 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: PRior-guided Imagination Sampling in world Models
Jun 06, 2026A learned world model provides a powerful physical intuition for evaluating future states. But its effectiveness in continuous control also depends critically on how candidate actions are generated for model-based planning. Rather than solely asking how accurately a model can simulate the future, we ask: which candidate actions are worth evaluating in the first place? Existing planners typically search arbitrarily or use expert demonstrations only to initialize a sampling mean, discarding the expert's state-conditioned confidence. Properly guiding this search requires a robust action prior, yet current approaches often rely on independent visual encoders or large-scale VLMs to obtain one. We argue that this architectural bloat is unnecessary: the exact same data - and the learned representations of the world model itself - inherently encode the agent's action intuition. We introduce PRISM, a task-agnostic framework that extracts both from a single dataset while maintaining strict architectural simplicity. Building on a standard JEPA-style latent world model, PRISM attaches a lightweight MLP directly to its frozen encoder to predict a state-conditioned Gaussian prior. At plan time, PRISM fuses this prior into the planner's sampling distribution via a precision-weighted Product-of-Gaussians update. This parameter-free, closed-form integration steers the sampling process, making the prior confident where it is and ceding control where it is not. PRISM improves success rates by 35 percentage points over vanilla world-model-based MPC on Cube and 32 percentage points on PushT, without introducing significant inference overhead.
Schedule-and-Calibrate: Utility-Guided Multi-Task Reinforcement Learning for Code LLMs
May 07, 2026Reinforcement learning (RL) with verifiable rewards has proven effective at post-training LLMs for coding, yet deploying separate task-specific specialists incurs costs that scale with the number of tasks, motivating a unified multi-task RL (MTRL) approach. However, existing MTRL methods treat all coding tasks uniformly, relying on fixed data curricula under a shared optimization strategy, ultimately limiting the effectiveness of multi-task training. To address these limitations, we propose ASTOR, a multi-tASk code reinforcement learning framework via uTility-driven coORdination. Centered on task utility, a signal capturing each task learning potential and cross-task synergy, ASTOR comprises two coupled modules: 1) Hierarchical Utility-Routed Data Scheduling module hierarchically allocates training budget and prioritizes informative prompts, steering training toward the most valuable data and 2) Adaptive Utility-Calibrated Policy Optimization module dynamically scales per-task KL regularization, matching update constraints to each tasks current training state. Experiments on two widely-used LLMs across four representative coding tasks demonstrate that ASTOR consistently improves a single model across all tasks, outperforming the best task-specific specialist by 9.0%-9.5% and surpassing the strongest MTRL baseline by 7.5%-12.8%.
MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
Mar 17, 2026Video diffusion models are moving beyond short, plausible clips toward world simulators that must remain consistent under camera motion, revisits, and intervention. Yet spatial memory remains a key bottleneck: explicit 3D structures can improve reprojection-based consistency but struggle to depict moving objects, while implicit memory often produces inaccurate camera motion even with correct poses. We propose Mosaic Memory (MosaicMem), a hybrid spatial memory that lifts patches into 3D for reliable localization and targeted retrieval, while exploiting the model's native conditioning to preserve prompt-following generation. MosaicMem composes spatially aligned patches in the queried view via a patch-and-compose interface, preserving what should persist while allowing the model to inpaint what should evolve. With PRoPE camera conditioning and two new memory alignment methods, experiments show improved pose adherence compared to implicit memory and stronger dynamic modeling than explicit baselines. MosaicMem further enables minute-level navigation, memory-based scene editing, and autoregressive rollout.
CausalGDP: Causality-Guided Diffusion Policies for Reinforcement Learning
Feb 09, 2026Reinforcement learning (RL) has achieved remarkable success in a wide range of sequential decision-making problems. Recent diffusion-based policies further improve RL by modeling complex, high-dimensional action distributions. However, existing diffusion policies primarily rely on statistical associations and fail to explicitly account for causal relationships among states, actions, and rewards, limiting their ability to identify which action components truly cause high returns. In this paper, we propose Causality-guided Diffusion Policy (CausalGDP), a unified framework that integrates causal reasoning into diffusion-based RL. CausalGDP first learns a base diffusion policy and an initial causal dynamical model from offline data, capturing causal dependencies among states, actions, and rewards. During real-time interaction, the causal information is continuously updated and incorporated as a guidance signal to steer the diffusion process toward actions that causally influence future states and rewards. By explicitly considering causality beyond association, CausalGDP focuses policy optimization on action components that genuinely drive performance improvements. Experimental results demonstrate that CausalGDP consistently achieves competitive or superior performance over state-of-the-art diffusion-based and offline RL methods, especially in complex, high-dimensional control tasks.
Cross-platform Product Matching Based on Entity Alignment of Knowledge Graph with RAEA model
Dec 08, 2025Product matching aims to identify identical or similar products sold on different platforms. By building knowledge graphs (KGs), the product matching problem can be converted to the Entity Alignment (EA) task, which aims to discover the equivalent entities from diverse KGs. The existing EA methods inadequately utilize both attribute triples and relation triples simultaneously, especially the interactions between them. This paper introduces a two-stage pipeline consisting of rough filter and fine filter to match products from eBay and Amazon. For fine filtering, a new framework for Entity Alignment, Relation-aware and Attribute-aware Graph Attention Networks for Entity Alignment (RAEA), is employed. RAEA focuses on the interactions between attribute triples and relation triples, where the entity representation aggregates the alignment signals from attributes and relations with Attribute-aware Entity Encoder and Relation-aware Graph Attention Networks. The experimental results indicate that the RAEA model achieves significant improvements over 12 baselines on EA task in the cross-lingual dataset DBP15K (6.59% on average Hits@1) and delivers competitive results in the monolingual dataset DWY100K. The source code for experiments on DBP15K and DWY100K is available at github (https://github.com/Mockingjay-liu/RAEA-model-for-Entity-Alignment).
* 10 pages, 5 figures, published on World Wide Web
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Jul 10, 2025Videos inherently represent 2D projections of a dynamic 3D world. However, our analysis suggests that video diffusion models trained solely on raw video data often fail to capture meaningful geometric-aware structure in their learned representations. To bridge this gap between video diffusion models and the underlying 3D nature of the physical world, we propose Geometry Forcing, a simple yet effective method that encourages video diffusion models to internalize latent 3D representations. Our key insight is to guide the model's intermediate representations toward geometry-aware structure by aligning them with features from a pretrained geometric foundation model. To this end, we introduce two complementary alignment objectives: Angular Alignment, which enforces directional consistency via cosine similarity, and Scale Alignment, which preserves scale-related information by regressing unnormalized geometric features from normalized diffusion representation. We evaluate Geometry Forcing on both camera view-conditioned and action-conditioned video generation tasks. Experimental results demonstrate that our method substantially improves visual quality and 3D consistency over the baseline methods. Project page: https://GeometryForcing.github.io.
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
May 28, 2025Subject-to-Video (S2V) generation aims to create videos that faithfully incorporate reference content, providing enhanced flexibility in the production of videos. To establish the infrastructure for S2V generation, we propose OpenS2V-Nexus, consisting of (i) OpenS2V-Eval, a fine-grained benchmark, and (ii) OpenS2V-5M, a million-scale dataset. In contrast to existing S2V benchmarks inherited from VBench that focus on global and coarse-grained assessment of generated videos, OpenS2V-Eval focuses on the model's ability to generate subject-consistent videos with natural subject appearance and identity fidelity. For these purposes, OpenS2V-Eval introduces 180 prompts from seven major categories of S2V, which incorporate both real and synthetic test data. Furthermore, to accurately align human preferences with S2V benchmarks, we propose three automatic metrics, NexusScore, NaturalScore and GmeScore, to separately quantify subject consistency, naturalness, and text relevance in generated videos. Building on this, we conduct a comprehensive evaluation of 16 representative S2V models, highlighting their strengths and weaknesses across different content. Moreover, we create the first open-source large-scale S2V generation dataset OpenS2V-5M, which consists of five million high-quality 720P subject-text-video triples. Specifically, we ensure subject-information diversity in our dataset by (1) segmenting subjects and building pairing information via cross-video associations and (2) prompting GPT-Image-1 on raw frames to synthesize multi-view representations. Through OpenS2V-Nexus, we deliver a robust infrastructure to accelerate future S2V generation research.
ImgEdit: A Unified Image Editing Dataset and Benchmark
May 26, 2025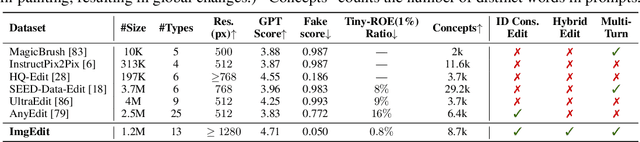
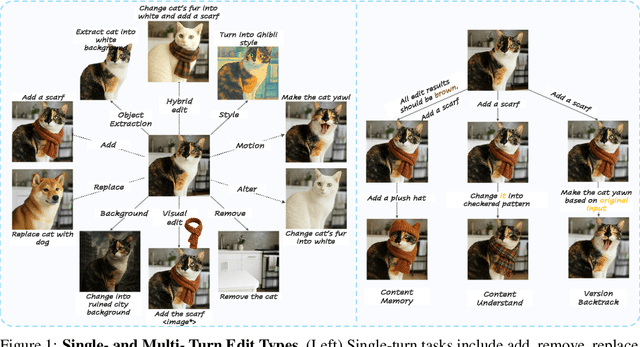
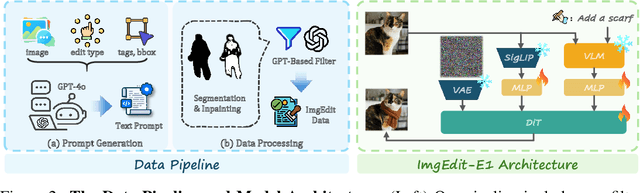

Recent advancements in generative models have enabled high-fidelity text-to-image generation. However, open-source image-editing models still lag behind their proprietary counterparts, primarily due to limited high-quality data and insufficient benchmarks. To overcome these limitations, we introduce ImgEdit, a large-scale, high-quality image-editing dataset comprising 1.2 million carefully curated edit pairs, which contain both novel and complex single-turn edits, as well as challenging multi-turn tasks. To ensure the data quality, we employ a multi-stage pipeline that integrates a cutting-edge vision-language model, a detection model, a segmentation model, alongside task-specific in-painting procedures and strict post-processing. ImgEdit surpasses existing datasets in both task novelty and data quality. Using ImgEdit, we train ImgEdit-E1, an editing model using Vision Language Model to process the reference image and editing prompt, which outperforms existing open-source models on multiple tasks, highlighting the value of ImgEdit and model design. For comprehensive evaluation, we introduce ImgEdit-Bench, a benchmark designed to evaluate image editing performance in terms of instruction adherence, editing quality, and detail preservation. It includes a basic testsuite, a challenging single-turn suite, and a dedicated multi-turn suite. We evaluate both open-source and proprietary models, as well as ImgEdit-E1, providing deep analysis and actionable insights into the current behavior of image-editing models. The source data are publicly available on https://github.com/PKU-YuanGroup/ImgEdit.
Tactile-based Reinforcement Learning for Adaptive Grasping under Observation Uncertainties
May 22, 2025



Robotic manipulation in industrial scenarios such as construction commonly faces uncertain observations in which the state of the manipulating object may not be accurately captured due to occlusions and partial observables. For example, object status estimation during pipe assembly, rebar installation, and electrical installation can be impacted by observation errors. Traditional vision-based grasping methods often struggle to ensure robust stability and adaptability. To address this challenge, this paper proposes a tactile simulator that enables a tactile-based adaptive grasping method to enhance grasping robustness. This approach leverages tactile feedback combined with the Proximal Policy Optimization (PPO) reinforcement learning algorithm to dynamically adjust the grasping posture, allowing adaptation to varying grasping conditions under inaccurate object state estimations. Simulation results demonstrate that the proposed method effectively adapts grasping postures, thereby improving the success rate and stability of grasping tasks.
HeteroSpec: Leveraging Contextual Heterogeneity for Efficient Speculative Decoding
May 19, 2025Autoregressive decoding, the standard approach for Large Language Model (LLM) inference, remains a significant bottleneck due to its sequential nature. While speculative decoding algorithms mitigate this inefficiency through parallel verification, they fail to exploit the inherent heterogeneity in linguistic complexity, a key factor leading to suboptimal resource allocation. We address this by proposing HeteroSpec, a heterogeneity-adaptive speculative decoding framework that dynamically optimizes computational resource allocation based on linguistic context complexity. HeteroSpec introduces two key mechanisms: (1) A novel cumulative meta-path Top-$K$ entropy metric for efficiently identifying predictable contexts. (2) A dynamic resource allocation strategy based on data-driven entropy partitioning, enabling adaptive speculative expansion and pruning tailored to local context difficulty. Evaluated on five public benchmarks and four models, HeteroSpec achieves an average speedup of 4.26$\times$. It consistently outperforms state-of-the-art EAGLE-3 across speedup rates, average acceptance length, and verification cost. Notably, HeteroSpec requires no draft model retraining, incurs minimal overhead, and is orthogonal to other acceleration techniques. It demonstrates enhanced acceleration with stronger draft models, establishing a new paradigm for context-aware LLM inference acceleration.