 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Contexts to Locality: Ultra-high Resolution Image Segmentation via Locality-aware Contextual Correlation
Sep 06, 2021
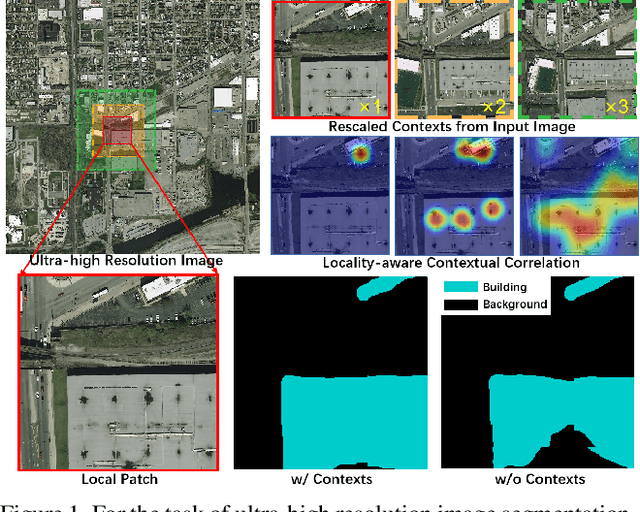
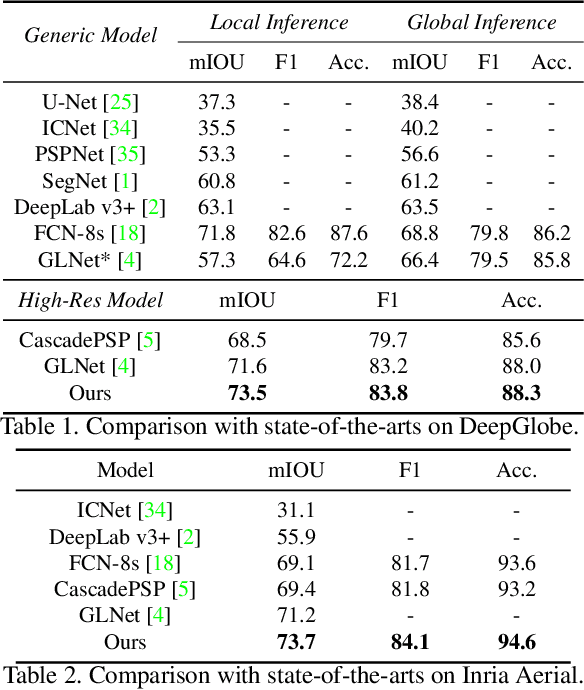
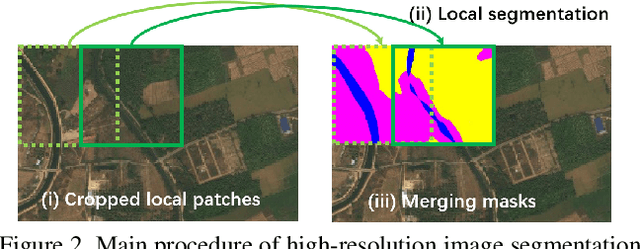
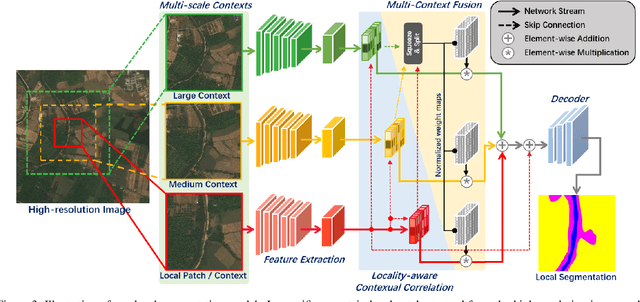
Ultra-high resolution image segmentation has raised increasing interests in recent years due to its realistic applications. In this paper, we innovate the widely used high-resolution image segmentation pipeline, in which an ultra-high resolution image is partitioned into regular patches for local segmentation and then the local results are merged into a high-resolution semantic mask. In particular, we introduce a novel locality-aware contextual correlation based segmentation model to process local patches, where the relevance between local patch and its various contexts are jointly and complementarily utilized to handle the semantic regions with large variations. Additionally, we present a contextual semantics refinement network that associates the local segmentation result with its contextual semantics, and thus is endowed with the ability of reducing boundary artifacts and refining mask contours during the generation of final high-resolution mask. Furthermore, in comprehensive experiments, we demonstrate that our model outperforms other state-of-the-art methods in public benchmarks. Our released codes are available at https://github.com/liqiokkk/FCtL.
EDPN: Enhanced Deep Pyramid Network for Blurry Image Restoration
May 11, 2021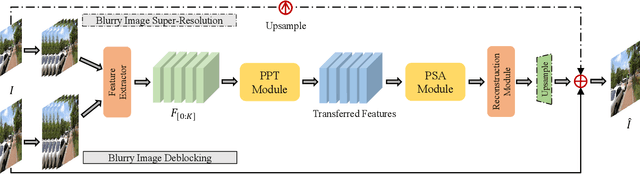
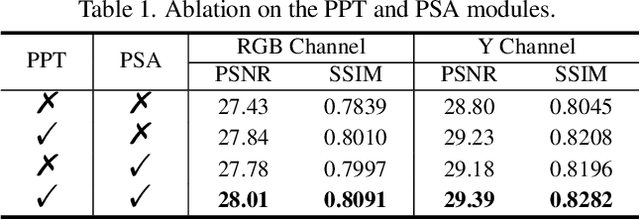
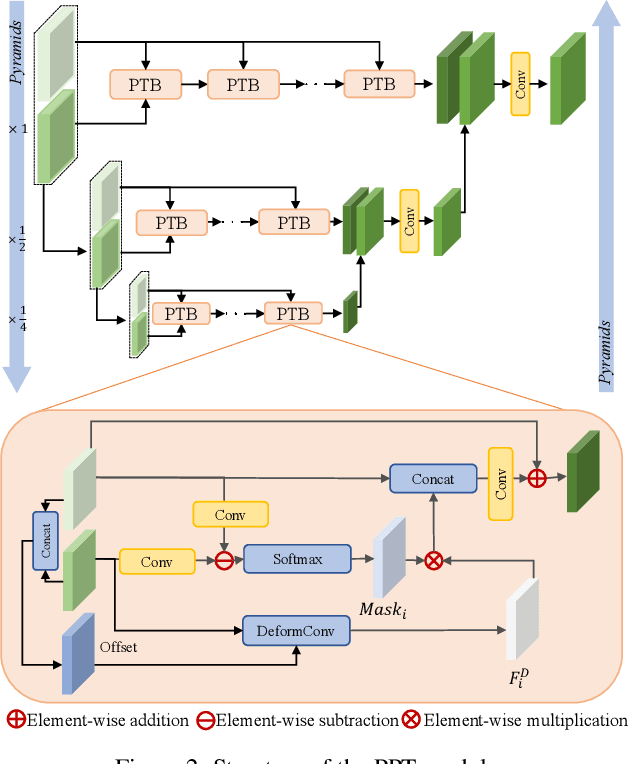
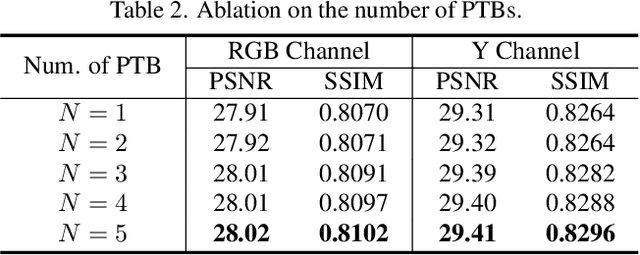
Image deblurring has seen a great improvement with the development of deep neural networks. In practice, however, blurry images often suffer from additional degradations such as downscaling and compression. To address these challenges, we propose an Enhanced Deep Pyramid Network (EDPN) for blurry image restoration from multiple degradations, by fully exploiting the self- and cross-scale similarities in the degraded image.Specifically, we design two pyramid-based modules, i.e., the pyramid progressive transfer (PPT) module and the pyramid self-attention (PSA) module, as the main components of the proposed network. By taking several replicated blurry images as inputs, the PPT module transfers both self- and cross-scale similarity information from the same degraded image in a progressive manner. Then, the PSA module fuses the above transferred features for subsequent restoration using self- and spatial-attention mechanisms. Experimental results demonstrate that our method significantly outperforms existing solutions for blurry image super-resolution and blurry image deblocking. In the NTIRE 2021 Image Deblurring Challenge, EDPN achieves the best PSNR/SSIM/LPIPS scores in Track 1 (Low Resolution) and the best SSIM/LPIPS scores in Track 2 (JPEG Artifacts).
Vision-Language Pre-Training with Triple Contrastive Learning
Mar 28, 2022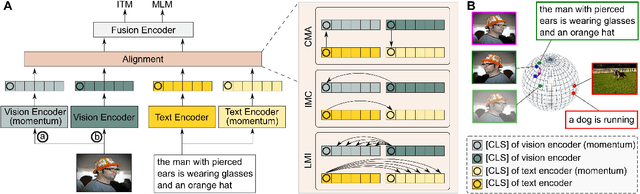

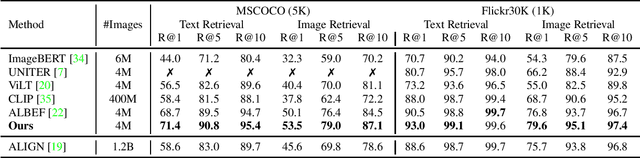
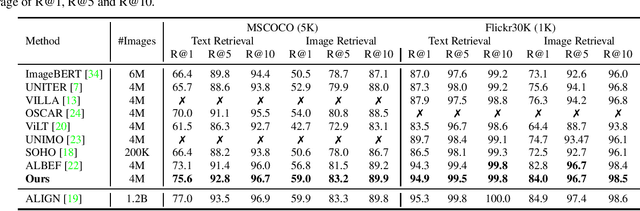
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieves the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.
Transformer-Based Deep Image Matching for Generalizable Person Re-identification
May 30, 2021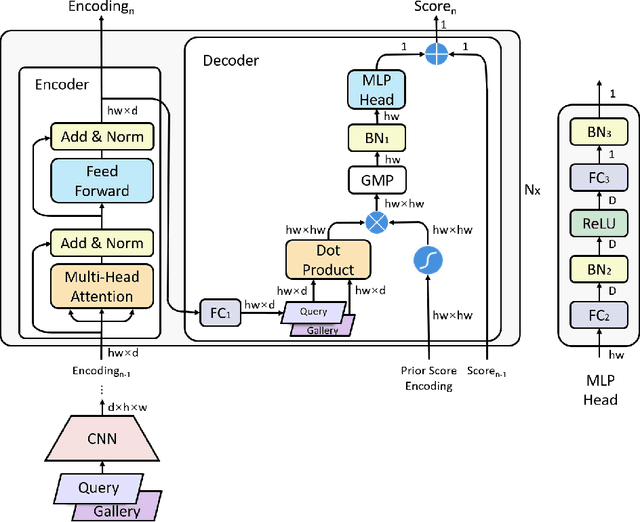
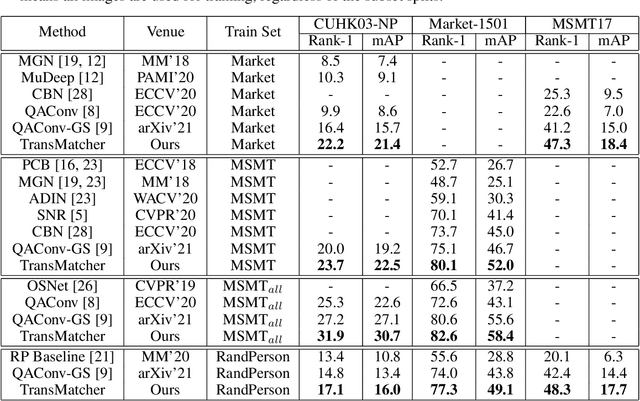
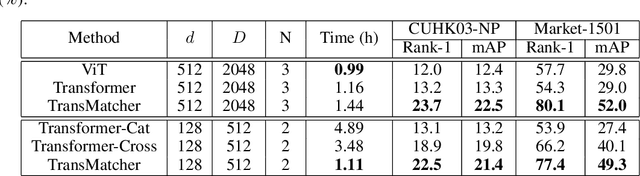
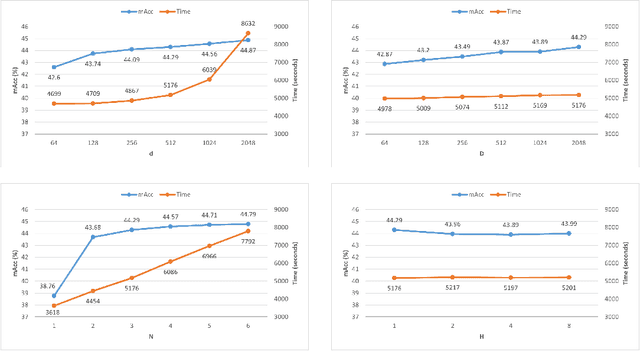
Transformers have recently gained increasing attention in computer vision. However, existing studies mostly use Transformers for feature representation learning, e.g. for image classification and dense predictions. In this work, we further investigate the possibility of applying Transformers for image matching and metric learning given pairs of images. We find that the Vision Transformer (ViT) and the vanilla Transformer with decoders are not adequate for image matching due to their lack of image-to-image attention. Thus, we further design two naive solutions, i.e. query-gallery concatenation in ViT, and query-gallery cross-attention in the vanilla Transformer. The latter improves the performance, but it is still limited. This implies that the attention mechanism in Transformers is primarily designed for global feature aggregation, which is not naturally suitable for image matching. Accordingly, we propose a new simplified decoder, which drops the full attention implementation with the softmax weighting, keeping only the query-key similarity computation. Additionally, global max pooling and a multilayer perceptron (MLP) head are applied to decode the matching result. This way, the simplified decoder is computationally more efficient, while at the same time more effective for image matching. The proposed method, called TransMatcher, achieves state-of-the-art performance in generalizable person re-identification, with up to 6.1% and 5.7% performance gains in Rank-1 and mAP, respectively, on several popular datasets. The source code of this study will be made publicly available.
In&Out : Diverse Image Outpainting via GAN Inversion
Apr 01, 2021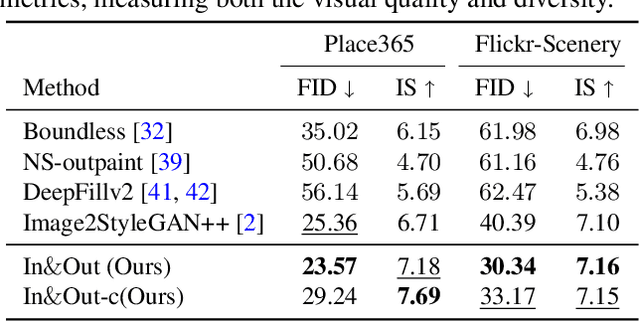
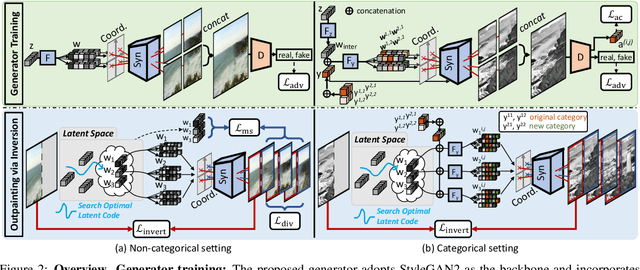
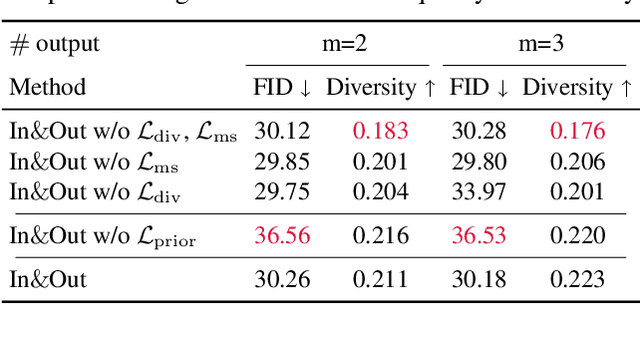
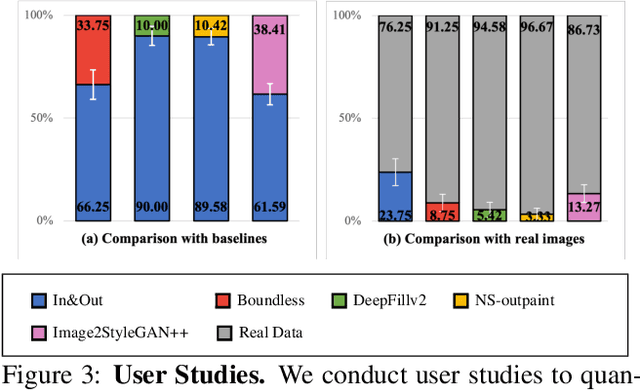
Image outpainting seeks for a semantically consistent extension of the input image beyond its available content. Compared to inpainting -- filling in missing pixels in a way coherent with the neighboring pixels -- outpainting can be achieved in more diverse ways since the problem is less constrained by the surrounding pixels. Existing image outpainting methods pose the problem as a conditional image-to-image translation task, often generating repetitive structures and textures by replicating the content available in the input image. In this work, we formulate the problem from the perspective of inverting generative adversarial networks. Our generator renders micro-patches conditioned on their joint latent code as well as their individual positions in the image. To outpaint an image, we seek for multiple latent codes not only recovering available patches but also synthesizing diverse outpainting by patch-based generation. This leads to richer structure and content in the outpainted regions. Furthermore, our formulation allows for outpainting conditioned on the categorical input, thereby enabling flexible user controls. Extensive experimental results demonstrate the proposed method performs favorably against existing in- and outpainting methods, featuring higher visual quality and diversity.
Adversarial Robustness Assessment of NeuroEvolution Approaches
Jul 12, 2022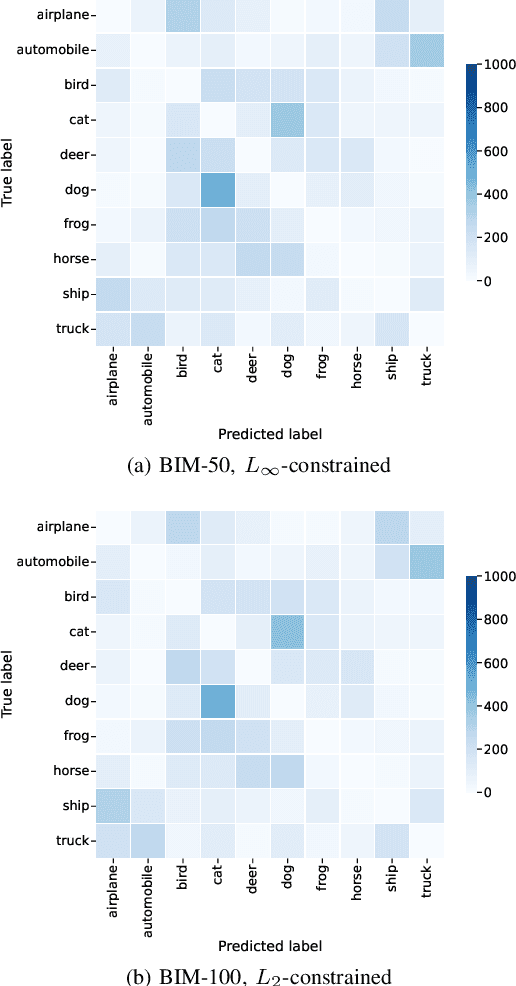
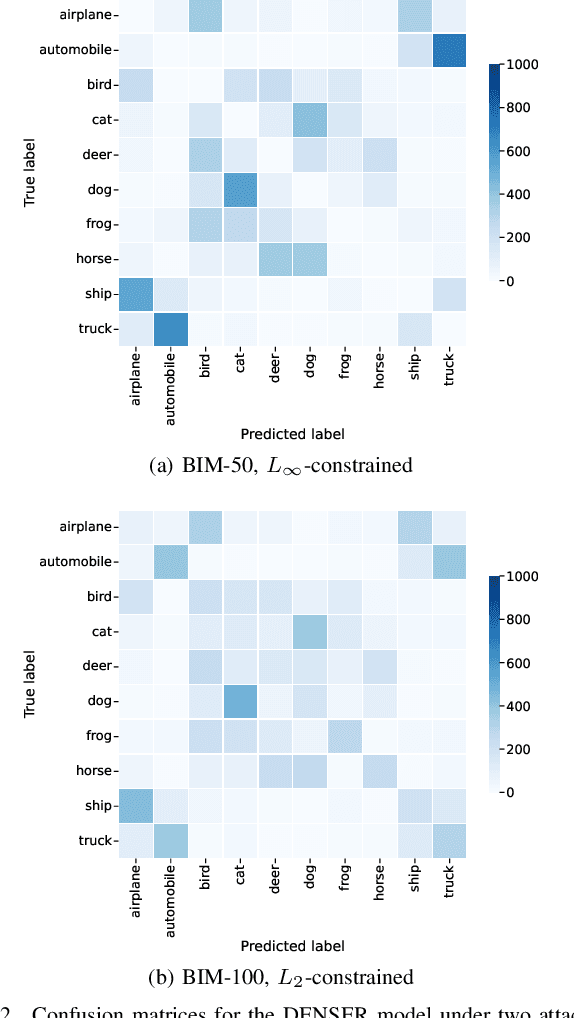
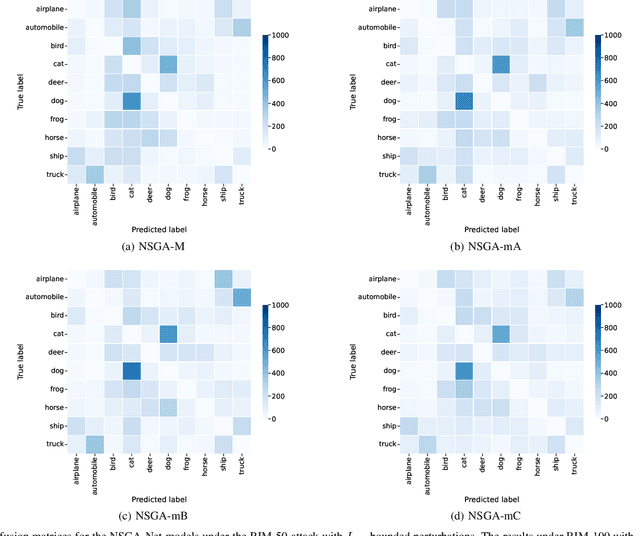
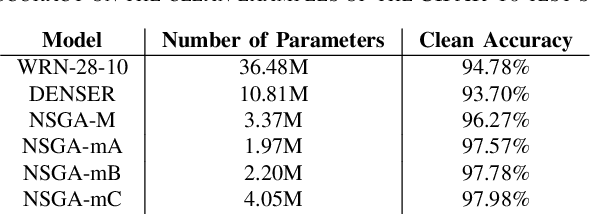
NeuroEvolution automates the generation of Artificial Neural Networks through the application of techniques from Evolutionary Computation. The main goal of these approaches is to build models that maximize predictive performance, sometimes with an additional objective of minimizing computational complexity. Although the evolved models achieve competitive results performance-wise, their robustness to adversarial examples, which becomes a concern in security-critical scenarios, has received limited attention. In this paper, we evaluate the adversarial robustness of models found by two prominent NeuroEvolution approaches on the CIFAR-10 image classification task: DENSER and NSGA-Net. Since the models are publicly available, we consider white-box untargeted attacks, where the perturbations are bounded by either the L2 or the Linfinity-norm. Similarly to manually-designed networks, our results show that when the evolved models are attacked with iterative methods, their accuracy usually drops to, or close to, zero under both distance metrics. The DENSER model is an exception to this trend, showing some resistance under the L2 threat model, where its accuracy only drops from 93.70% to 18.10% even with iterative attacks. Additionally, we analyzed the impact of pre-processing applied to the data before the first layer of the network. Our observations suggest that some of these techniques can exacerbate the perturbations added to the original inputs, potentially harming robustness. Thus, this choice should not be neglected when automatically designing networks for applications where adversarial attacks are prone to occur.
Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection
Apr 26, 2022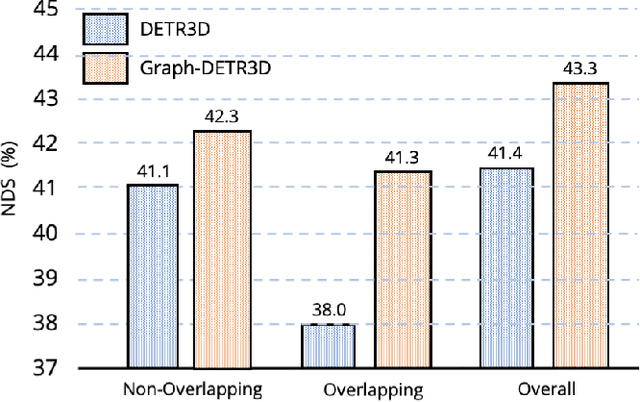
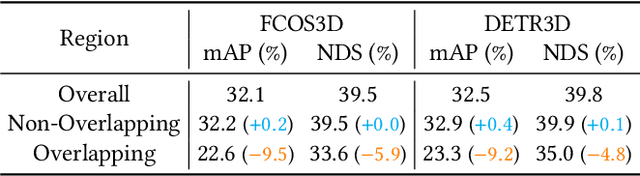

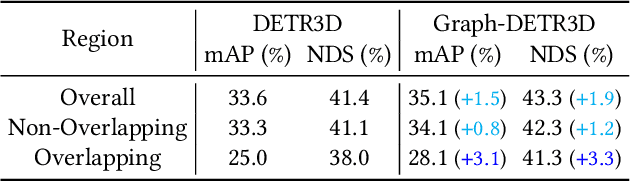
3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Due to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views in the 3D space is extremely difficult due to the lack of depth information. Recently, DETR3D introduces a novel 3D-2D query paradigm in aggregating multi-view images for 3D object detection and achieves state-of-the-art performance. In this paper, with intensive pilot experiments, we quantify the objects located at different regions and find that the "truncated instances" (i.e., at the border regions of each image) are the main bottleneck hindering the performance of DETR3D. Although it merges multiple features from two adjacent views in the overlapping regions, DETR3D still suffers from insufficient feature aggregation, thus missing the chance to fully boost the detection performance. In an effort to tackle the problem, we propose Graph-DETR3D to automatically aggregate multi-view imagery information through graph structure learning (GSL). It constructs a dynamic 3D graph between each object query and 2D feature maps to enhance the object representations, especially at the border regions. Besides, Graph-DETR3D benefits from a novel depth-invariant multi-scale training strategy, which maintains the visual depth consistency by simultaneously scaling the image size and the object depth. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of our Graph-DETR3D. Notably, our best model achieves 49.5 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various published image-view 3D object detectors.
Open-source FPGA-ML codesign for the MLPerf Tiny Benchmark
Jun 23, 2022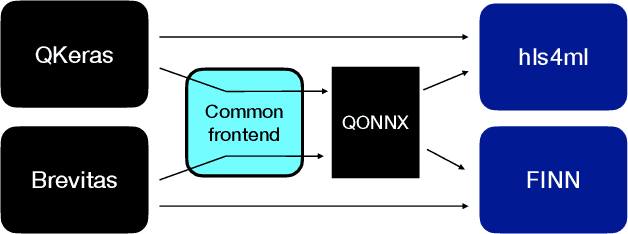
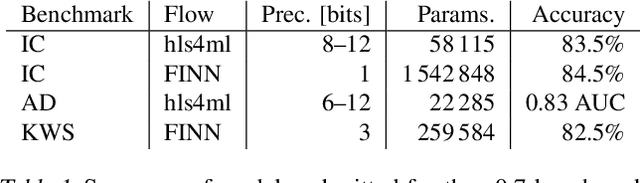
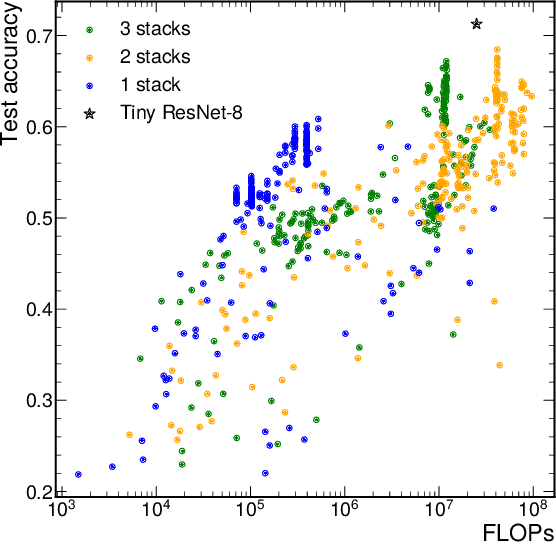
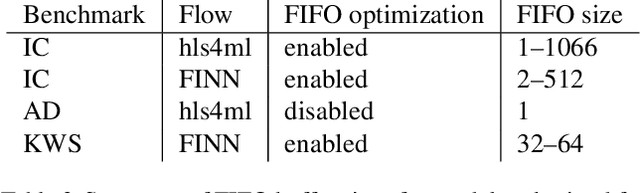
We present our development experience and recent results for the MLPerf Tiny Inference Benchmark on field-programmable gate array (FPGA) platforms. We use the open-source hls4ml and FINN workflows, which aim to democratize AI-hardware codesign of optimized neural networks on FPGAs. We present the design and implementation process for the keyword spotting, anomaly detection, and image classification benchmark tasks. The resulting hardware implementations are quantized, configurable, spatial dataflow architectures tailored for speed and efficiency and introduce new generic optimizations and common workflows developed as a part of this work. The full workflow is presented from quantization-aware training to FPGA implementation. The solutions are deployed on system-on-chip (Pynq-Z2) and pure FPGA (Arty A7-100T) platforms. The resulting submissions achieve latencies as low as 20 $\mu$s and energy consumption as low as 30 $\mu$J per inference. We demonstrate how emerging ML benchmarks on heterogeneous hardware platforms can catalyze collaboration and the development of new techniques and more accessible tools.
Semantic similarity metrics for learned image registration
Apr 20, 2021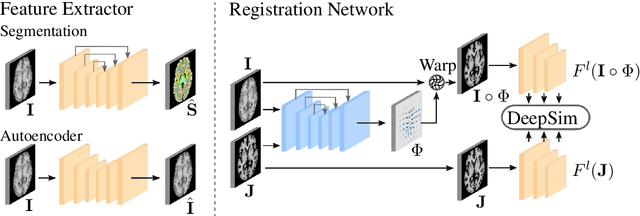
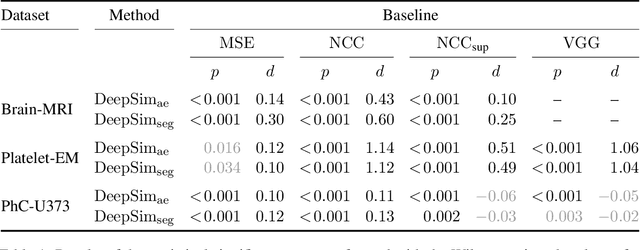
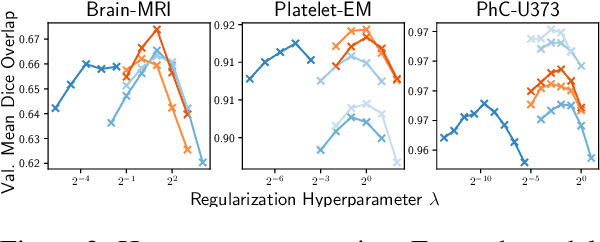
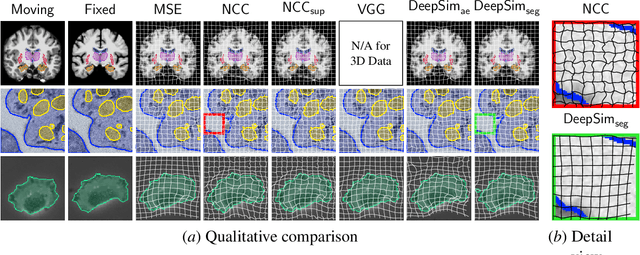
We propose a semantic similarity metric for image registration. Existing metrics like Euclidean Distance or Normalized Cross-Correlation focus on aligning intensity values, giving difficulties with low intensity contrast or noise. Our approach learns dataset-specific features that drive the optimization of a learning-based registration model. We train both an unsupervised approach using an auto-encoder, and a semi-supervised approach using supplemental segmentation data to extract semantic features for image registration. Comparing to existing methods across multiple image modalities and applications, we achieve consistently high registration accuracy. A learned invariance to noise gives smoother transformations on low-quality images.
MAT: Mask-Aware Transformer for Large Hole Image Inpainting
Mar 30, 2022



Recent studies have shown the importance of modeling long-range interactions in the inpainting problem. To achieve this goal, existing approaches exploit either standalone attention techniques or transformers, but usually under a low resolution in consideration of computational cost. In this paper, we present a novel transformer-based model for large hole inpainting, which unifies the merits of transformers and convolutions to efficiently process high-resolution images. We carefully design each component of our framework to guarantee the high fidelity and diversity of recovered images. Specifically, we customize an inpainting-oriented transformer block, where the attention module aggregates non-local information only from partial valid tokens, indicated by a dynamic mask. Extensive experiments demonstrate the state-of-the-art performance of the new model on multiple benchmark datasets. Code is released at https://github.com/fenglinglwb/MAT.