 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoPO: On Mutual Information Maximization for Large Language Model Alignment
May 13, 2025We study the post-training of large language models (LLMs) with human preference data. Recently, direct preference optimization and its variants have shown considerable promise in aligning language models, eliminating the need for reward models and online sampling. Despite these benefits, these methods rely on explicit assumptions about the Bradley-Terry (BT) model, which makes them prone to overfitting and results in suboptimal performance, particularly on reasoning-heavy tasks. To address these challenges, we propose a principled preference fine-tuning algorithm called InfoPO, which effectively and efficiently aligns large language models using preference data. InfoPO eliminates the reliance on the BT model and prevents the likelihood of the chosen response from decreasing. Extensive experiments confirm that InfoPO consistently outperforms established baselines on widely used open benchmarks, particularly in reasoning tasks.
CoLLM: A Large Language Model for Composed Image Retrieval
Mar 25, 2025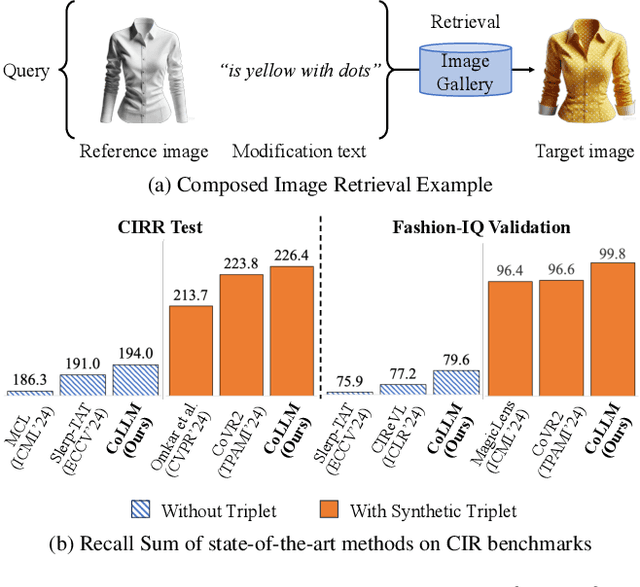
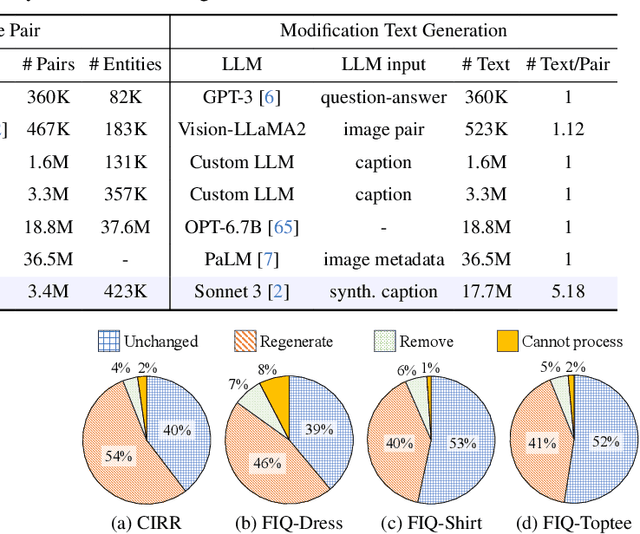
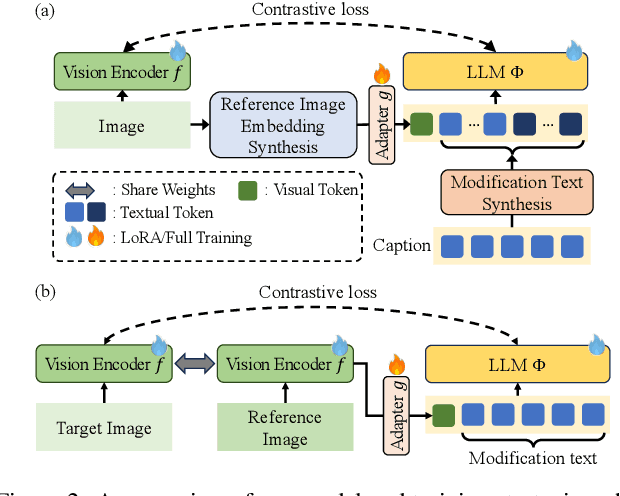
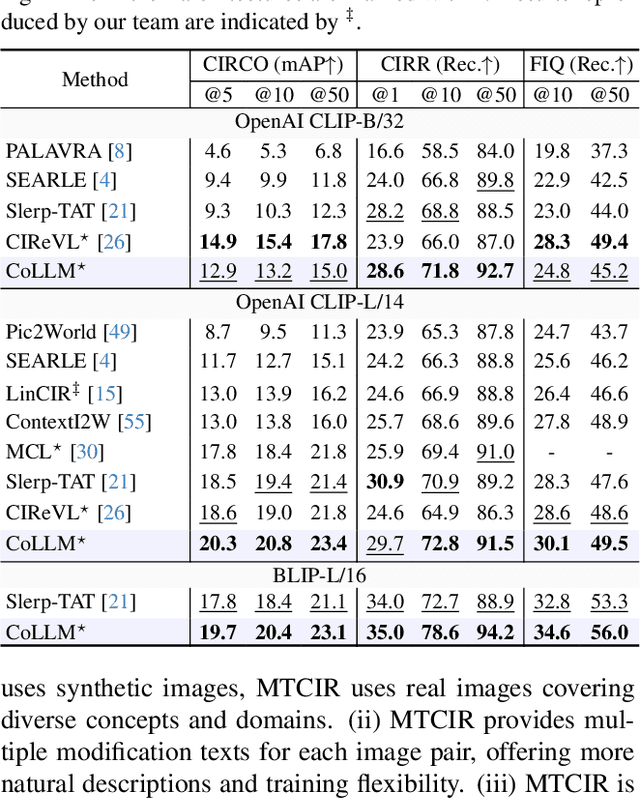
Composed Image Retrieval (CIR) is a complex task that aims to retrieve images based on a multimodal query. Typical training data consists of triplets containing a reference image, a textual description of desired modifications, and the target image, which are expensive and time-consuming to acquire. The scarcity of CIR datasets has led to zero-shot approaches utilizing synthetic triplets or leveraging vision-language models (VLMs) with ubiquitous web-crawled image-caption pairs. However, these methods have significant limitations: synthetic triplets suffer from limited scale, lack of diversity, and unnatural modification text, while image-caption pairs hinder joint embedding learning of the multimodal query due to the absence of triplet data. Moreover, existing approaches struggle with complex and nuanced modification texts that demand sophisticated fusion and understanding of vision and language modalities. We present CoLLM, a one-stop framework that effectively addresses these limitations. Our approach generates triplets on-the-fly from image-caption pairs, enabling supervised training without manual annotation. We leverage Large Language Models (LLMs) to generate joint embeddings of reference images and modification texts, facilitating deeper multimodal fusion. Additionally, we introduce Multi-Text CIR (MTCIR), a large-scale dataset comprising 3.4M samples, and refine existing CIR benchmarks (CIRR and Fashion-IQ) to enhance evaluation reliability. Experimental results demonstrate that CoLLM achieves state-of-the-art performance across multiple CIR benchmarks and settings. MTCIR yields competitive results, with up to 15% performance improvement. Our refined benchmarks provide more reliable evaluation metrics for CIR models, contributing to the advancement of this important field.
M-LLM Based Video Frame Selection for Efficient Video Understanding
Feb 27, 2025Recent advances in Multi-Modal Large Language Models (M-LLMs) show promising results in video reasoning. Popular Multi-Modal Large Language Model (M-LLM) frameworks usually apply naive uniform sampling to reduce the number of video frames that are fed into an M-LLM, particularly for long context videos. However, it could lose crucial context in certain periods of a video, so that the downstream M-LLM may not have sufficient visual information to answer a question. To attack this pain point, we propose a light-weight M-LLM -based frame selection method that adaptively select frames that are more relevant to users' queries. In order to train the proposed frame selector, we introduce two supervision signals (i) Spatial signal, where single frame importance score by prompting a M-LLM; (ii) Temporal signal, in which multiple frames selection by prompting Large Language Model (LLM) using the captions of all frame candidates. The selected frames are then digested by a frozen downstream video M-LLM for visual reasoning and question answering. Empirical results show that the proposed M-LLM video frame selector improves the performances various downstream video Large Language Model (video-LLM) across medium (ActivityNet, NExT-QA) and long (EgoSchema, LongVideoBench) context video question answering benchmarks.
DreamBlend: Advancing Personalized Fine-tuning of Text-to-Image Diffusion Models
Nov 28, 2024



Given a small number of images of a subject, personalized image generation techniques can fine-tune large pre-trained text-to-image diffusion models to generate images of the subject in novel contexts, conditioned on text prompts. In doing so, a trade-off is made between prompt fidelity, subject fidelity and diversity. As the pre-trained model is fine-tuned, earlier checkpoints synthesize images with low subject fidelity but high prompt fidelity and diversity. In contrast, later checkpoints generate images with low prompt fidelity and diversity but high subject fidelity. This inherent trade-off limits the prompt fidelity, subject fidelity and diversity of generated images. In this work, we propose DreamBlend to combine the prompt fidelity from earlier checkpoints and the subject fidelity from later checkpoints during inference. We perform a cross attention guided image synthesis from a later checkpoint, guided by an image generated by an earlier checkpoint, for the same prompt. This enables generation of images with better subject fidelity, prompt fidelity and diversity on challenging prompts, outperforming state-of-the-art fine-tuning methods.
Evolutionary Contrastive Distillation for Language Model Alignment
Oct 10, 2024



The ability of large language models (LLMs) to execute complex instructions is essential for their real-world applications. However, several recent studies indicate that LLMs struggle with challenging instructions. In this paper, we propose Evolutionary Contrastive Distillation (ECD), a novel method for generating high-quality synthetic preference data designed to enhance the complex instruction-following capability of language models. ECD generates data that specifically illustrates the difference between a response that successfully follows a set of complex instructions and a response that is high-quality, but nevertheless makes some subtle mistakes. This is done by prompting LLMs to progressively evolve simple instructions to more complex instructions. When the complexity of an instruction is increased, the original successful response to the original instruction becomes a "hard negative" response for the new instruction, mostly meeting requirements of the new instruction, but barely missing one or two. By pairing a good response with such a hard negative response, and employing contrastive learning algorithms such as DPO, we improve language models' ability to follow complex instructions. Empirically, we observe that our method yields a 7B model that exceeds the complex instruction-following performance of current SOTA 7B models and is competitive even with open-source 70B models.
X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
Jul 18, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have revolutionized the field of vision-language understanding by integrating visual perception capabilities into Large Language Models (LLMs). The prevailing trend in this field involves the utilization of a vision encoder derived from vision-language contrastive learning (CL), showing expertise in capturing overall representations while facing difficulties in capturing detailed local patterns. In this work, we focus on enhancing the visual representations for MLLMs by combining high-frequency and detailed visual representations, obtained through masked image modeling (MIM), with semantically-enriched low-frequency representations captured by CL. To achieve this goal, we introduce X-Former which is a lightweight transformer module designed to exploit the complementary strengths of CL and MIM through an innovative interaction mechanism. Specifically, X-Former first bootstraps vision-language representation learning and multimodal-to-multimodal generative learning from two frozen vision encoders, i.e., CLIP-ViT (CL-based) and MAE-ViT (MIM-based). It further bootstraps vision-to-language generative learning from a frozen LLM to ensure visual features from X-Former can be interpreted by the LLM. To demonstrate the effectiveness of our approach, we assess its performance on tasks demanding detailed visual understanding. Extensive evaluations indicate that X-Former excels in visual reasoning tasks involving both structural and semantic categories in the GQA dataset. Assessment on fine-grained visual perception benchmark further confirms its superior capabilities in visual understanding.
Open Vocabulary Multi-Label Video Classification
Jul 12, 2024



Pre-trained vision-language models (VLMs) have enabled significant progress in open vocabulary computer vision tasks such as image classification, object detection and image segmentation. Some recent works have focused on extending VLMs to open vocabulary single label action classification in videos. However, previous methods fall short in holistic video understanding which requires the ability to simultaneously recognize multiple actions and entities e.g., objects in the video in an open vocabulary setting. We formulate this problem as open vocabulary multilabel video classification and propose a method to adapt a pre-trained VLM such as CLIP to solve this task. We leverage large language models (LLMs) to provide semantic guidance to the VLM about class labels to improve its open vocabulary performance with two key contributions. First, we propose an end-to-end trainable architecture that learns to prompt an LLM to generate soft attributes for the CLIP text-encoder to enable it to recognize novel classes. Second, we integrate a temporal modeling module into CLIP's vision encoder to effectively model the spatio-temporal dynamics of video concepts as well as propose a novel regularized finetuning technique to ensure strong open vocabulary classification performance in the video domain. Our extensive experimentation showcases the efficacy of our approach on multiple benchmark datasets.
VidLA: Video-Language Alignment at Scale
Mar 21, 2024In this paper, we propose VidLA, an approach for video-language alignment at scale. There are two major limitations of previous video-language alignment approaches. First, they do not capture both short-range and long-range temporal dependencies and typically employ complex hierarchical deep network architectures that are hard to integrate with existing pretrained image-text foundation models. To effectively address this limitation, we instead keep the network architecture simple and use a set of data tokens that operate at different temporal resolutions in a hierarchical manner, accounting for the temporally hierarchical nature of videos. By employing a simple two-tower architecture, we are able to initialize our video-language model with pretrained image-text foundation models, thereby boosting the final performance. Second, existing video-language alignment works struggle due to the lack of semantically aligned large-scale training data. To overcome it, we leverage recent LLMs to curate the largest video-language dataset to date with better visual grounding. Furthermore, unlike existing video-text datasets which only contain short clips, our dataset is enriched with video clips of varying durations to aid our temporally hierarchical data tokens in extracting better representations at varying temporal scales. Overall, empirical results show that our proposed approach surpasses state-of-the-art methods on multiple retrieval benchmarks, especially on longer videos, and performs competitively on classification benchmarks.
Robust Multi-Task Learning with Excess Risks
Feb 14, 2024



Multi-task learning (MTL) considers learning a joint model for multiple tasks by optimizing a convex combination of all task losses. To solve the optimization problem, existing methods use an adaptive weight updating scheme, where task weights are dynamically adjusted based on their respective losses to prioritize difficult tasks. However, these algorithms face a great challenge whenever label noise is present, in which case excessive weights tend to be assigned to noisy tasks that have relatively large Bayes optimal errors, thereby overshadowing other tasks and causing performance to drop across the board. To overcome this limitation, we propose Multi-Task Learning with Excess Risks (ExcessMTL), an excess risk-based task balancing method that updates the task weights by their distances to convergence instead. Intuitively, ExcessMTL assigns higher weights to worse-trained tasks that are further from convergence. To estimate the excess risks, we develop an efficient and accurate method with Taylor approximation. Theoretically, we show that our proposed algorithm achieves convergence guarantees and Pareto stationarity. Empirically, we evaluate our algorithm on various MTL benchmarks and demonstrate its superior performance over existing methods in the presence of label noise.
Graph-Aware Language Model Pre-Training on a Large Graph Corpus Can Help Multiple Graph Applications
Jun 05, 2023



Model pre-training on large text corpora has been demonstrated effective for various downstream applications in the NLP domain. In the graph mining domain, a similar analogy can be drawn for pre-training graph models on large graphs in the hope of benefiting downstream graph applications, which has also been explored by several recent studies. However, no existing study has ever investigated the pre-training of text plus graph models on large heterogeneous graphs with abundant textual information (a.k.a. large graph corpora) and then fine-tuning the model on different related downstream applications with different graph schemas. To address this problem, we propose a framework of graph-aware language model pre-training (GALM) on a large graph corpus, which incorporates large language models and graph neural networks, and a variety of fine-tuning methods on downstream applications. We conduct extensive experiments on Amazon's real internal datasets and large public datasets. Comprehensive empirical results and in-depth analysis demonstrate the effectiveness of our proposed methods along with lessons learned.