 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqTR: A Simple yet Universal Network for Visual Grounding
Paper and Code

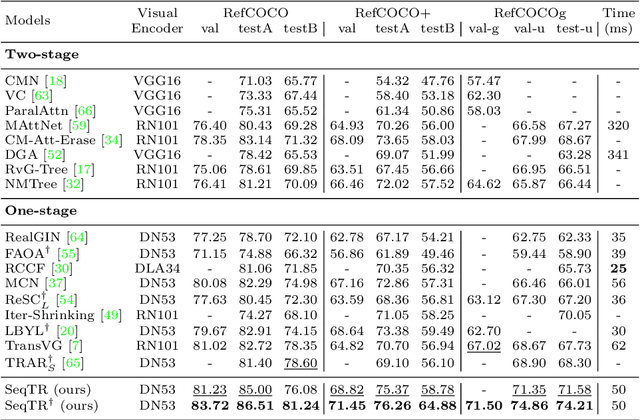
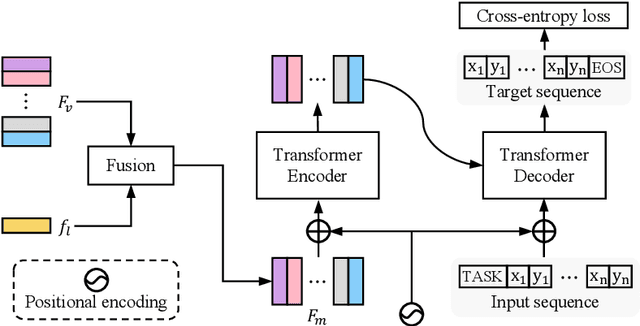
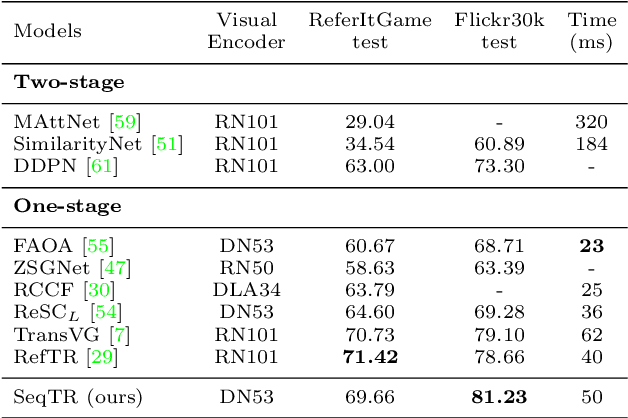
In this paper, we propose a simple yet universal network termed SeqTR for visual grounding tasks, e.g., phrase localization, referring expression comprehension (REC) and segmentation (RES). The canonical paradigms for visual grounding often require substantial expertise in designing network architectures and loss functions, making them hard to generalize across tasks. To simplify and unify the modeling, we cast visual grounding as a point prediction problem conditioned on image and text inputs, where either the bounding box or binary mask is represented as a sequence of discrete coordinate tokens. Under this paradigm, visual grounding tasks are unified in our SeqTR network without task-specific branches or heads, e.g., the convolutional mask decoder for RES, which greatly reduces the complexity of multi-task modeling. In addition, SeqTR also shares the same optimization objective for all tasks with a simple cross-entropy loss, further reducing the complexity of deploying hand-crafted loss functions. Experiments on five benchmark datasets demonstrate that the proposed SeqTR outperforms (or is on par with) the existing state-of-the-arts, proving that a simple yet universal approach for visual grounding is indeed feasible.