 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixQuant: Pushing the Limits of Block Rotations in Post-Training Quantization
Jan 29, 2026Recent post-training quantization (PTQ) methods have adopted block rotations to diffuse outliers prior to rounding. While this reduces the overhead of full-vector rotations, the effect of block structure on outlier suppression remains poorly understood. To fill this gap, we present the first systematic, non-asymptotic analysis of outlier suppression for block Hadamard rotations. Our analysis reveals that outlier suppression is fundamentally limited by the geometry of the input vector. In particular, post-rotation outliers are deterministically minimized when the pre-rotation $\ell_1$ norm mass is evenly distributed across blocks. Guided by these insights, we introduce MixQuant, a block rotation-aware PTQ framework that redistributes activation mass via permutations prior to rotation. We propose a greedy mass diffusion algorithm to calibrate permutations by equalizing the expected blockwise $\ell_1$ norms. To avoid adding inference overhead, we identify permutation-equivariant regions in transformer architectures to merge the resulting permutations into model weights before deployment. Experiments show that MixQuant consistently improves accuracy across all block sizes, recovering up to 90% of the full-vector rotation perplexity when quantizing Llama3 1B to INT4 with block size 16, compared to 46% without permutations.
A2Q+: Improving Accumulator-Aware Weight Quantization
Jan 19, 2024Quantization techniques commonly reduce the inference costs of neural networks by restricting the precision of weights and activations. Recent studies show that also reducing the precision of the accumulator can further improve hardware efficiency at the risk of numerical overflow, which introduces arithmetic errors that can degrade model accuracy. To avoid numerical overflow while maintaining accuracy, recent work proposed accumulator-aware quantization (A2Q), a quantization-aware training method that constrains model weights during training to safely use a target accumulator bit width during inference. Although this shows promise, we demonstrate that A2Q relies on an overly restrictive constraint and a sub-optimal weight initialization strategy that each introduce superfluous quantization error. To address these shortcomings, we introduce: (1) an improved bound that alleviates accumulator constraints without compromising overflow avoidance; and (2) a new strategy for initializing quantized weights from pre-trained floating-point checkpoints. We combine these contributions with weight normalization to introduce A2Q+. We support our analysis with experiments that show A2Q+ significantly improves the trade-off between accumulator bit width and model accuracy and characterize new trade-offs that arise as a consequence of accumulator constraints.
Open-source FPGA-ML codesign for the MLPerf Tiny Benchmark
Jun 23, 2022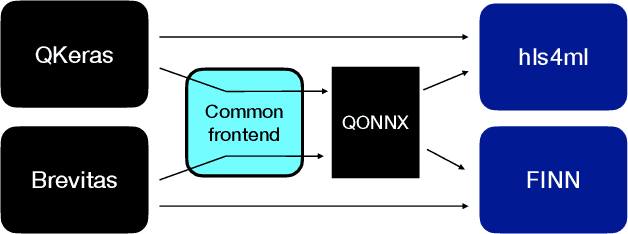
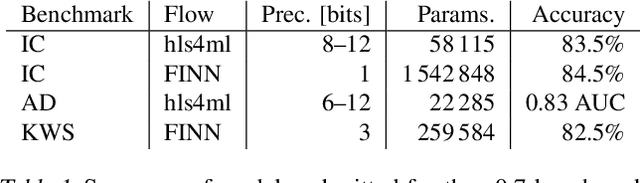
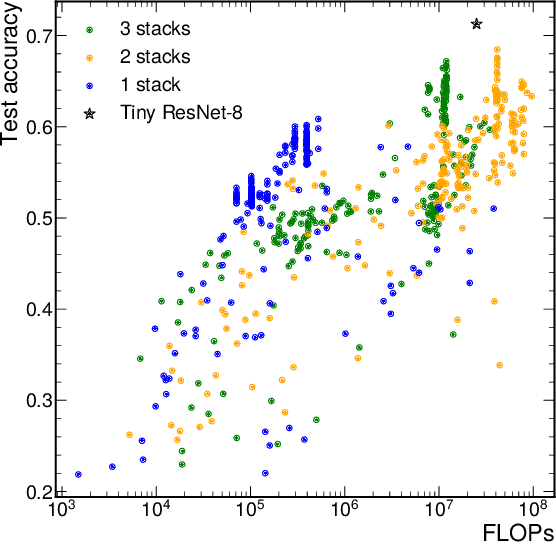
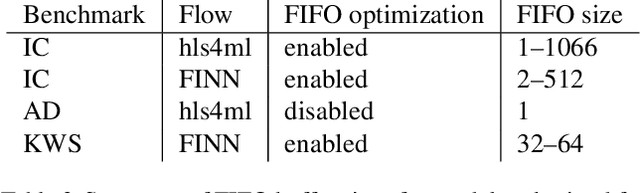
We present our development experience and recent results for the MLPerf Tiny Inference Benchmark on field-programmable gate array (FPGA) platforms. We use the open-source hls4ml and FINN workflows, which aim to democratize AI-hardware codesign of optimized neural networks on FPGAs. We present the design and implementation process for the keyword spotting, anomaly detection, and image classification benchmark tasks. The resulting hardware implementations are quantized, configurable, spatial dataflow architectures tailored for speed and efficiency and introduce new generic optimizations and common workflows developed as a part of this work. The full workflow is presented from quantization-aware training to FPGA implementation. The solutions are deployed on system-on-chip (Pynq-Z2) and pure FPGA (Arty A7-100T) platforms. The resulting submissions achieve latencies as low as 20 $\mu$s and energy consumption as low as 30 $\mu$J per inference. We demonstrate how emerging ML benchmarks on heterogeneous hardware platforms can catalyze collaboration and the development of new techniques and more accessible tools.
QONNX: Representing Arbitrary-Precision Quantized Neural Networks
Jun 17, 2022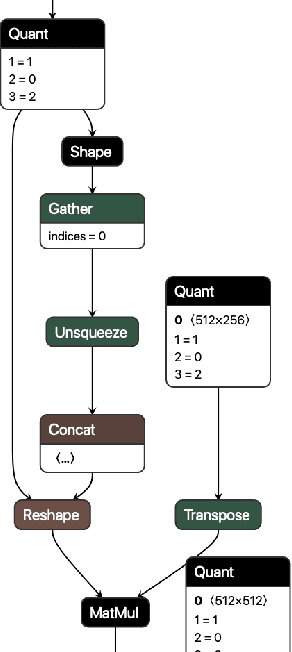
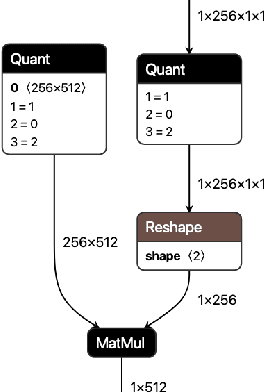
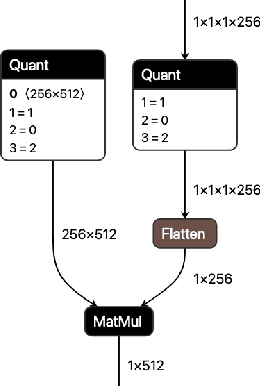
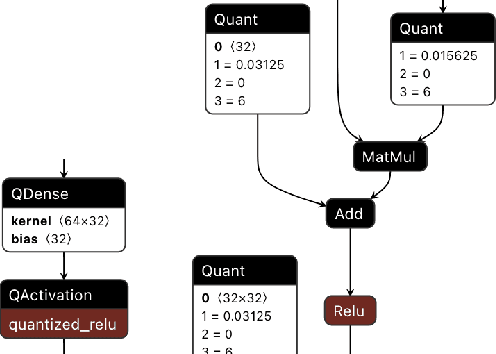
We present extensions to the Open Neural Network Exchange (ONNX) intermediate representation format to represent arbitrary-precision quantized neural networks. We first introduce support for low precision quantization in existing ONNX-based quantization formats by leveraging integer clipping, resulting in two new backward-compatible variants: the quantized operator format with clipping and quantize-clip-dequantize (QCDQ) format. We then introduce a novel higher-level ONNX format called quantized ONNX (QONNX) that introduces three new operators -- Quant, BipolarQuant, and Trunc -- in order to represent uniform quantization. By keeping the QONNX IR high-level and flexible, we enable targeting a wider variety of platforms. We also present utilities for working with QONNX, as well as examples of its usage in the FINN and hls4ml toolchains. Finally, we introduce the QONNX model zoo to share low-precision quantized neural networks.
EcoFlow: Efficient Convolutional Dataflows for Low-Power Neural Network Accelerators
Feb 04, 2022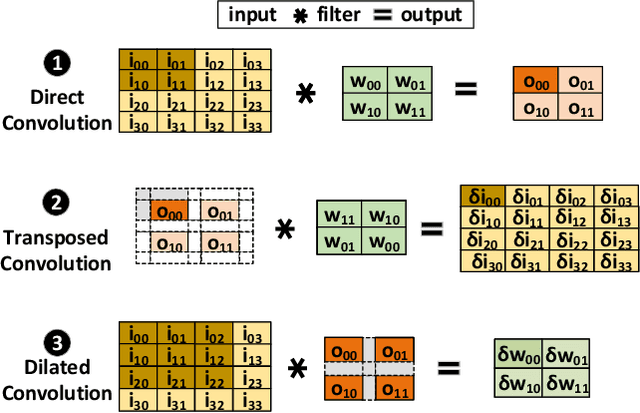

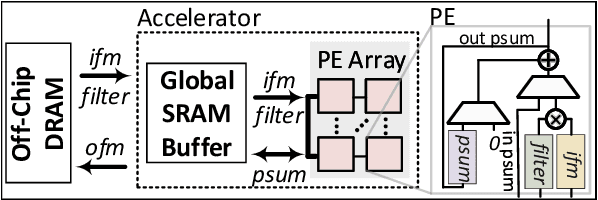
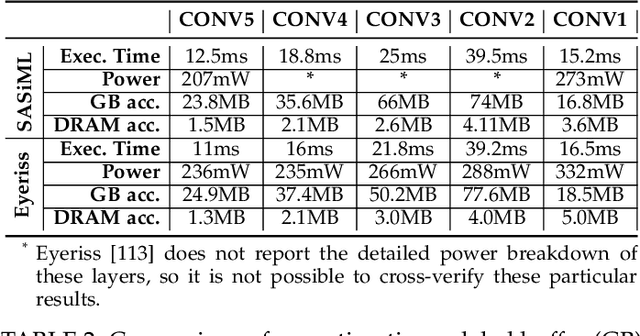
Dilated and transposed convolutions are widely used in modern convolutional neural networks (CNNs). These kernels are used extensively during CNN training and inference of applications such as image segmentation and high-resolution image generation. Although these kernels have grown in popularity, they stress current compute systems due to their high memory intensity, exascale compute demands, and large energy consumption. We find that commonly-used low-power CNN inference accelerators based on spatial architectures are not optimized for both of these convolutional kernels. Dilated and transposed convolutions introduce significant zero padding when mapped to the underlying spatial architecture, significantly degrading performance and energy efficiency. Existing approaches that address this issue require significant design changes to the otherwise simple, efficient, and well-adopted architectures used to compute direct convolutions. To address this challenge, we propose EcoFlow, a new set of dataflows and mapping algorithms for dilated and transposed convolutions. These algorithms are tailored to execute efficiently on existing low-cost, small-scale spatial architectures and requires minimal changes to the network-on-chip of existing accelerators. EcoFlow eliminates zero padding through careful dataflow orchestration and data mapping tailored to the spatial architecture. EcoFlow enables flexible and high-performance transpose and dilated convolutions on architectures that are otherwise optimized for CNN inference. We evaluate the efficiency of EcoFlow on CNN training workloads and Generative Adversarial Network (GAN) training workloads. Experiments in our new cycle-accurate simulator show that EcoFlow 1) reduces end-to-end CNN training time between 7-85%, and 2) improves end-to-end GAN training performance between 29-42%, compared to state-of-the-art CNN inference accelerators.
Ps and Qs: Quantization-aware pruning for efficient low latency neural network inference
Feb 22, 2021

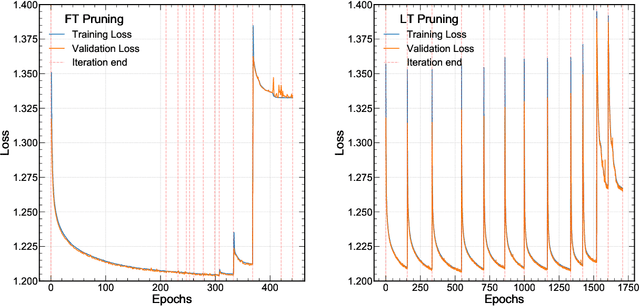
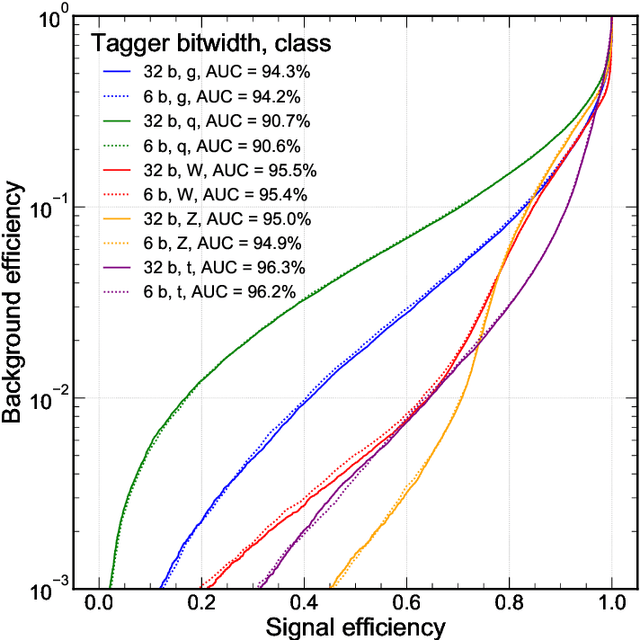
Efficient machine learning implementations optimized for inference in hardware have wide-ranging benefits depending on the application from lower inference latencies to higher data throughputs to more efficient energy consumption. Two popular techniques for reducing computation in neural networks are pruning, removing insignificant synapses, and quantization, reducing the precision of the calculations. In this work, we explore the interplay between pruning and quantization during the training of neural networks for ultra low latency applications targeting high energy physics use cases. However, techniques developed for this study have potential application across many other domains. We study various configurations of pruning during quantization-aware training, which we term \emph{quantization-aware pruning} and the effect of techniques like regularization, batch normalization, and different pruning schemes on multiple computational or neural efficiency metrics. We find that quantization-aware pruning yields more computationally efficient models than either pruning or quantization alone for our task. Further, quantization-aware pruning typically performs similar to or better in terms of computational efficiency compared to standard neural architecture optimization techniques. While the accuracy for the benchmark application may be similar, the information content of the network can vary significantly based on the training configuration.
LogicNets: Co-Designed Neural Networks and Circuits for Extreme-Throughput Applications
Apr 06, 2020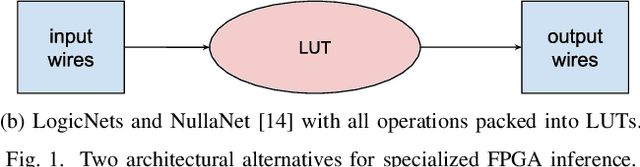
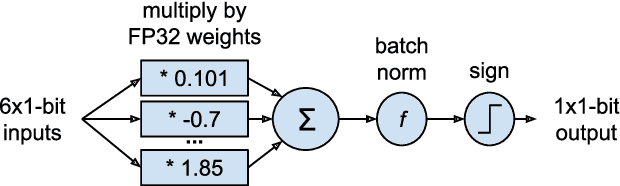
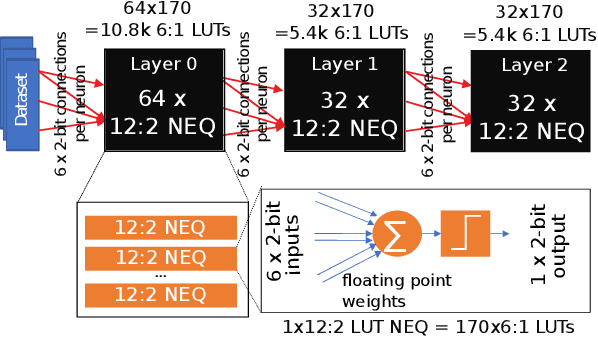
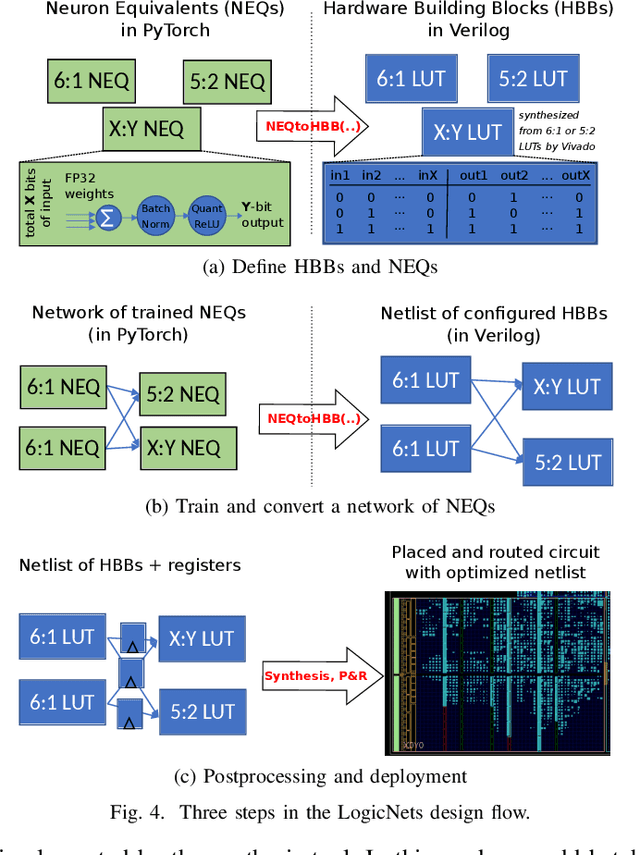
Deployment of deep neural networks for applications that require very high throughput or extremely low latency is a severe computational challenge, further exacerbated by inefficiencies in mapping the computation to hardware. We present a novel method for designing neural network topologies that directly map to a highly efficient FPGA implementation. By exploiting the equivalence of artificial neurons with quantized inputs/outputs and truth tables, we can train quantized neural networks that can be directly converted to a netlist of truth tables, and subsequently deployed as a highly pipelinable, massively parallel FPGA circuit. However, the neural network topology requires careful consideration since the hardware cost of truth tables grows exponentially with neuron fan-in. To obtain smaller networks where the whole netlist can be placed-and-routed onto a single FPGA, we derive a fan-in driven hardware cost model to guide topology design, and combine high sparsity with low-bit activation quantization to limit the neuron fan-in. We evaluate our approach on two tasks with very high intrinsic throughput requirements in high-energy physics and network intrusion detection. We show that the combination of sparsity and low-bit activation quantization results in high-speed circuits with small logic depth and low LUT cost, demonstrating competitive accuracy with less than 15 ns of inference latency and throughput in the hundreds of millions of inferences per second.
Scaling Neural Network Performance through Customized Hardware Architectures on Reconfigurable Logic
Jun 26, 2018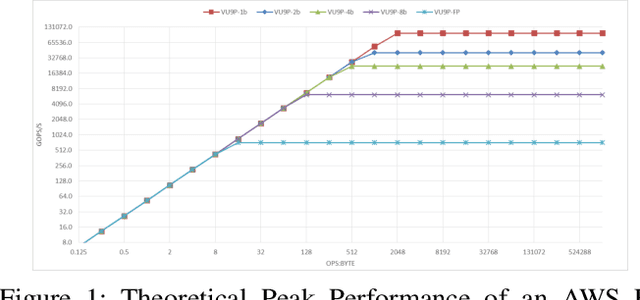
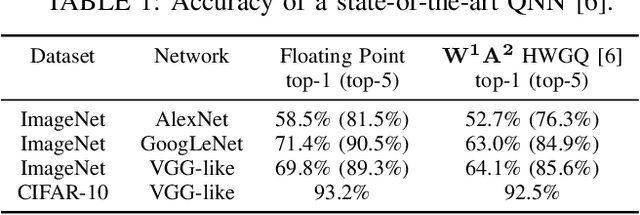
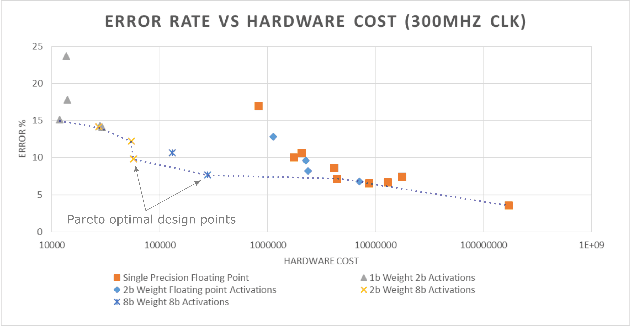

Convolutional Neural Networks have dramatically improved in recent years, surpassing human accuracy on certain problems and performance exceeding that of traditional computer vision algorithms. While the compute pattern in itself is relatively simple, significant compute and memory challenges remain as CNNs may contain millions of floating-point parameters and require billions of floating-point operations to process a single image. These computational requirements, combined with storage footprints that exceed typical cache sizes, pose a significant performance and power challenge for modern compute architectures. One of the promising opportunities to scale performance and power efficiency is leveraging reduced precision representations for all activations and weights as this allows to scale compute capabilities, reduce weight and feature map buffering requirements as well as energy consumption. While a small reduction in accuracy is encountered, these Quantized Neural Networks have been shown to achieve state-of-the-art accuracy on standard benchmark datasets, such as MNIST, CIFAR-10, SVHN and even ImageNet, and thus provide highly attractive design trade-offs. Current research has focused mainly on the implementation of extreme variants with full binarization of weights and or activations, as well typically smaller input images. Within this paper, we investigate the scalability of dataflow architectures with respect to supporting various precisions for both weights and activations, larger image dimensions, and increasing numbers of feature map channels. Key contributions are a formalized approach to understanding the scalability of the existing hardware architecture with cost models and a performance prediction as a function of the target device size. We provide validating experimental results for an ImageNet classification on a server-class platform, namely the AWS F1 node.
Streamlined Deployment for Quantized Neural Networks
May 30, 2018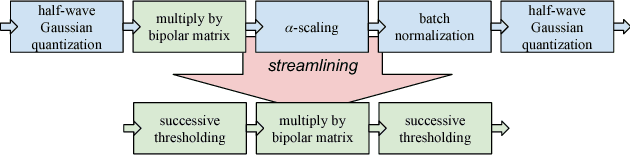
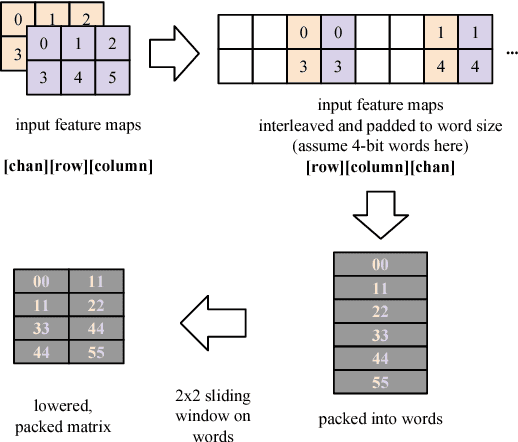
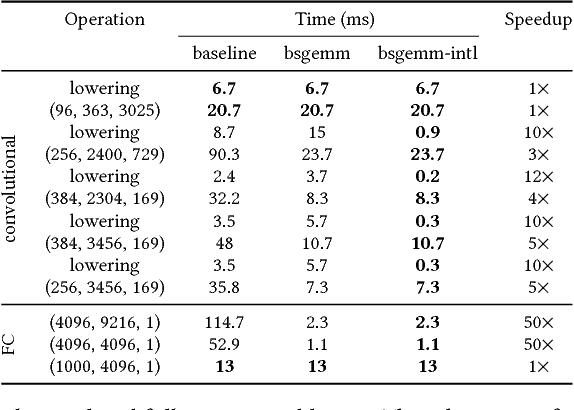
Running Deep Neural Network (DNN) models on devices with limited computational capability is a challenge due to large compute and memory requirements. Quantized Neural Networks (QNNs) have emerged as a potential solution to this problem, promising to offer most of the DNN accuracy benefits with much lower computational cost. However, harvesting these benefits on existing mobile CPUs is a challenge since operations on highly quantized datatypes are not natively supported in most instruction set architectures (ISAs). In this work, we first describe a streamlining flow to convert all QNN inference operations to integer ones. Afterwards, we provide techniques based on processing one bit position at a time (bit-serial) to show how QNNs can be efficiently deployed using common bitwise operations. We demonstrate the potential of QNNs on mobile CPUs with microbenchmarks and on a quantized AlexNet, which is 3.5x faster than an optimized 8-bit baseline. Our bit-serial matrix multiplication library is available on GitHub at https://git.io/vhshn
Scaling Binarized Neural Networks on Reconfigurable Logic
Jan 27, 2017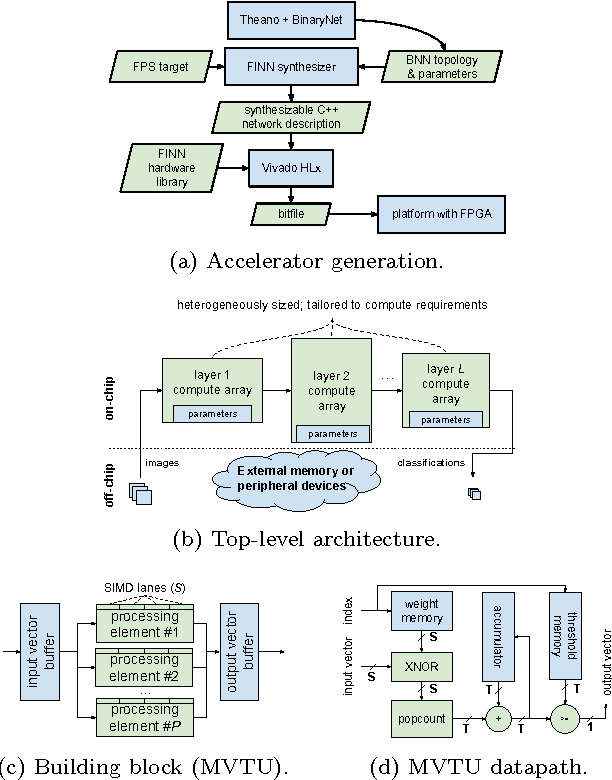

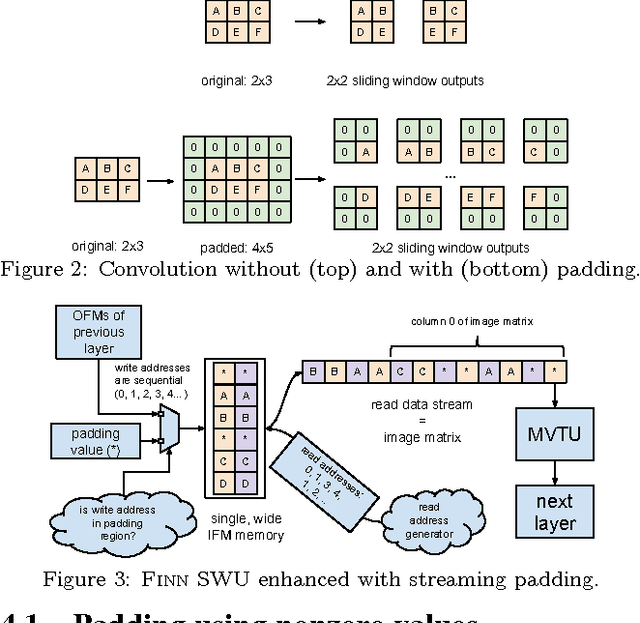
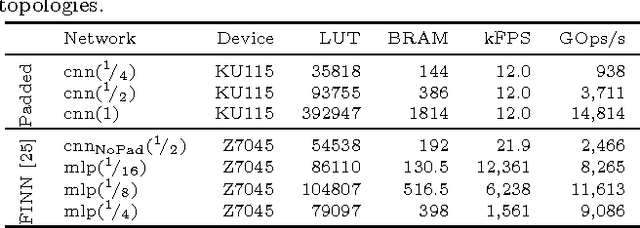
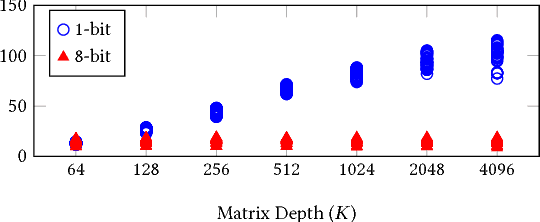
Binarized neural networks (BNNs) are gaining interest in the deep learning community due to their significantly lower computational and memory cost. They are particularly well suited to reconfigurable logic devices, which contain an abundance of fine-grained compute resources and can result in smaller, lower power implementations, or conversely in higher classification rates. Towards this end, the Finn framework was recently proposed for building fast and flexible field programmable gate array (FPGA) accelerators for BNNs. Finn utilized a novel set of optimizations that enable efficient mapping of BNNs to hardware and implemented fully connected, non-padded convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. However, FINN was not evaluated on larger topologies due to the size of the chosen FPGA, and exhibited decreased accuracy due to lack of padding. In this paper, we improve upon Finn to show how padding can be employed on BNNs while still maintaining a 1-bit datapath and high accuracy. Based on this technique, we demonstrate numerous experiments to illustrate flexibility and scalability of the approach. In particular, we show that a large BNN requiring 1.2 billion operations per frame running on an ADM-PCIE-8K5 platform can classify images at 12 kFPS with 671 us latency while drawing less than 41 W board power and classifying CIFAR-10 images at 88.7% accuracy. Our implementation of this network achieves 14.8 trillion operations per second. We believe this is the fastest classification rate reported to date on this benchmark at this level of accuracy.