 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Unifying Specialist Image Embedding into Universal Image Embedding
Mar 08, 2020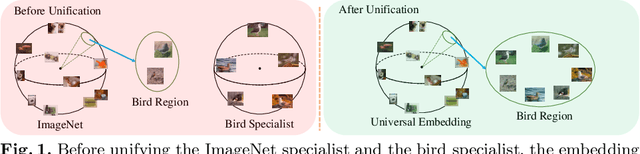
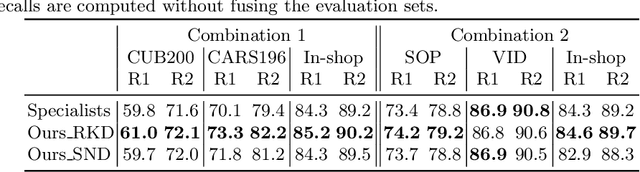
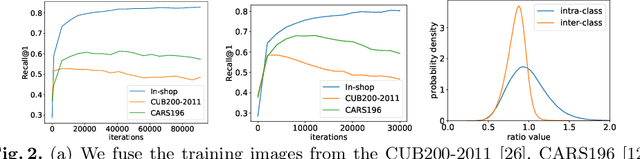
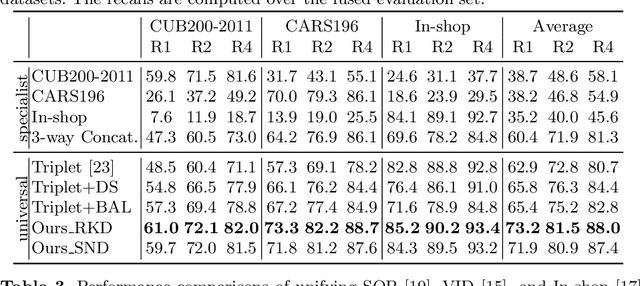
Deep image embedding provides a way to measure the semantic similarity of two images. It plays a central role in many applications such as image search, face verification, and zero-shot learning. It is desirable to have a universal deep embedding model applicable to various domains of images. However, existing methods mainly rely on training specialist embedding models each of which is applicable to images from a single domain. In this paper, we study an important but unexplored task: how to train a single universal image embedding model to match the performance of several specialists on each specialist's domain. Simply fusing the training data from multiple domains cannot solve this problem because some domains become overfitted sooner when trained together using existing methods. Therefore, we propose to distill the knowledge in multiple specialists into a universal embedding to solve this problem. In contrast to existing embedding distillation methods that distill the absolute distances between images, we transform the absolute distances between images into a probabilistic distribution and minimize the KL-divergence between the distributions of the specialists and the universal embedding. Using several public datasets, we validate that our proposed method accomplishes the goal of universal image embedding.