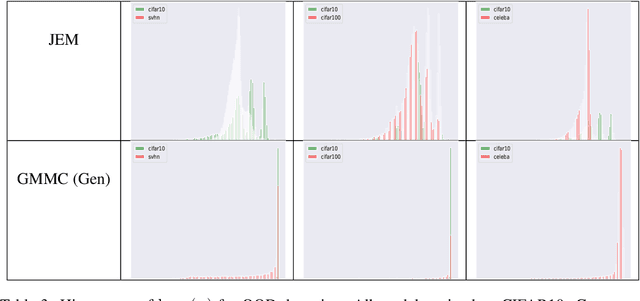
Joint Energy-based Model (JEM) of~\cite{jem} shows that a standard softmax classifier can be reinterpreted as an energy-based model (EBM) for the joint distribution $p(\boldsymbol{x}, y)$; the resulting model can be optimized with an energy-based training to improve calibration, robustness and out-of-distribution detection, while generating samples rivaling the quality of recent GAN-based approaches. However, the softmax classifier that JEM exploits is inherently discriminative and its latent feature space is not well formulated as probabilistic distributions, which may hinder its potential for image generation and incur training instability as observed in~\cite{jem}. We hypothesize that generative classifiers, such as Linear Discriminant Analysis (LDA), might be more suitable hybrid models for image generation since generative classifiers model the data generation process explicitly. This paper therefore investigates an LDA classifier for image classification and generation. In particular, the Max-Mahalanobis Classifier (MMC)~\cite{Pang2020Rethinking}, a special case of LDA, fits our goal very well since MMC formulates the latent feature space explicitly as the Max-Mahalanobis distribution~\cite{pang2018max}. We term our algorithm Generative MMC (GMMC), and show that it can be trained discriminatively, generatively or jointly for image classification and generation. Extensive experiments on multiple datasets (CIFAR10, CIFAR100 and SVHN) show that GMMC achieves state-of-the-art discriminative and generative performances, while outperforming JEM in calibration, adversarial robustness and out-of-distribution detection by a significant margin.
MEFNet: Multi-scale Event Fusion Network for Motion Deblurring
Nov 30, 2021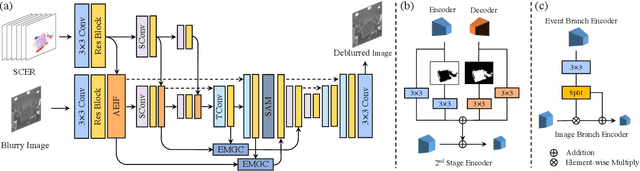
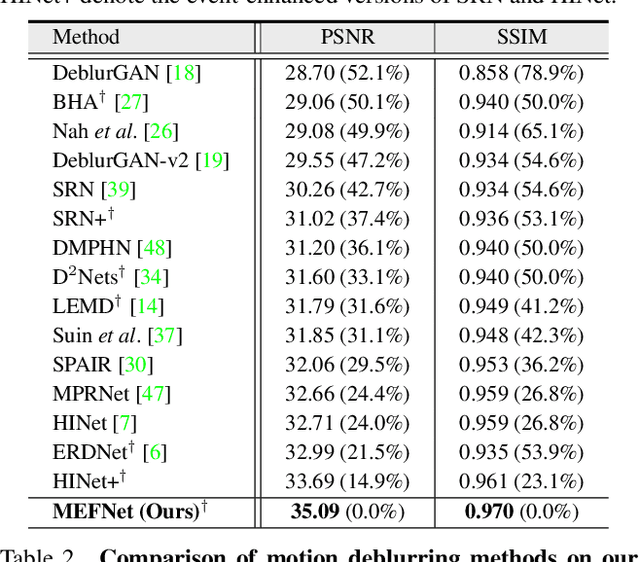
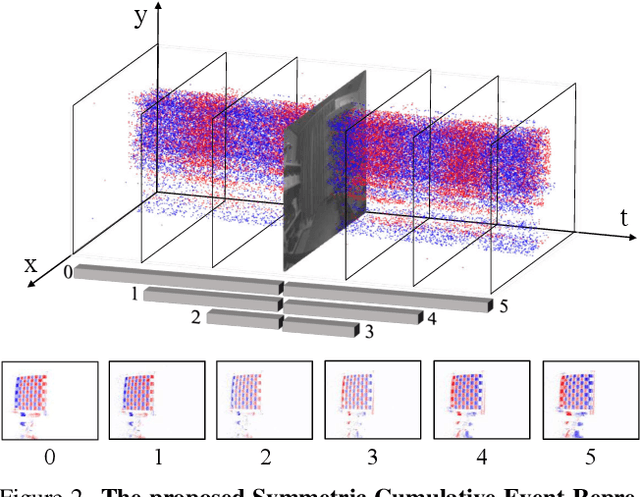
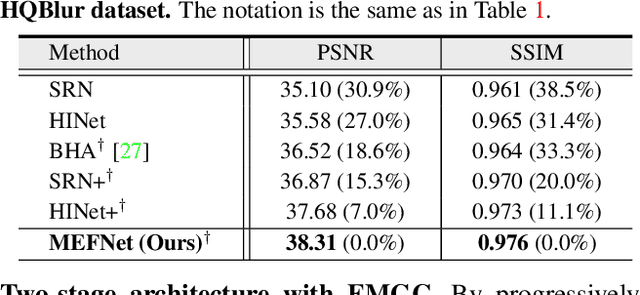
Traditional frame-based cameras inevitably suffer from motion blur due to long exposure times. As a kind of bio-inspired camera, the event camera records the intensity changes in an asynchronous way with high temporal resolution, providing valid image degradation information within the exposure time. In this paper, we rethink the event-based image deblurring problem and unfold it into an end-to-end two-stage image restoration network. To effectively utilize event information, we design (i) a novel symmetric cumulative event representation specifically for image deblurring, and (ii) an affine event-image fusion module applied at multiple levels of our network. We also propose an event mask gated connection between the two stages of the network so as to avoid information loss. At the dataset level, to foster event-based motion deblurring and to facilitate evaluation on challenging real-world images, we introduce the High-Quality Blur (HQBlur) dataset, captured with an event camera in an illumination-controlled optical laboratory. Our Multi-Scale Event Fusion Network (MEFNet) sets the new state of the art for motion deblurring, surpassing both the prior best-performing image-based method and all event-based methods with public implementations on the GoPro (by up to 2.38dB) and HQBlur datasets, even in extreme blurry conditions. Source code and dataset will be made publicly available.
Co-Teaching for Unsupervised Domain Adaptation and Expansion
Apr 04, 2022
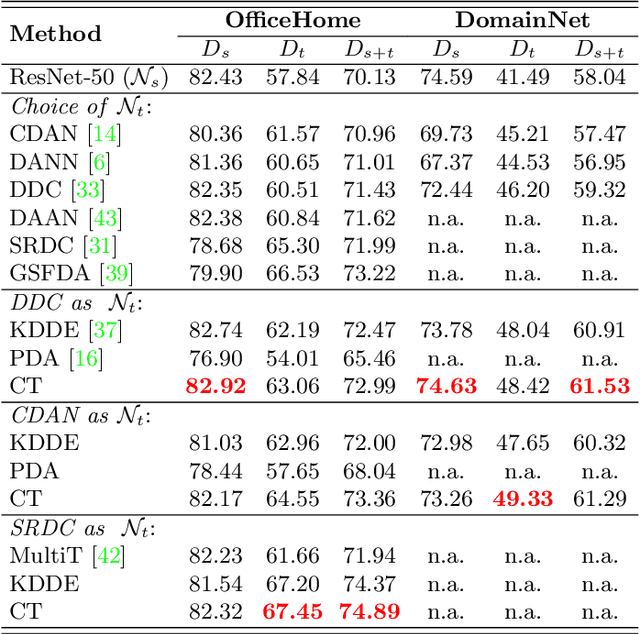
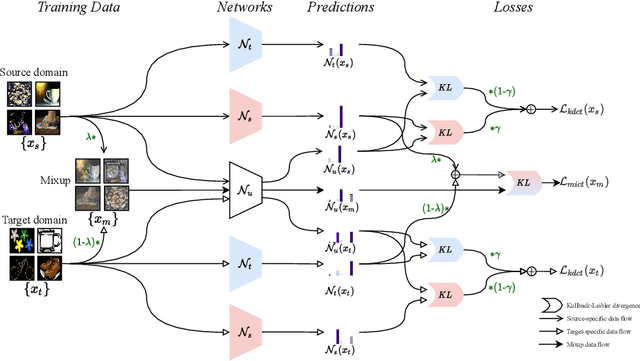
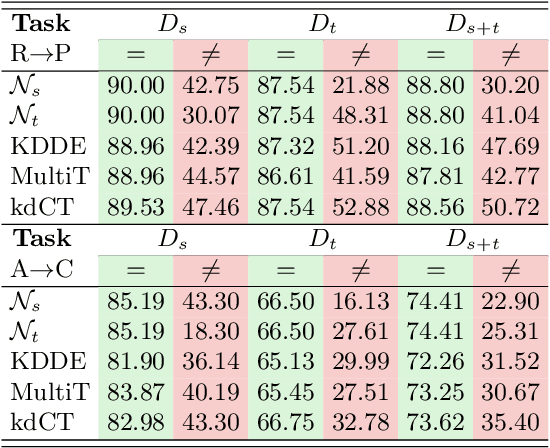
Unsupervised Domain Adaptation (UDA) is known to trade a model's performance on a source domain for improving its performance on a target domain. To resolve the issue, Unsupervised Domain Expansion (UDE) has been proposed recently to adapt the model for the target domain as UDA does, and in the meantime maintain its performance on the source domain. For both UDA and UDE, a model tailored to a given domain, let it be the source or the target domain, is assumed to well handle samples from the given domain. We question the assumption by reporting the existence of cross-domain visual ambiguity: Due to the lack of a crystally clear boundary between the two domains, samples from one domain can be visually close to the other domain. We exploit this finding and accordingly propose in this paper Co-Teaching (CT) that consists of knowledge distillation based CT (kdCT) and mixup based CT (miCT). Specifically, kdCT transfers knowledge from a leader-teacher network and an assistant-teacher network to a student network, so the cross-domain visual ambiguity will be better handled by the student. Meanwhile, miCT further enhances the generalization ability of the student. Comprehensive experiments on two image-classification benchmarks and two driving-scene-segmentation benchmarks justify the viability of the proposed method.
Multi-level Second-order Few-shot Learning
Jan 15, 2022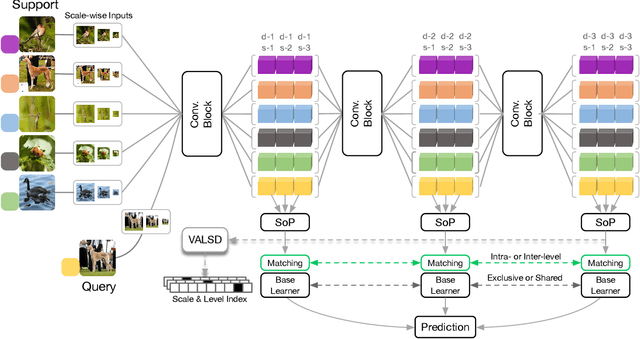
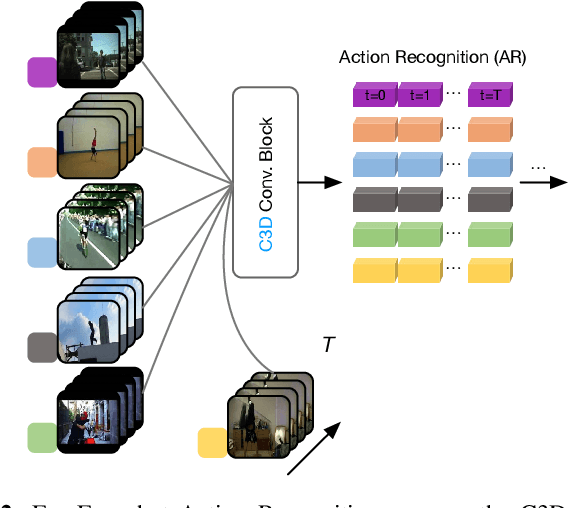
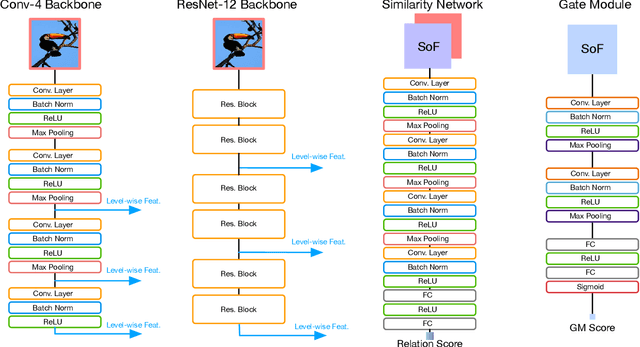
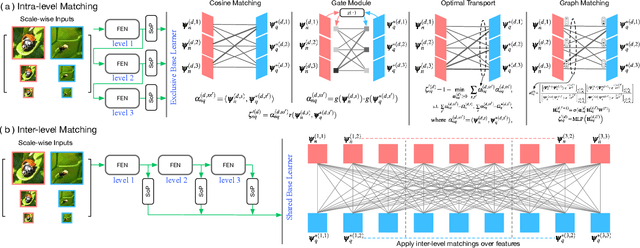
We propose a Multi-level Second-order (MlSo) few-shot learning network for supervised or unsupervised few-shot image classification and few-shot action recognition. We leverage so-called power-normalized second-order base learner streams combined with features that express multiple levels of visual abstraction, and we use self-supervised discriminating mechanisms. As Second-order Pooling (SoP) is popular in image recognition, we employ its basic element-wise variant in our pipeline. The goal of multi-level feature design is to extract feature representations at different layer-wise levels of CNN, realizing several levels of visual abstraction to achieve robust few-shot learning. As SoP can handle convolutional feature maps of varying spatial sizes, we also introduce image inputs at multiple spatial scales into MlSo. To exploit the discriminative information from multi-level and multi-scale features, we develop a Feature Matching (FM) module that reweights their respective branches. We also introduce a self-supervised step, which is a discriminator of the spatial level and the scale of abstraction. Our pipeline is trained in an end-to-end manner. With a simple architecture, we demonstrate respectable results on standard datasets such as Omniglot, mini-ImageNet, tiered-ImageNet, Open MIC, fine-grained datasets such as CUB Birds, Stanford Dogs and Cars, and action recognition datasets such as HMDB51, UCF101, and mini-MIT.
SeqTR: A Simple yet Universal Network for Visual Grounding
Mar 30, 2022
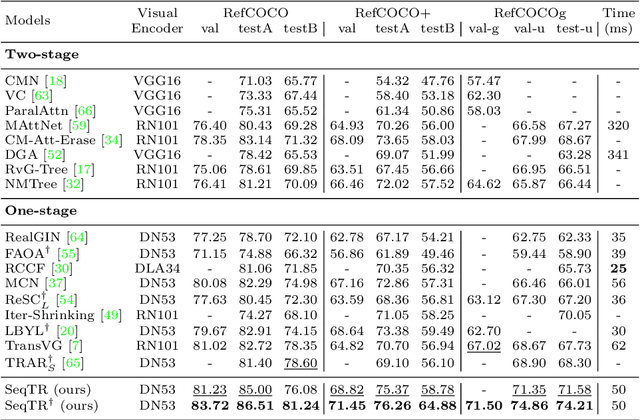
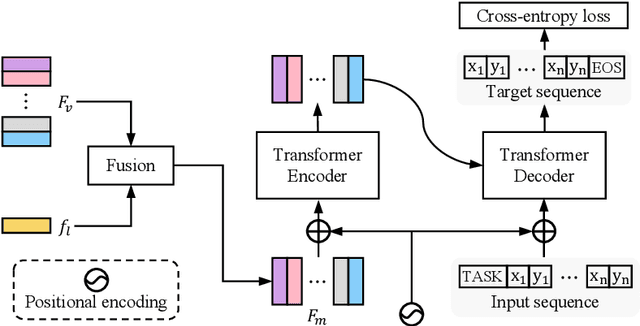
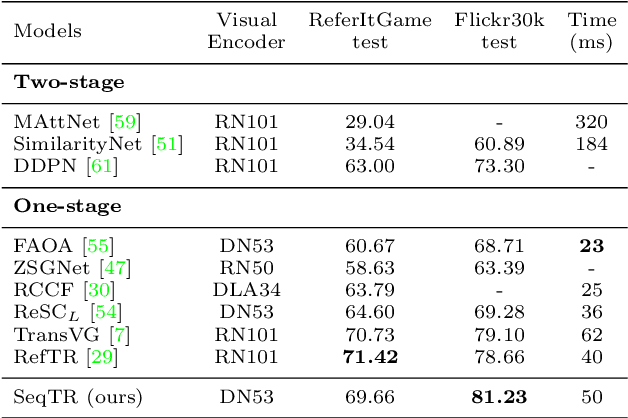
In this paper, we propose a simple yet universal network termed SeqTR for visual grounding tasks, e.g., phrase localization, referring expression comprehension (REC) and segmentation (RES). The canonical paradigms for visual grounding often require substantial expertise in designing network architectures and loss functions, making them hard to generalize across tasks. To simplify and unify the modeling, we cast visual grounding as a point prediction problem conditioned on image and text inputs, where either the bounding box or binary mask is represented as a sequence of discrete coordinate tokens. Under this paradigm, visual grounding tasks are unified in our SeqTR network without task-specific branches or heads, e.g., the convolutional mask decoder for RES, which greatly reduces the complexity of multi-task modeling. In addition, SeqTR also shares the same optimization objective for all tasks with a simple cross-entropy loss, further reducing the complexity of deploying hand-crafted loss functions. Experiments on five benchmark datasets demonstrate that the proposed SeqTR outperforms (or is on par with) the existing state-of-the-arts, proving that a simple yet universal approach for visual grounding is indeed feasible.
DualConv: Dual Convolutional Kernels for Lightweight Deep Neural Networks
Feb 15, 2022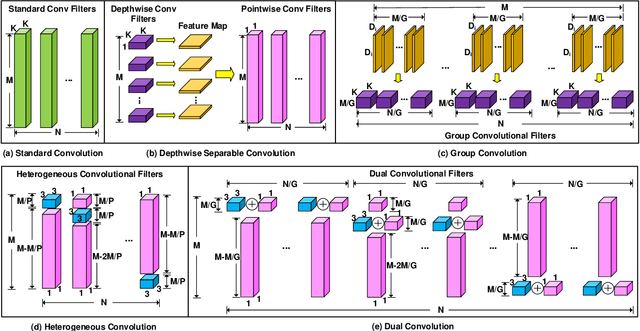
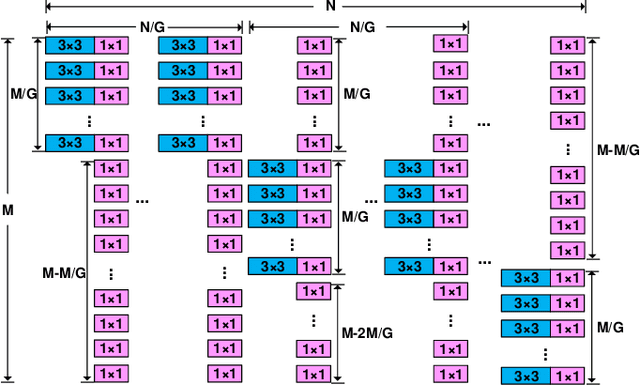
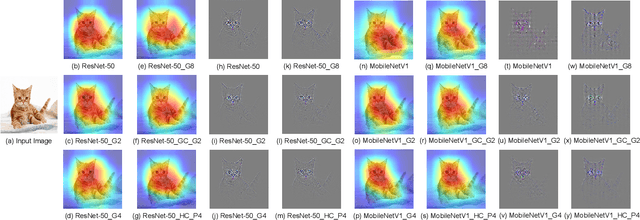
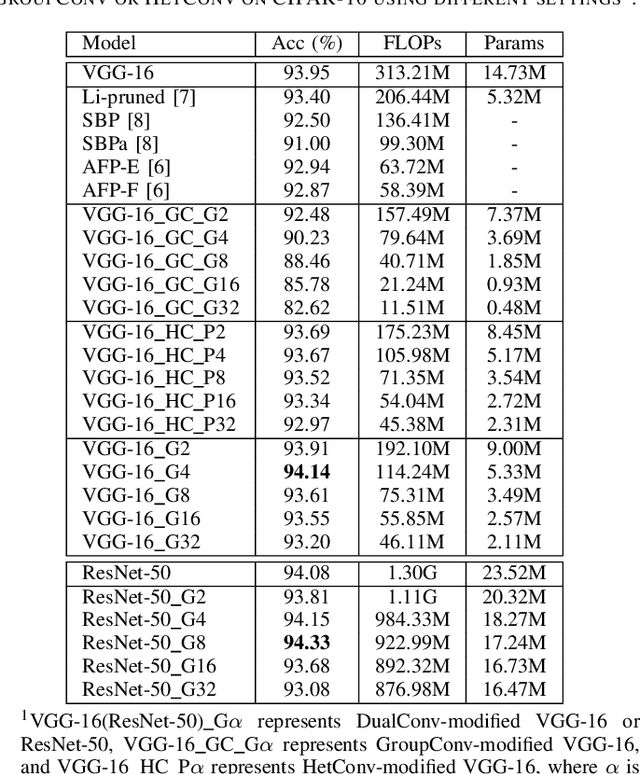
CNN architectures are generally heavy on memory and computational requirements which makes them infeasible for embedded systems with limited hardware resources. We propose dual convolutional kernels (DualConv) for constructing lightweight deep neural networks. DualConv combines 3$\times$3 and 1$\times$1 convolutional kernels to process the same input feature map channels simultaneously and exploits the group convolution technique to efficiently arrange convolutional filters. DualConv can be employed in any CNN model such as VGG-16 and ResNet-50 for image classification, YOLO and R-CNN for object detection, or FCN for semantic segmentation. In this paper, we extensively test DualConv for classification since these network architectures form the backbones for many other tasks. We also test DualConv for image detection on YOLO-V3. Experimental results show that, combined with our structural innovations, DualConv significantly reduces the computational cost and number of parameters of deep neural networks while surprisingly achieving slightly higher accuracy than the original models in some cases. We use DualConv to further reduce the number of parameters of the lightweight MobileNetV2 by 54% with only 0.68% drop in accuracy on CIFAR-100 dataset. When the number of parameters is not an issue, DualConv increases the accuracy of MobileNetV1 by 4.11% on the same dataset. Furthermore, DualConv significantly improves the YOLO-V3 object detection speed and improves its accuracy by 4.4% on PASCAL VOC dataset.
Unifying Specialist Image Embedding into Universal Image Embedding
Mar 08, 2020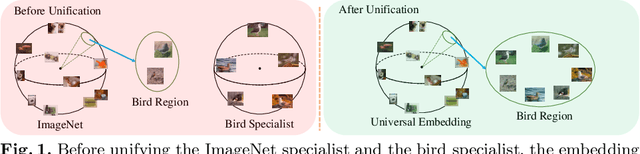
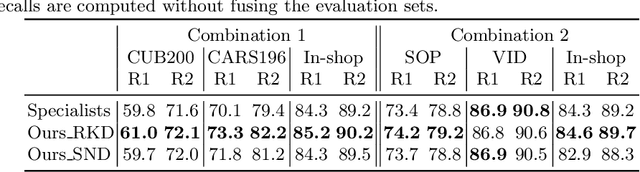
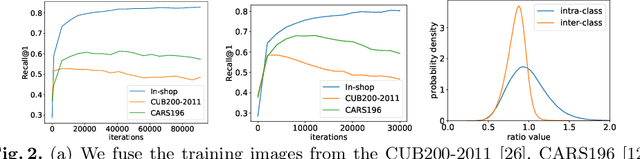
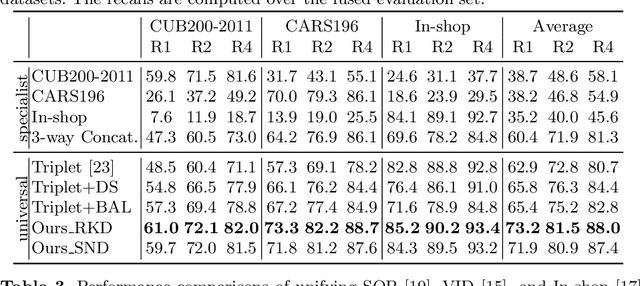
Deep image embedding provides a way to measure the semantic similarity of two images. It plays a central role in many applications such as image search, face verification, and zero-shot learning. It is desirable to have a universal deep embedding model applicable to various domains of images. However, existing methods mainly rely on training specialist embedding models each of which is applicable to images from a single domain. In this paper, we study an important but unexplored task: how to train a single universal image embedding model to match the performance of several specialists on each specialist's domain. Simply fusing the training data from multiple domains cannot solve this problem because some domains become overfitted sooner when trained together using existing methods. Therefore, we propose to distill the knowledge in multiple specialists into a universal embedding to solve this problem. In contrast to existing embedding distillation methods that distill the absolute distances between images, we transform the absolute distances between images into a probabilistic distribution and minimize the KL-divergence between the distributions of the specialists and the universal embedding. Using several public datasets, we validate that our proposed method accomplishes the goal of universal image embedding.
Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection
Mar 30, 2022

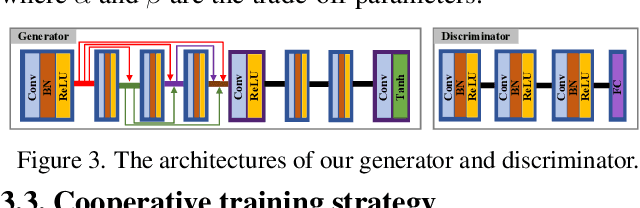

This study addresses the issue of fusing infrared and visible images that appear differently for object detection. Aiming at generating an image of high visual quality, previous approaches discover commons underlying the two modalities and fuse upon the common space either by iterative optimization or deep networks. These approaches neglect that modality differences implying the complementary information are extremely important for both fusion and subsequent detection task. This paper proposes a bilevel optimization formulation for the joint problem of fusion and detection, and then unrolls to a target-aware Dual Adversarial Learning (TarDAL) network for fusion and a commonly used detection network. The fusion network with one generator and dual discriminators seeks commons while learning from differences, which preserves structural information of targets from the infrared and textural details from the visible. Furthermore, we build a synchronized imaging system with calibrated infrared and optical sensors, and collect currently the most comprehensive benchmark covering a wide range of scenarios. Extensive experiments on several public datasets and our benchmark demonstrate that our method outputs not only visually appealing fusion but also higher detection mAP than the state-of-the-art approaches.