 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundus-R1: Training a Fundus-Reading MLLM with Knowledge-Aware Reasoning on Public Data
Apr 09, 2026Fundus imaging such as CFP, OCT and UWF is crucial for the early detection of retinal anomalies and diseases. Fundus image understanding, due to its knowledge-intensive nature, poses a challenging vision-language task. An emerging approach to addressing the task is to post-train a generic multimodal large language model (MLLM), either by supervised finetuning (SFT) or by reinforcement learning with verifiable rewards (RLVR), on a considerable amount of in-house samples paired with high-quality clinical reports. However, these valuable samples are not publicly accessible, which not only hinders reproducibility but also practically limits research to few players. To overcome the barrier, we make a novel attempt to train a reasoning-enhanced fundus-reading MLLM, which we term Fundus-R1, using exclusively public datasets, wherein over 94\% of the data are annotated with only image-level labels. Our technical contributions are two-fold. First, we propose a RAG-based method for composing image-specific, knowledge-aware reasoning traces. Such auto-generated traces link visual findings identified by a generic MLLM to the image labels in terms of ophthalmic knowledge. Second, we enhance RLVR with a process reward that encourages self-consistency of the generated reasoning trace in each rollout. Extensive experiments on three fundus-reading benchmarks, i.e., FunBench, Omni-Fundus and GMAI-Fundus, show that Fundus-R1 clearly outperforms multiple baselines, including its generic counterpart (Qwen2.5-VL) and a stronger edition post-trained without using the generated traces. This work paves the way for training powerful fundus-reading MLLMs with publicly available data.
EI: Early Intervention for Multimodal Imaging based Disease Recognition
Mar 18, 2026Current methods for multimodal medical imaging based disease recognition face two major challenges. First, the prevailing "fusion after unimodal image embedding" paradigm cannot fully leverage the complementary and correlated information in the multimodal data. Second, the scarcity of labeled multimodal medical images, coupled with their significant domain shift from natural images, hinders the use of cutting-edge Vision Foundation Models (VFMs) for medical image embedding. To jointly address the challenges, we propose a novel Early Intervention (EI) framework. Treating one modality as target and the rest as reference, EI harnesses high-level semantic tokens from the reference as intervention tokens to steer the target modality's embedding process at an early stage. Furthermore, we introduce Mixture of Low-varied-Ranks Adaptation (MoR), a parameter-efficient fine-tuning method that employs a set of low-rank adapters with varied ranks and a weight-relaxed router for VFM adaptation. Extensive experiments on three public datasets for retinal disease, skin lesion, and keen anomaly classification verify the effectiveness of the proposed method against a number of competitive baselines.
Cross-modal Fundus Image Registration under Large FoV Disparity
Dec 14, 2025Previous work on cross-modal fundus image registration (CMFIR) assumes small cross-modal Field-of-View (FoV) disparity. By contrast, this paper is targeted at a more challenging scenario with large FoV disparity, to which directly applying current methods fails. We propose Crop and Alignment for cross-modal fundus image Registration(CARe), a very simple yet effective method. Specifically, given an OCTA with smaller FoV as a source image and a wide-field color fundus photograph (wfCFP) as a target image, our Crop operation exploits the physiological structure of the retina to crop from the target image a sub-image with its FoV roughly aligned with that of the source. This operation allows us to re-purpose the previous small-FoV-disparity oriented methods for subsequent image registration. Moreover, we improve spatial transformation by a double-fitting based Alignment module that utilizes the classical RANSAC algorithm and polynomial-based coordinate fitting in a sequential manner. Extensive experiments on a newly developed test set of 60 OCTA-wfCFP pairs verify the viability of CARe for CMFIR.
FunBench: Benchmarking Fundus Reading Skills of MLLMs
Mar 02, 2025Multimodal Large Language Models (MLLMs) have shown significant potential in medical image analysis. However, their capabilities in interpreting fundus images, a critical skill for ophthalmology, remain under-evaluated. Existing benchmarks lack fine-grained task divisions and fail to provide modular analysis of its two key modules, i.e., large language model (LLM) and vision encoder (VE). This paper introduces FunBench, a novel visual question answering (VQA) benchmark designed to comprehensively evaluate MLLMs' fundus reading skills. FunBench features a hierarchical task organization across four levels (modality perception, anatomy perception, lesion analysis, and disease diagnosis). It also offers three targeted evaluation modes: linear-probe based VE evaluation, knowledge-prompted LLM evaluation, and holistic evaluation. Experiments on nine open-source MLLMs plus GPT-4o reveal significant deficiencies in fundus reading skills, particularly in basic tasks such as laterality recognition. The results highlight the limitations of current MLLMs and emphasize the need for domain-specific training and improved LLMs and VEs.
Convolutional Prompting for Broad-Domain Retinal Vessel Segmentation
Dec 24, 2024Previous research on retinal vessel segmentation is targeted at a specific image domain, mostly color fundus photography (CFP). In this paper we make a brave attempt to attack a more challenging task of broad-domain retinal vessel segmentation (BD-RVS), which is to develop a unified model applicable to varied domains including CFP, SLO, UWF, OCTA and FFA. To that end, we propose Dual Convoltuional Prompting (DCP) that learns to extract domain-specific features by localized prompting along both position and channel dimensions. DCP is designed as a plug-in module that can effectively turn a R2AU-Net based vessel segmentation network to a unified model, yet without the need of modifying its network structure. For evaluation we build a broad-domain set using five public domain-specific datasets including ROSSA, FIVES, IOSTAR, PRIME-FP20 and VAMPIRE. In order to benchmark BD-RVS on the broad-domain dataset, we re-purpose a number of existing methods originally developed in other contexts, producing eight baseline methods in total. Extensive experiments show the the proposed method compares favorably against the baselines for BD-RVS.
Cross-domain Collaborative Learning for Recognizing Multiple Retinal Diseases from Wide-Field Fundus Images
May 14, 2023This paper addresses the emerging task of recognizing multiple retinal diseases from wide-field (WF) and ultra-wide-field (UWF) fundus images. For an effective reuse of existing labeled color fundus photo (CFP) data, we propose Cross-domain Collaborative Learning (CdCL). Inspired by the success of fixed-ratio based mixup in unsupervised domain adaptation, we re-purpose this strategy for the current task. Due to the intrinsic disparity between the field-of-view of CFP and WF/UWF images, a scale bias naturally exists in a mixup sample that the anatomic structure from a CFP image will be considerably larger than its WF/UWF counterpart. The CdCL method resolves the issue by Scale-bias Correction, which employs Transformers for producing scale-invariant features. As demonstrated by extensive experiments on multiple datasets covering both WF and UWF images, the proposed method compares favorably against a number of competitive baselines.
Semi-Supervised Keypoint Detector and Descriptor for Retinal Image Matching
Jul 16, 2022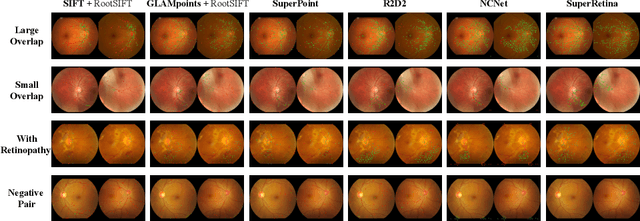
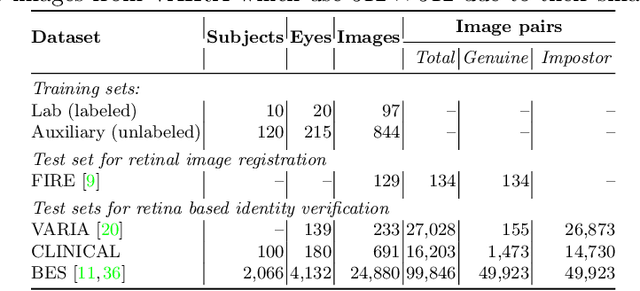
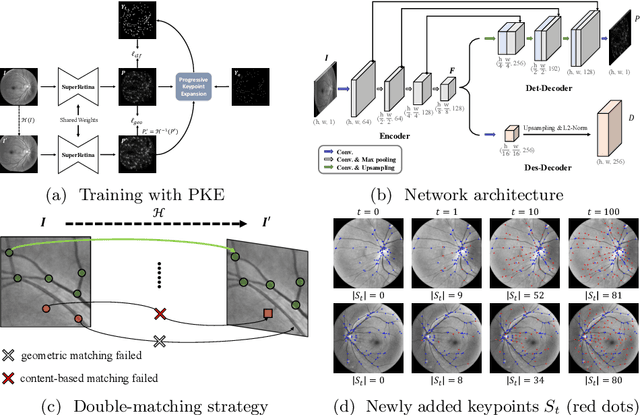
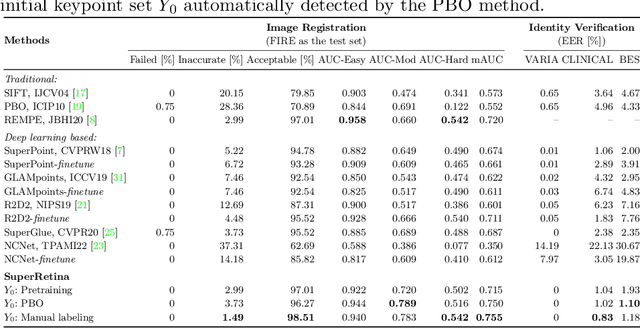
For retinal image matching (RIM), we propose SuperRetina, the first end-to-end method with jointly trainable keypoint detector and descriptor. SuperRetina is trained in a novel semi-supervised manner. A small set of (nearly 100) images are incompletely labeled and used to supervise the network to detect keypoints on the vascular tree. To attack the incompleteness of manual labeling, we propose Progressive Keypoint Expansion to enrich the keypoint labels at each training epoch. By utilizing a keypoint-based improved triplet loss as its description loss, SuperRetina produces highly discriminative descriptors at full input image size. Extensive experiments on multiple real-world datasets justify the viability of SuperRetina. Even with manual labeling replaced by auto labeling and thus making the training process fully manual-annotation free, SuperRetina compares favorably against a number of strong baselines for two RIM tasks, i.e. image registration and identity verification. SuperRetina will be open source.
Co-Teaching for Unsupervised Domain Adaptation and Expansion
Apr 04, 2022
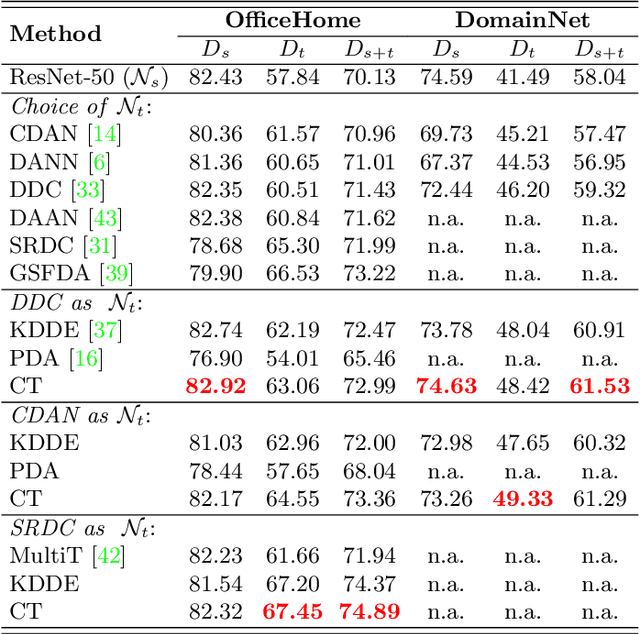
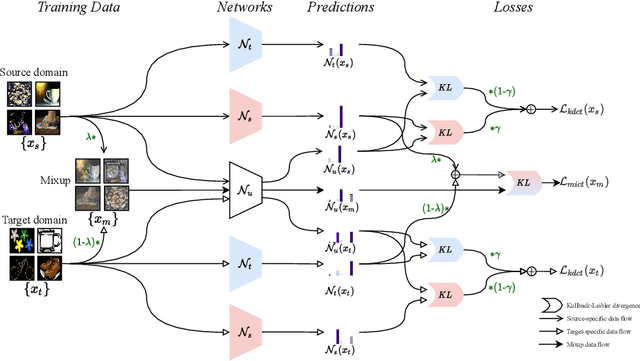
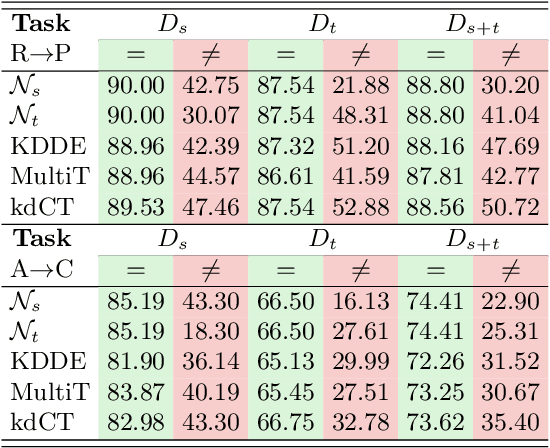
Unsupervised Domain Adaptation (UDA) is known to trade a model's performance on a source domain for improving its performance on a target domain. To resolve the issue, Unsupervised Domain Expansion (UDE) has been proposed recently to adapt the model for the target domain as UDA does, and in the meantime maintain its performance on the source domain. For both UDA and UDE, a model tailored to a given domain, let it be the source or the target domain, is assumed to well handle samples from the given domain. We question the assumption by reporting the existence of cross-domain visual ambiguity: Due to the lack of a crystally clear boundary between the two domains, samples from one domain can be visually close to the other domain. We exploit this finding and accordingly propose in this paper Co-Teaching (CT) that consists of knowledge distillation based CT (kdCT) and mixup based CT (miCT). Specifically, kdCT transfers knowledge from a leader-teacher network and an assistant-teacher network to a student network, so the cross-domain visual ambiguity will be better handled by the student. Meanwhile, miCT further enhances the generalization ability of the student. Comprehensive experiments on two image-classification benchmarks and two driving-scene-segmentation benchmarks justify the viability of the proposed method.
Learn to Segment Retinal Lesions and Beyond
Dec 25, 2019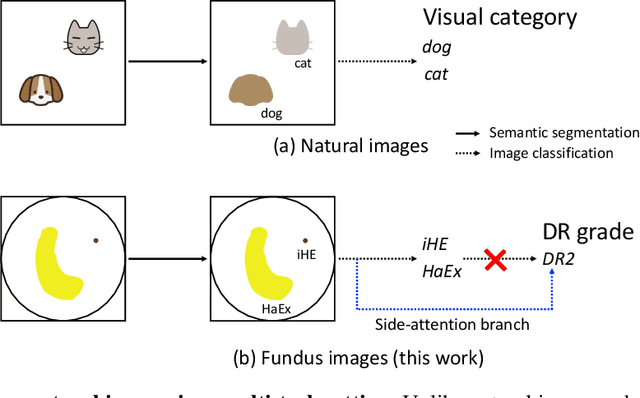
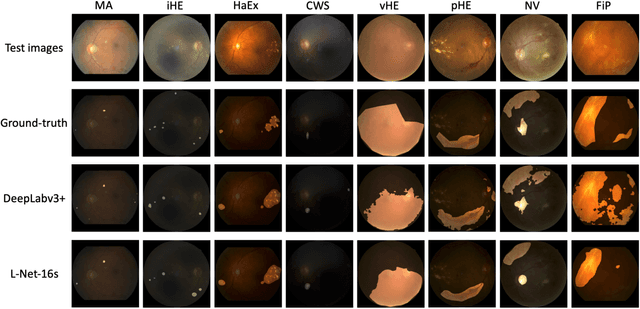
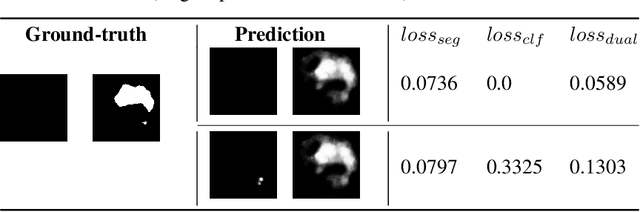
Towards automated retinal screening, this paper makes an endeavor to simultaneously achieve pixel-level retinal lesion segmentation and image-level disease classification. Such a multi-task approach is crucial for accurate and clinically interpretable disease diagnosis. Prior art is insufficient due to three challenges, that is, lesions lacking objective boundaries, clinical importance of lesions irrelevant to their size, and the lack of one-to-one correspondence between lesion and disease classes. This paper attacks the three challenges in the context of diabetic retinopathy (DR) grading. We propose L-Net, a new variant of fully convolutional networks, with its expansive path re-designed to tackle the first challenge. A dual loss that leverages both semantic segmentation and image classification losses is devised to resolve the second challenge. We propose Side-Attention Net (SiAN) as our multi-task framework. Harnessing L-Net as a side-attention branch, SiAN simultaneously improves DR grading and interprets the decision with lesion maps. A set of 12K fundus images is manually segmented by 45 ophthalmologists for 8 DR-related lesions, resulting in 290K manual segments in total. Extensive experiments on this large-scale dataset show that our proposed approach surpasses the prior art for multiple tasks including lesion segmentation, lesion classification and DR grading.
COCO-CN for Cross-Lingual Image Tagging, Captioning and Retrieval
May 22, 2018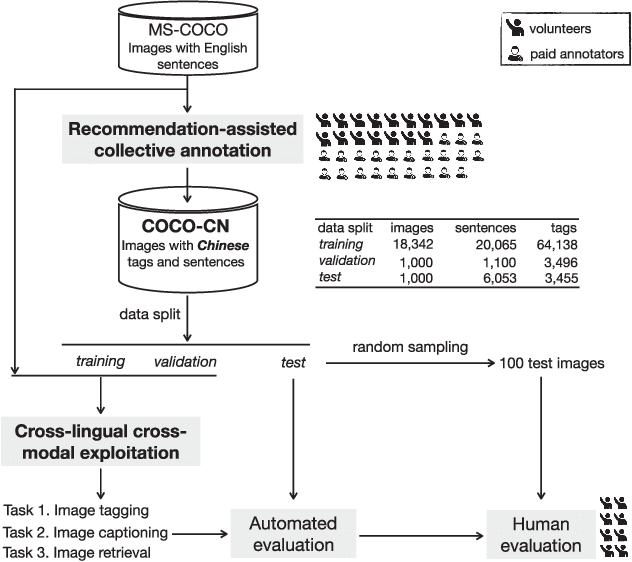
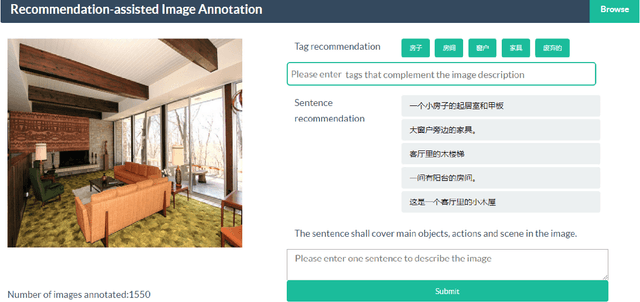
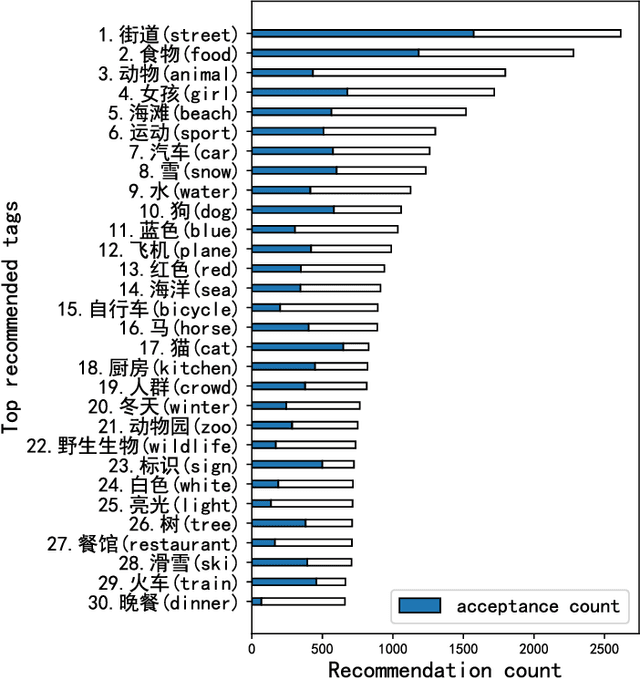
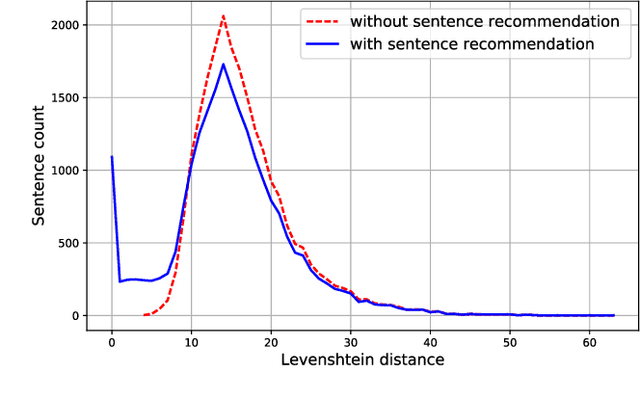
This paper contributes to cross-lingual image annotation and retrieval in terms of data and methods. We propose COCO-CN, a novel dataset enriching MS-COCO with manually written Chinese sentences and tags. For more effective annotation acquisition, we develop a recommendation-assisted collective annotation system, automatically providing an annotator with several tags and sentences deemed to be relevant with respect to the pictorial content. Having 20,342 images annotated with 27,218 Chinese sentences and 70,993 tags, COCO-CN is currently the largest Chinese-English dataset applicable for cross-lingual image tagging, captioning and retrieval. We develop methods per task for effectively learning from cross-lingual resources. Extensive experiments on the multiple tasks justify the viability of our dataset and methods.