 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnCommon Objects in 3D
Jan 13, 2025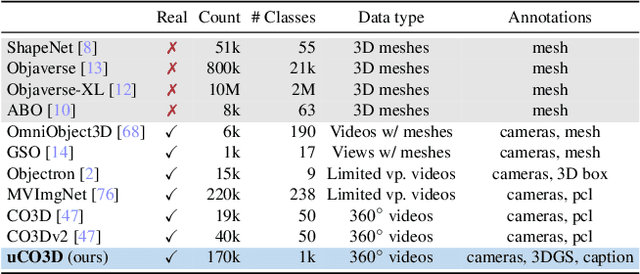
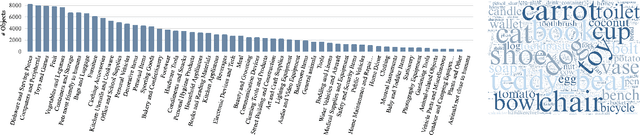


We introduce Uncommon Objects in 3D (uCO3D), a new object-centric dataset for 3D deep learning and 3D generative AI. uCO3D is the largest publicly-available collection of high-resolution videos of objects with 3D annotations that ensures full-360$^{\circ}$ coverage. uCO3D is significantly more diverse than MVImgNet and CO3Dv2, covering more than 1,000 object categories. It is also of higher quality, due to extensive quality checks of both the collected videos and the 3D annotations. Similar to analogous datasets, uCO3D contains annotations for 3D camera poses, depth maps and sparse point clouds. In addition, each object is equipped with a caption and a 3D Gaussian Splat reconstruction. We train several large 3D models on MVImgNet, CO3Dv2, and uCO3D and obtain superior results using the latter, showing that uCO3D is better for learning applications.
Human Decision Makings on Curriculum Reinforcement Learning with Difficulty Adjustment
Aug 04, 2022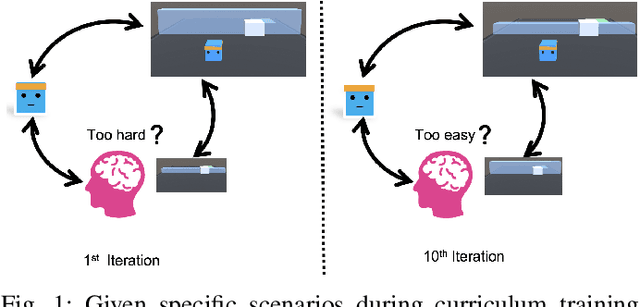
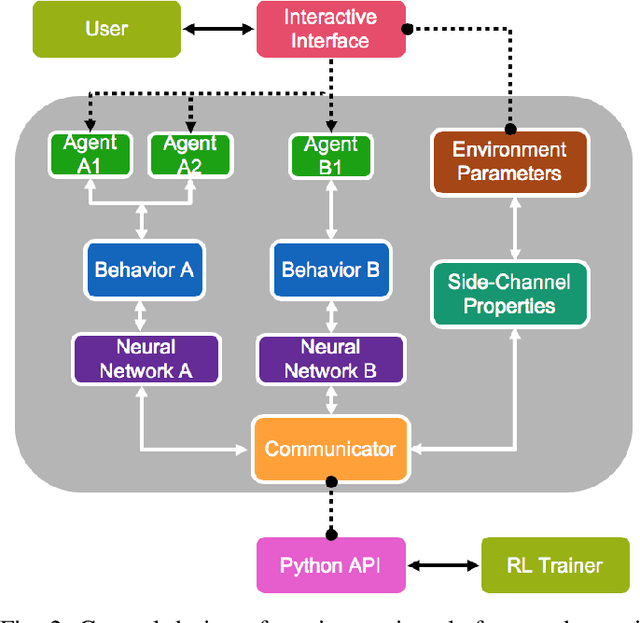
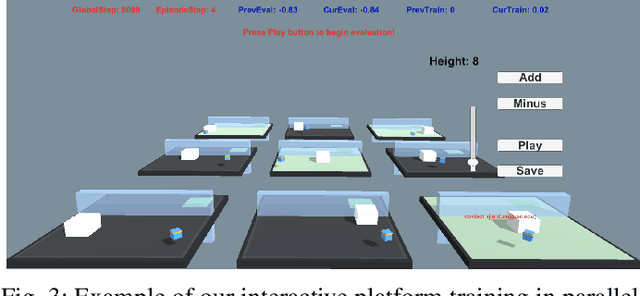
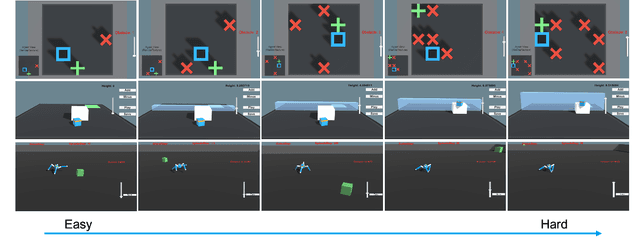
Human-centered AI considers human experiences with AI performance. While abundant research has been helping AI achieve superhuman performance either by fully automatic or weak supervision learning, fewer endeavors are experimenting with how AI can tailor to humans' preferred skill level given fine-grained input. In this work, we guide the curriculum reinforcement learning results towards a preferred performance level that is neither too hard nor too easy via learning from the human decision process. To achieve this, we developed a portable, interactive platform that enables the user to interact with agents online via manipulating the task difficulty, observing performance, and providing curriculum feedback. Our system is highly parallelizable, making it possible for a human to train large-scale reinforcement learning applications that require millions of samples without a server. The result demonstrates the effectiveness of an interactive curriculum for reinforcement learning involving human-in-the-loop. It shows reinforcement learning performance can successfully adjust in sync with the human desired difficulty level. We believe this research will open new doors for achieving flow and personalized adaptive difficulties.
Augmenting Vision Language Pretraining by Learning Codebook with Visual Semantics
Jul 31, 2022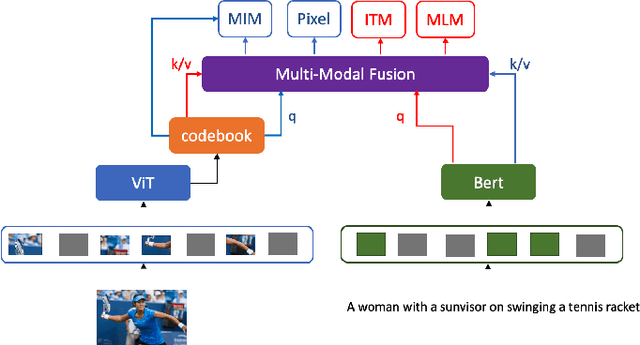



Language modality within the vision language pretraining framework is innately discretized, endowing each word in the language vocabulary a semantic meaning. In contrast, visual modality is inherently continuous and high-dimensional, which potentially prohibits the alignment as well as fusion between vision and language modalities. We therefore propose to "discretize" the visual representation by joint learning a codebook that imbues each visual token a semantic. We then utilize these discretized visual semantics as self-supervised ground-truths for building our Masked Image Modeling objective, a counterpart of Masked Language Modeling which proves successful for language models. To optimize the codebook, we extend the formulation of VQ-VAE which gives a theoretic guarantee. Experiments validate the effectiveness of our approach across common vision-language benchmarks.
Convergence and sample complexity of natural policy gradient primal-dual methods for constrained MDPs
Jun 06, 2022
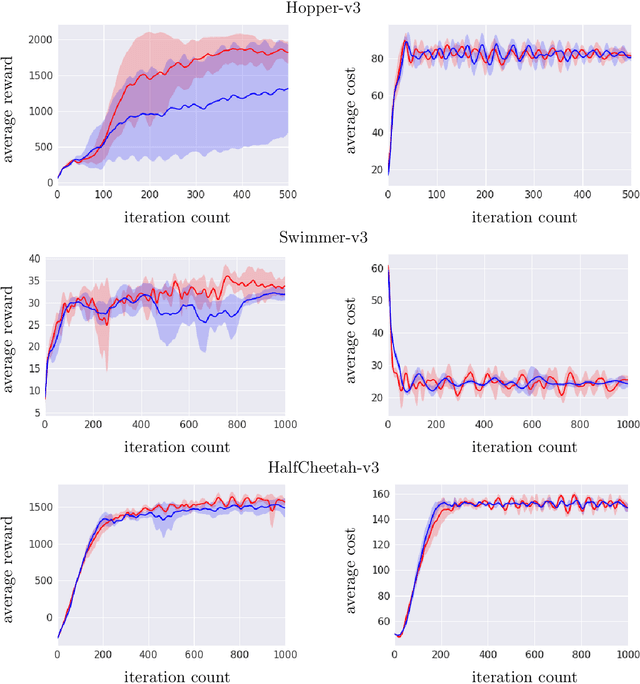
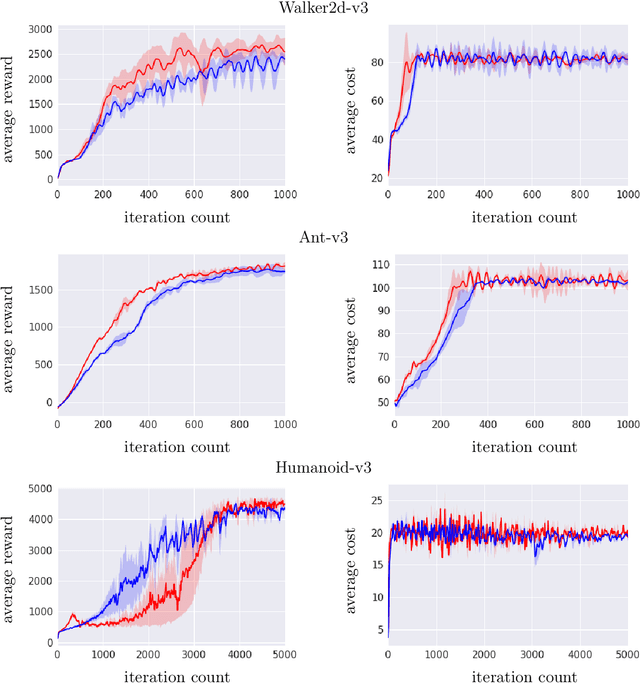
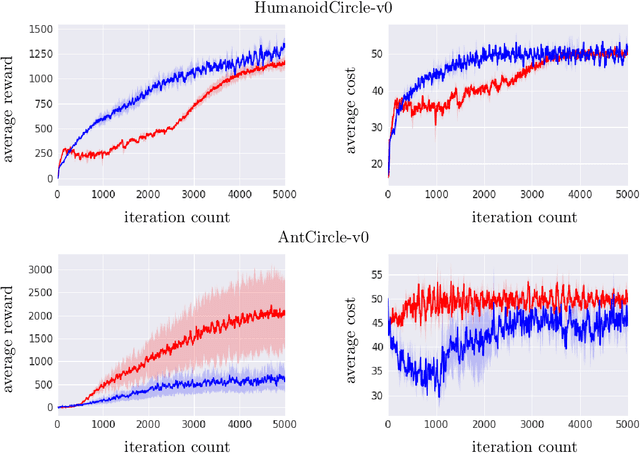
We study sequential decision making problems aimed at maximizing the expected total reward while satisfying a constraint on the expected total utility. We employ the natural policy gradient method to solve the discounted infinite-horizon optimal control problem for Constrained Markov Decision Processes (constrained MDPs). Specifically, we propose a new Natural Policy Gradient Primal-Dual (NPG-PD) method that updates the primal variable via natural policy gradient ascent and the dual variable via projected sub-gradient descent. Although the underlying maximization involves a nonconcave objective function and a nonconvex constraint set, under the softmax policy parametrization we prove that our method achieves global convergence with sublinear rates regarding both the optimality gap and the constraint violation. Such convergence is independent of the size of the state-action space, i.e., it is~dimension-free. Furthermore, for log-linear and general smooth policy parametrizations, we establish sublinear convergence rates up to a function approximation error caused by restricted policy parametrization. We also provide convergence and finite-sample complexity guarantees for two sample-based NPG-PD algorithms. Finally, we use computational experiments to showcase the merits and the effectiveness of our approach.
OSCARS: An Outlier-Sensitive Content-Based Radiography Retrieval System
Apr 06, 2022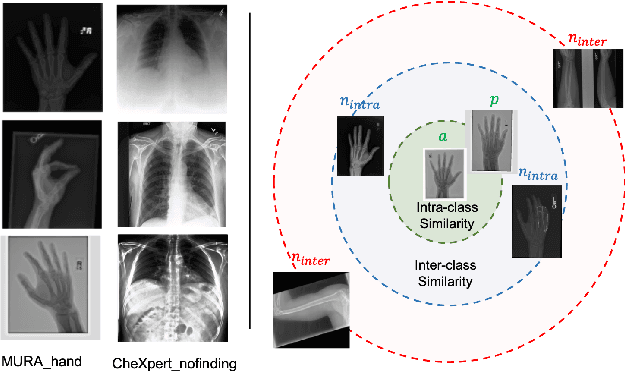

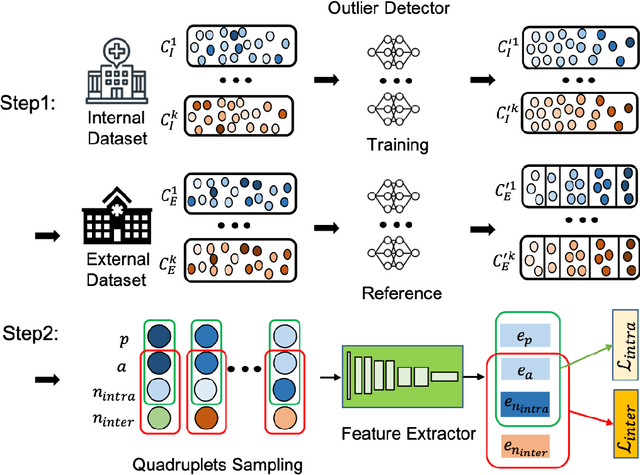

Improving the retrieval relevance on noisy datasets is an emerging need for the curation of a large-scale clean dataset in the medical domain. While existing methods can be applied for class-wise retrieval (aka. inter-class), they cannot distinguish the granularity of likeness within the same class (aka. intra-class). The problem is exacerbated on medical external datasets, where noisy samples of the same class are treated equally during training. Our goal is to identify both intra/inter-class similarities for fine-grained retrieval. To achieve this, we propose an Outlier-Sensitive Content-based rAdiologhy Retrieval System (OSCARS), consisting of two steps. First, we train an outlier detector on a clean internal dataset in an unsupervised manner. Then we use the trained detector to generate the anomaly scores on the external dataset, whose distribution will be used to bin intra-class variations. Second, we propose a quadruplet (a, p, nintra, ninter) sampling strategy, where intra-class negatives nintra are sampled from bins of the same class other than the bin anchor a belongs to, while niner are randomly sampled from inter-classes. We suggest a weighted metric learning objective to balance the intra and inter-class feature learning. We experimented on two representative public radiography datasets. Experiments show the effectiveness of our approach. The training and evaluation code can be found in https://github.com/XiaoyuanGuo/oscars.
Vision-Language Pre-Training with Triple Contrastive Learning
Mar 28, 2022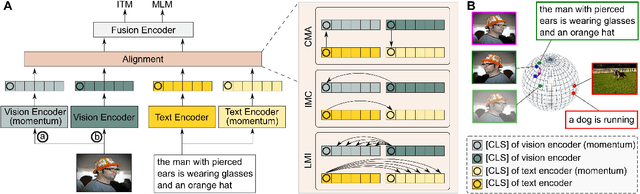

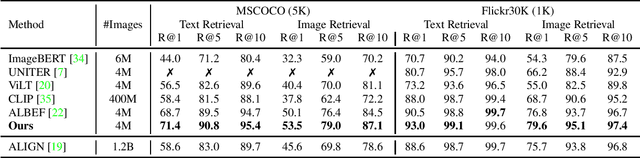
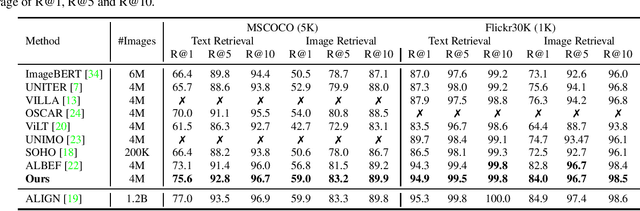
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieves the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.
Multi-modal Alignment using Representation Codebook
Mar 28, 2022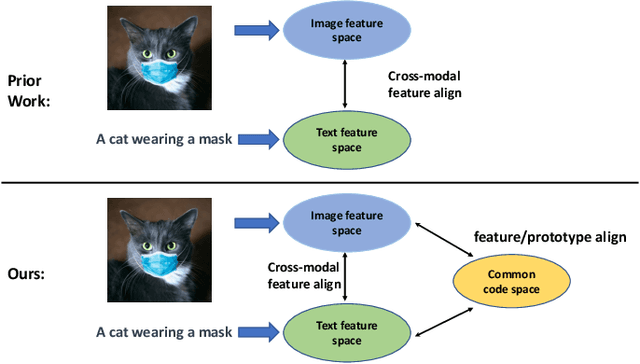
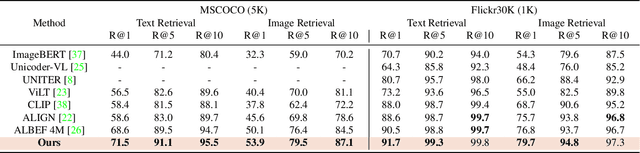
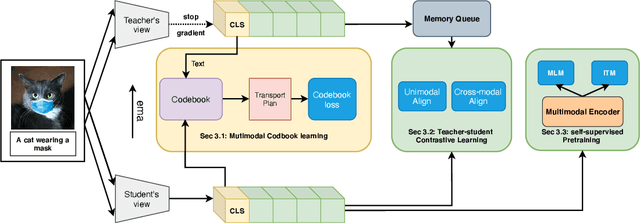
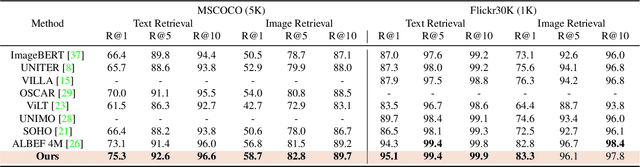
Aligning signals from different modalities is an important step in vision-language representation learning as it affects the performance of later stages such as cross-modality fusion. Since image and text typically reside in different regions of the feature space, directly aligning them at instance level is challenging especially when features are still evolving during training. In this paper, we propose to align at a higher and more stable level using cluster representation. Specifically, we treat image and text as two "views" of the same entity, and encode them into a joint vision-language coding space spanned by a dictionary of cluster centers (codebook). We contrast positive and negative samples via their cluster assignments while simultaneously optimizing the cluster centers. To further smooth out the learning process, we adopt a teacher-student distillation paradigm, where the momentum teacher of one view guides the student learning of the other. We evaluated our approach on common vision language benchmarks and obtain new SoTA on zero-shot cross modality retrieval while being competitive on various other transfer tasks.
Bridging Gap between Image Pixels and Semantics via Supervision: A Survey
Jul 29, 2021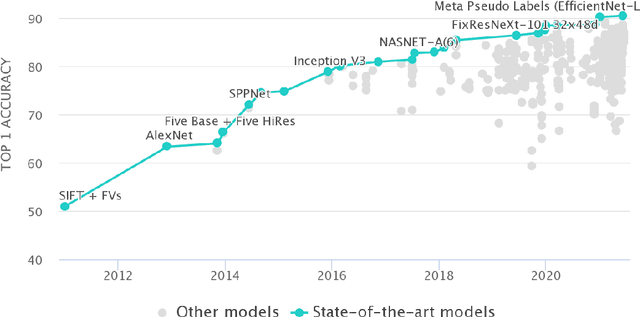
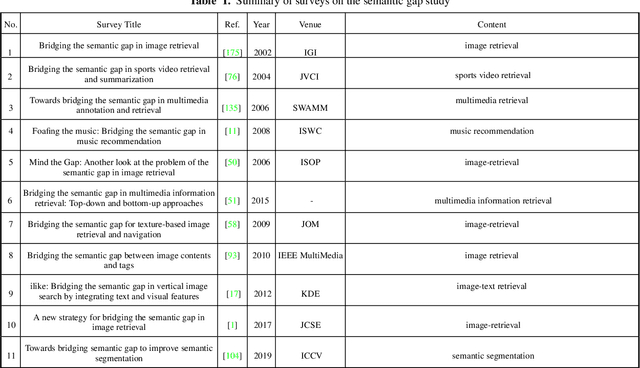

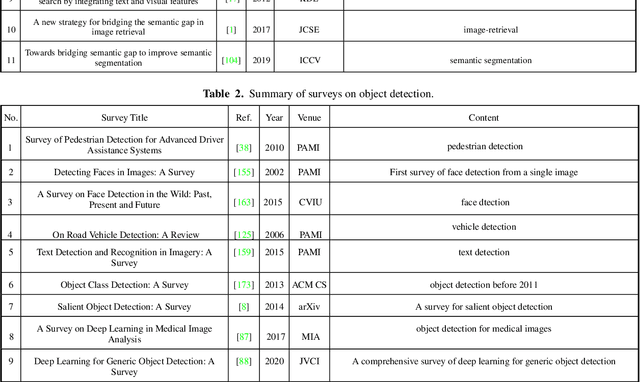
The fact that there exists a gap between low-level features and semantic meanings of images, called the semantic gap, is known for decades. Resolution of the semantic gap is a long standing problem. The semantic gap problem is reviewed and a survey on recent efforts in bridging the gap is made in this work. Most importantly, we claim that the semantic gap is primarily bridged through supervised learning today. Experiences are drawn from two application domains to illustrate this point: 1) object detection and 2) metric learning for content-based image retrieval (CBIR). To begin with, this paper offers a historical retrospective on supervision, makes a gradual transition to the modern data-driven methodology and introduces commonly used datasets. Then, it summarizes various supervision methods to bridge the semantic gap in the context of object detection and metric learning.
SLADE: A Self-Training Framework For Distance Metric Learning
Nov 20, 2020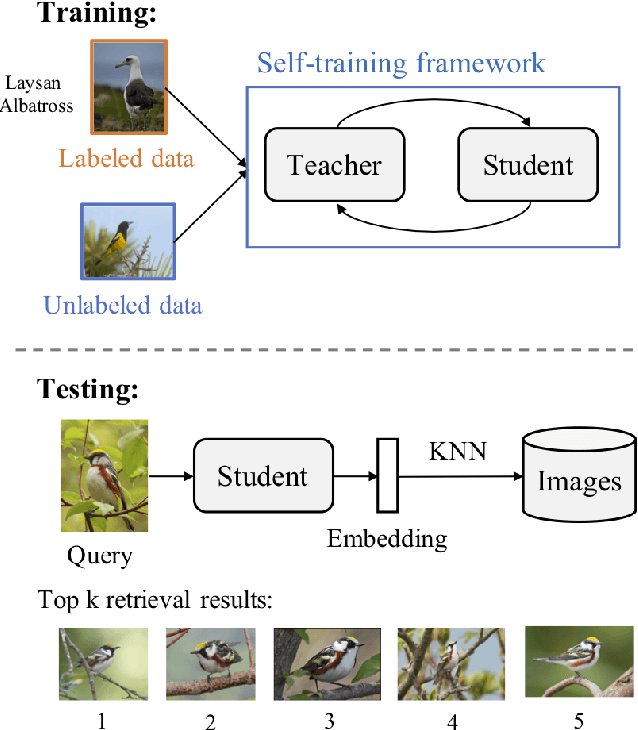
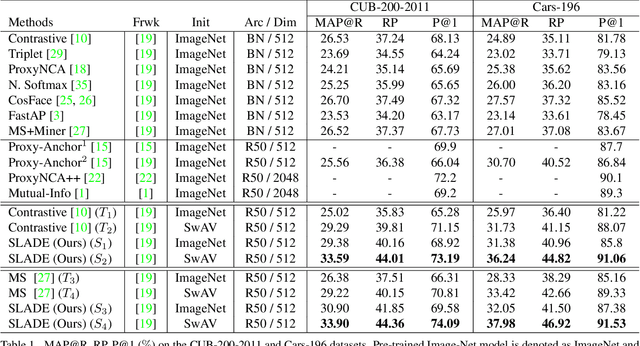
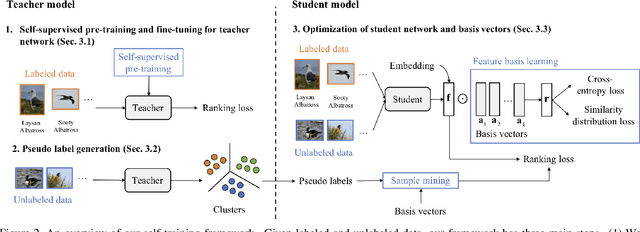
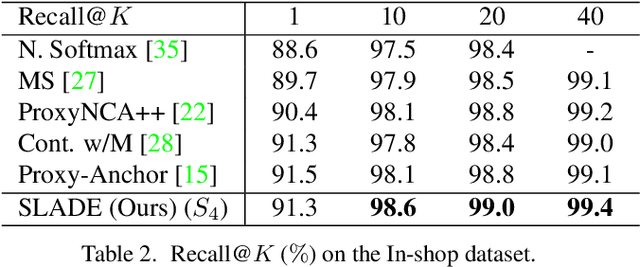
Most existing distance metric learning approaches use fully labeled data to learn the sample similarities in an embedding space. We present a self-training framework, SLADE, to improve retrieval performance by leveraging additional unlabeled data. We first train a teacher model on the labeled data and use it to generate pseudo labels for the unlabeled data. We then train a student model on both labels and pseudo labels to generate final feature embeddings. We use self-supervised representation learning to initialize the teacher model. To better deal with noisy pseudo labels generated by the teacher network, we design a new feature basis learning component for the student network, which learns basis functions of feature representations for unlabeled data. The learned basis vectors better measure the pairwise similarity and are used to select high-confident samples for training the student network. We evaluate our method on standard retrieval benchmarks: CUB-200, Cars-196 and In-shop. Experimental results demonstrate that our approach significantly improves the performance over the state-of-the-art methods.
An Interpretable Generative Model for Handwritten Digit Image Synthesis
Nov 11, 2018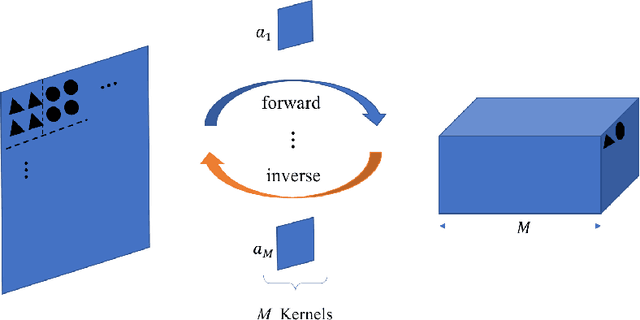
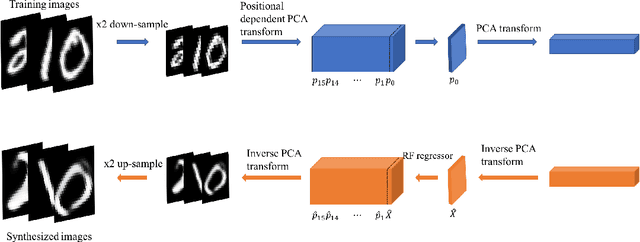
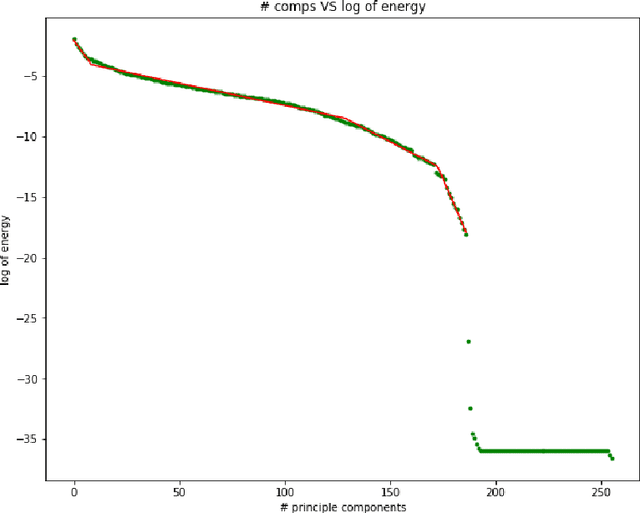
An interpretable generative model for handwritten digits synthesis is proposed in this work. Modern image generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), are trained by backpropagation (BP). The training process is complex and the underlying mechanism is difficult to explain. We propose an interpretable multi-stage PCA method to achieve the same goal and use handwritten digit images synthesis as an illustrative example. First, we derive principal-component-analysis-based (PCA-based) transform kernels at each stage based on the covariance of its inputs. This results in a sequence of transforms that convert input images of correlated pixels to spectral vectors of uncorrelated components. In other words, it is a whitening process. Then, we can synthesize an image based on random vectors and multi-stage transform kernels through a coloring process. The generative model is a feedforward (FF) design since no BP is used in model parameter determination. Its design complexity is significantly lower, and the whole design process is explainable. Finally, we design an FF generative model using the MNIST dataset, compare synthesis results with those obtained by state-of-the-art GAN and VAE methods, and show that the proposed generative model achieves comparable performance.