 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-Flow: Self-supervised Human Scene Flow via Physics-inspired Joint Multi-modal Learning
May 21, 2026Parametric human models capture global pose but cannot represent the non-rigid surface dynamics of clothing and soft tissue. Generic scene flow estimates dense motion but breaks down on articulated bodies, where pixel-level supervision is also intractable to acquire. We introduce H-Flow, a dense human scene flow that captures both skeletal kinematics and surface deformation. A unified multi-head transformer estimates flow from monocular video, jointly predicting pose and depth as companion outputs. The challenge lies in the lack of supervision. In place of unattainable labels, we anchor the network in the physics of human motion, encoding geometric, structural, and biomechanical priors as cross-modal training objectives. We further introduce DynAct4D, a high-fidelity synthetic benchmark providing dense flow annotations across diverse subjects, garments, and motions. On standard benchmarks, H-Flow outperforms scene-flow and parametric baselines, and generalizes zero-shot to in-the-wild video. Code, models, and the DynAct4D benchmark will be released upon publication
BiggerGait: Unlocking Gait Recognition with Layer-wise Representations from Large Vision Models
May 23, 2025



Large vision models (LVM) based gait recognition has achieved impressive performance. However, existing LVM-based approaches may overemphasize gait priors while neglecting the intrinsic value of LVM itself, particularly the rich, distinct representations across its multi-layers. To adequately unlock LVM's potential, this work investigates the impact of layer-wise representations on downstream recognition tasks. Our analysis reveals that LVM's intermediate layers offer complementary properties across tasks, integrating them yields an impressive improvement even without rich well-designed gait priors. Building on this insight, we propose a simple and universal baseline for LVM-based gait recognition, termed BiggerGait. Comprehensive evaluations on CCPG, CAISA-B*, SUSTech1K, and CCGR\_MINI validate the superiority of BiggerGait across both within- and cross-domain tasks, establishing it as a simple yet practical baseline for gait representation learning. All the models and code will be publicly available.
H-MoRe: Learning Human-centric Motion Representation for Action Analysis
Apr 14, 2025



In this paper, we propose H-MoRe, a novel pipeline for learning precise human-centric motion representation. Our approach dynamically preserves relevant human motion while filtering out background movement. Notably, unlike previous methods relying on fully supervised learning from synthetic data, H-MoRe learns directly from real-world scenarios in a self-supervised manner, incorporating both human pose and body shape information. Inspired by kinematics, H-MoRe represents absolute and relative movements of each body point in a matrix format that captures nuanced motion details, termed world-local flows. H-MoRe offers refined insights into human motion, which can be integrated seamlessly into various action-related applications. Experimental results demonstrate that H-MoRe brings substantial improvements across various downstream tasks, including gait recognition(CL@R1: +16.01%), action recognition(Acc@1: +8.92%), and video generation(FVD: -67.07%). Additionally, H-MoRe exhibits high inference efficiency (34 fps), making it suitable for most real-time scenarios. Models and code will be released upon publication.
Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection
Mar 30, 2022

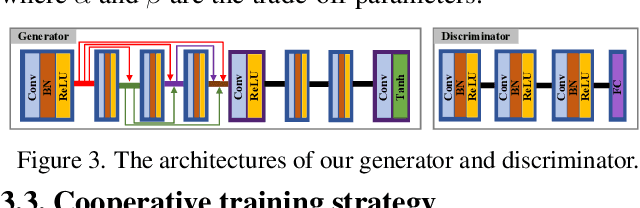

This study addresses the issue of fusing infrared and visible images that appear differently for object detection. Aiming at generating an image of high visual quality, previous approaches discover commons underlying the two modalities and fuse upon the common space either by iterative optimization or deep networks. These approaches neglect that modality differences implying the complementary information are extremely important for both fusion and subsequent detection task. This paper proposes a bilevel optimization formulation for the joint problem of fusion and detection, and then unrolls to a target-aware Dual Adversarial Learning (TarDAL) network for fusion and a commonly used detection network. The fusion network with one generator and dual discriminators seeks commons while learning from differences, which preserves structural information of targets from the infrared and textural details from the visible. Furthermore, we build a synchronized imaging system with calibrated infrared and optical sensors, and collect currently the most comprehensive benchmark covering a wide range of scenarios. Extensive experiments on several public datasets and our benchmark demonstrate that our method outputs not only visually appealing fusion but also higher detection mAP than the state-of-the-art approaches.