 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structure-consistent Restoration Network for Cataract Fundus Image Enhancement
Jun 09, 2022
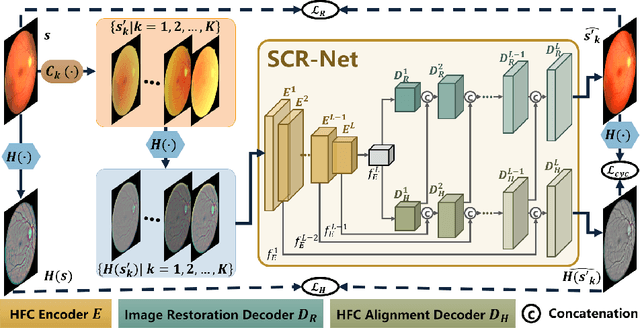
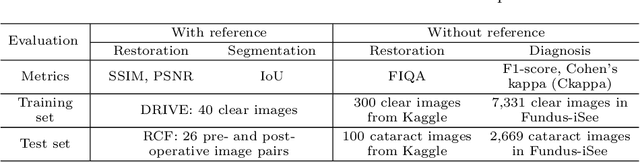
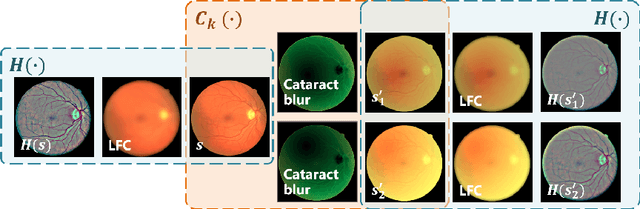
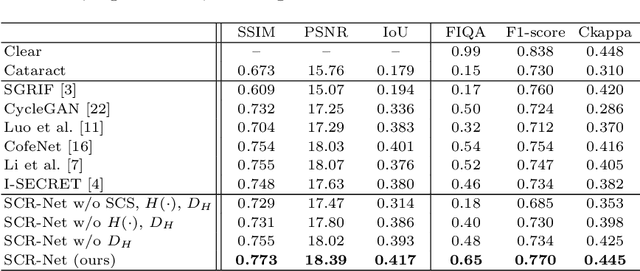
Fundus photography is a routine examination in clinics to diagnose and monitor ocular diseases. However, for cataract patients, the fundus image always suffers quality degradation caused by the clouding lens. The degradation prevents reliable diagnosis by ophthalmologists or computer-aided systems. To improve the certainty in clinical diagnosis, restoration algorithms have been proposed to enhance the quality of fundus images. Unfortunately, challenges remain in the deployment of these algorithms, such as collecting sufficient training data and preserving retinal structures. In this paper, to circumvent the strict deployment requirement, a structure-consistent restoration network (SCR-Net) for cataract fundus images is developed from synthesized data that shares an identical structure. A cataract simulation model is firstly designed to collect synthesized cataract sets (SCS) formed by cataract fundus images sharing identical structures. Then high-frequency components (HFCs) are extracted from the SCS to constrain structure consistency such that the structure preservation in SCR-Net is enforced. The experiments demonstrate the effectiveness of SCR-Net in the comparison with state-of-the-art methods and the follow-up clinical applications. The code is available at https://github.com/liamheng/ArcNet-Medical-Image-Enhancement.
Affinity Feature Strengthening for Accurate, Complete and Robust Vessel Segmentation
Nov 12, 2022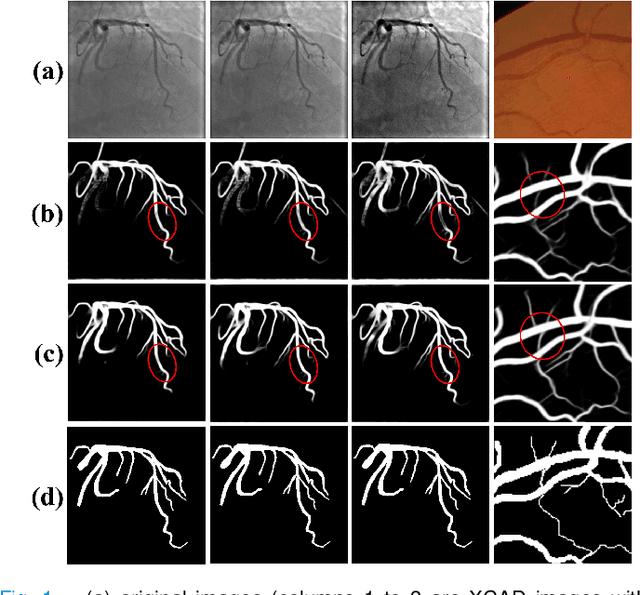
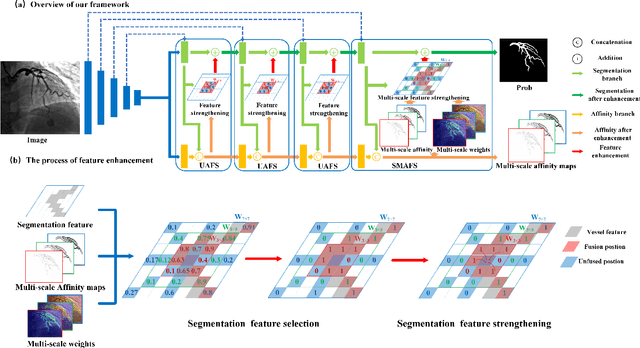
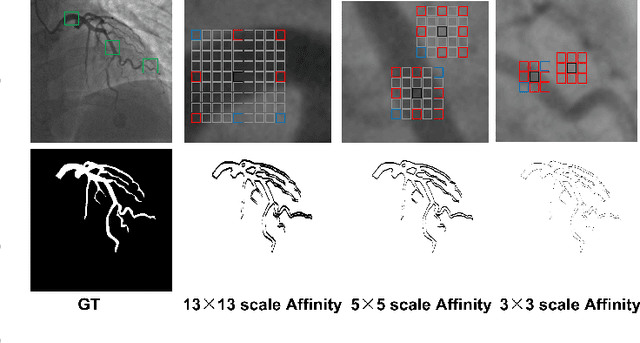
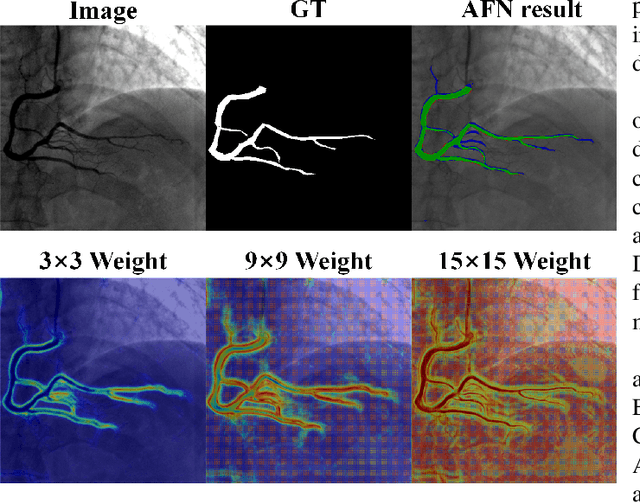
Vessel segmentation is essential in many medical image applications, such as the detection of coronary stenoses, retinal vessel diseases and brain aneurysms. A high pixel-wise accuracy, complete topology structure and robustness to various contrast variations are three critical aspects of vessel segmentation. However, most existing methods only focus on achieving part of them via dedicated designs while few of them can concurrently achieve the three goals. In this paper, we present a novel affinity feature strengthening network (AFN) which adopts a contrast-insensitive approach based on multiscale affinity to jointly model topology and refine pixel-wise segmentation features. Specifically, for each pixel we derive a multiscale affinity field which captures the semantic relationships of the pixel with its neighbors on the predicted mask image. Such a multiscale affinity field can effectively represent the local topology of a vessel segment of different sizes. Meanwhile, it does not depend on image intensities and hence is robust to various illumination and contrast changes. We further learn spatial- and scale-aware adaptive weights for the corresponding affinity fields to strengthen vessel features. We evaluate our AFN on four different types of vascular datasets: X-ray angiography coronary vessel dataset (XCAD), portal vein dataset (PV), digital subtraction angiography cerebrovascular vessel dataset (DSA) and retinal vessel dataset (DRIVE). Extensive experimental results on the four datasets demonstrate that our AFN outperforms the state-of-the-art methods in terms of both higher accuracy and topological metrics, and meanwhile is more robust to various contrast changes than existing methods. Codes will be made public.
A Style-aware Discriminator for Controllable Image Translation
Mar 29, 2022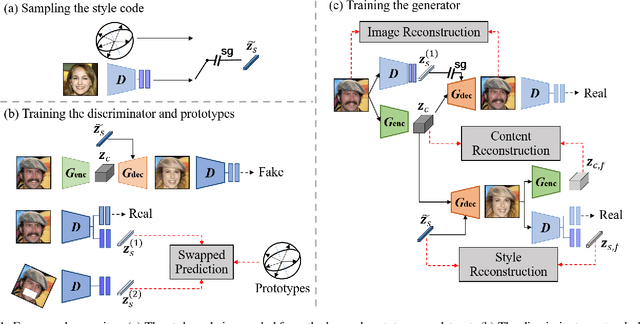
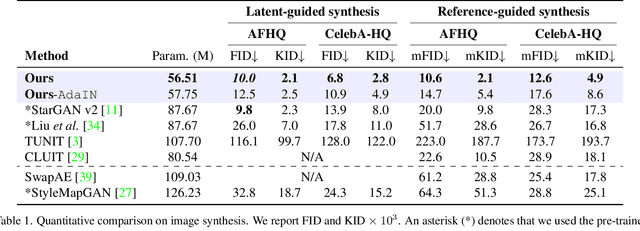

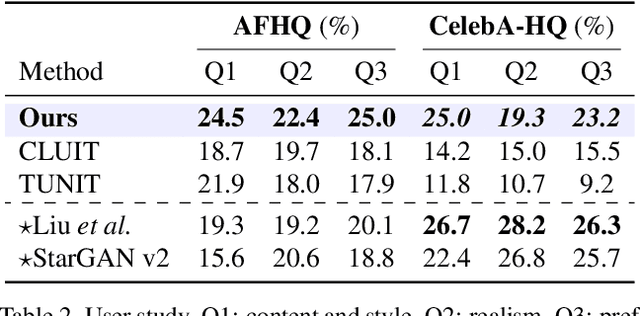
Current image-to-image translations do not control the output domain beyond the classes used during training, nor do they interpolate between different domains well, leading to implausible results. This limitation largely arises because labels do not consider the semantic distance. To mitigate such problems, we propose a style-aware discriminator that acts as a critic as well as a style encoder to provide conditions. The style-aware discriminator learns a controllable style space using prototype-based self-supervised learning and simultaneously guides the generator. Experiments on multiple datasets verify that the proposed model outperforms current state-of-the-art image-to-image translation methods. In contrast with current methods, the proposed approach supports various applications, including style interpolation, content transplantation, and local image translation.
Reducing Randomness of Non-Regular Sampling Masks for Image Reconstruction
Apr 07, 2022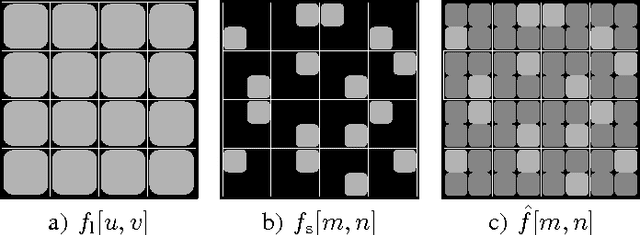
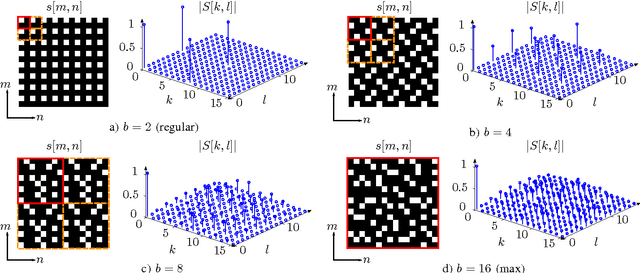
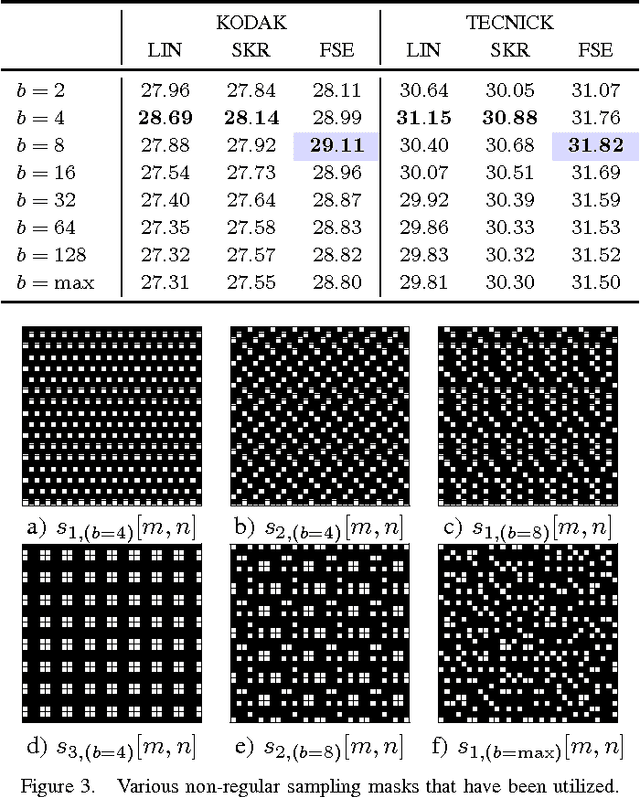

Increasing spatial image resolution is an often required, yet challenging task in image acquisition. Recently, it has been shown that it is possible to obtain a high resolution image by covering a low resolution sensor with a non-regular sampling mask. Due to the masking, however, some pixel information in the resulting high resolution image is not available and has to be reconstructed by an efficient image reconstruction algorithm in order to get a fully reconstructed high resolution image. In this paper, the influence of different sampling masks with a reduced randomness of the non-regularity on the image reconstruction process is evaluated. Simulation results show that it is sufficient to use sampling masks that are non-regular only on a smaller scale. These sampling masks lead to a visually noticeable gain in PSNR compared to arbitrary chosen sampling masks which are non-regular over the whole image sensor size. At the same time, they simplify the manufacturing process and allow for efficient storage.
Application of the YOLOv5 Model for the Detection of Microobjects in the Marine Environment
Nov 28, 2022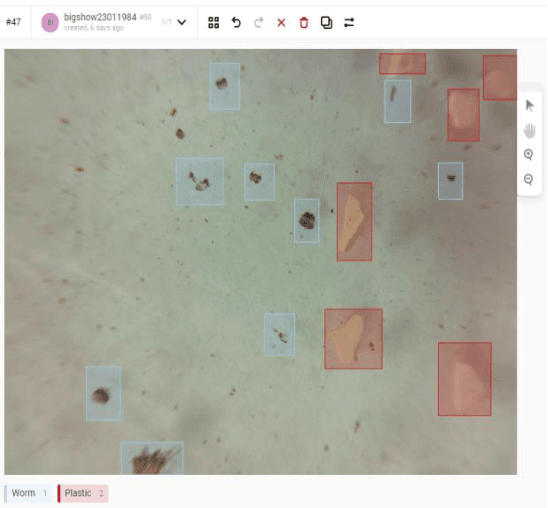

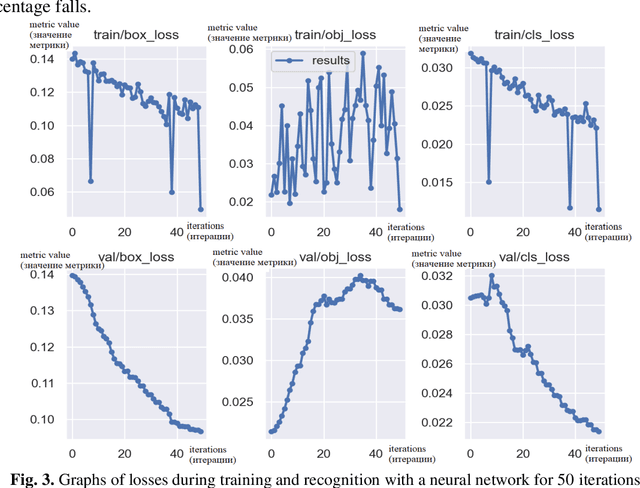
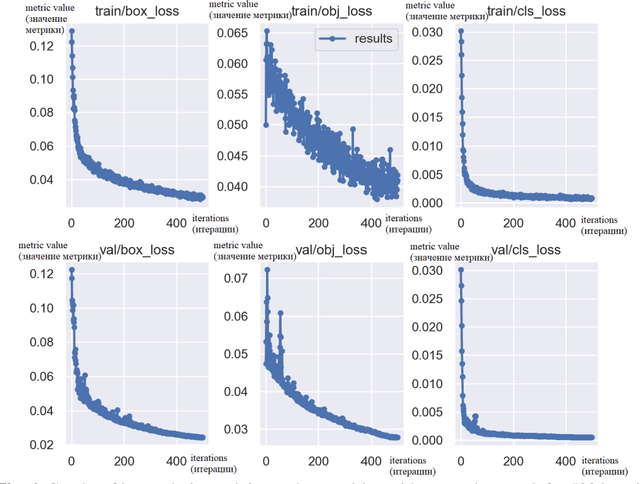
The efficiency of using the YOLOV5 machine learning model for solving the problem of automatic de-tection and recognition of micro-objects in the marine environment is studied. Samples of microplankton and microplastics were prepared, according to which a database of classified images was collected for training an image recognition neural network. The results of experiments using a trained network to find micro-objects in photo and video images in real time are presented. Experimental studies have shown high efficiency, comparable to manual recognition, of the proposed model in solving problems of detect-ing micro-objects in the marine environment.
PLIKS: A Pseudo-Linear Inverse Kinematic Solver for 3D Human Body Estimation
Nov 21, 2022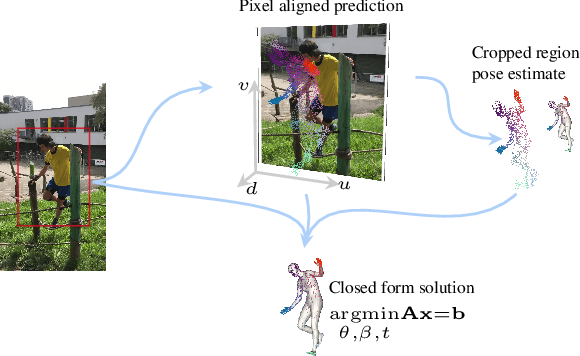
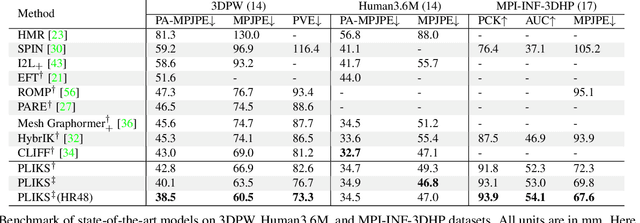
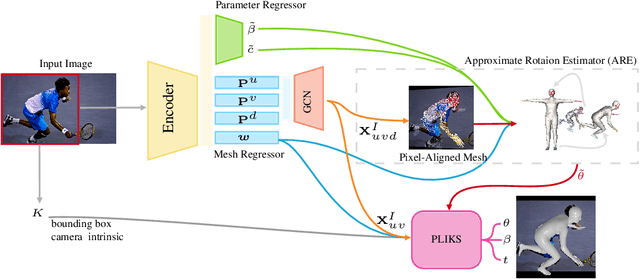

We consider the problem of reconstructing a 3D mesh of the human body from a single 2D image as a model-in-the-loop optimization problem. Existing approaches often regress the shape, pose, and translation parameters of a parametric statistical model assuming a weak-perspective camera. In contrast, we first estimate 2D pixel-aligned vertices in image space and propose PLIKS (Pseudo-Linear Inverse Kinematic Solver) to regress the model parameters by minimizing a linear least squares problem. PLIKS is a linearized formulation of the parametric SMPL model, which provides an optimal pose and shape solution from an adequate initialization. Our method is based on analytically calculating an initial pose estimate from the network predicted 3D mesh followed by PLIKS to obtain an optimal solution for the given constraints. As our framework makes use of 2D pixel-aligned maps, it is inherently robust to partial occlusion. To demonstrate the performance of the proposed approach, we present quantitative evaluations which confirm that PLIKS achieves more accurate reconstruction with greater than 10% improvement compared to other state-of-the-art methods with respect to the standard 3D human pose and shape benchmarks while also obtaining a reconstruction error improvement of 12.9 mm on the newer AGORA dataset.
Cross-Modal Contrastive Learning for Robust Reasoning in VQA
Nov 21, 2022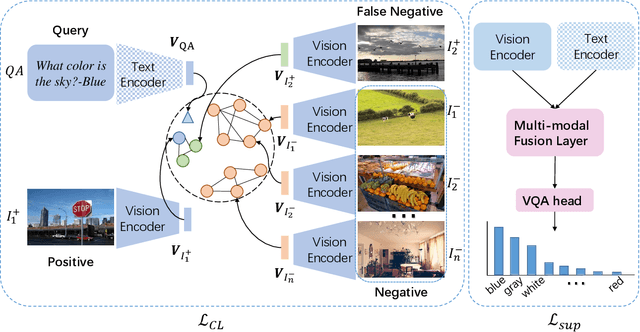

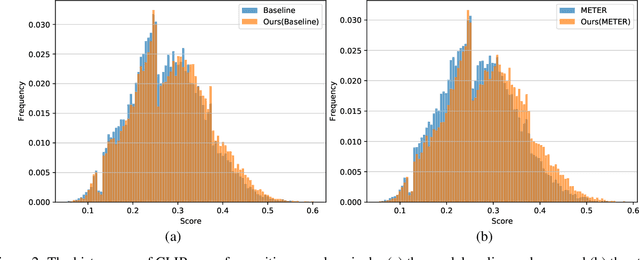
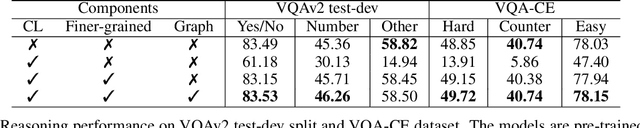
Multi-modal reasoning in visual question answering (VQA) has witnessed rapid progress recently. However, most reasoning models heavily rely on shortcuts learned from training data, which prevents their usage in challenging real-world scenarios. In this paper, we propose a simple but effective cross-modal contrastive learning strategy to get rid of the shortcut reasoning caused by imbalanced annotations and improve the overall performance. Different from existing contrastive learning with complex negative categories on coarse (Image, Question, Answer) triplet level, we leverage the correspondences between the language and image modalities to perform finer-grained cross-modal contrastive learning. We treat each Question-Answer (QA) pair as a whole, and differentiate between images that conform with it and those against it. To alleviate the issue of sampling bias, we further build connected graphs among images. For each positive pair, we regard the images from different graphs as negative samples and deduct the version of multi-positive contrastive learning. To our best knowledge, it is the first paper that reveals a general contrastive learning strategy without delicate hand-craft rules can contribute to robust VQA reasoning. Experiments on several mainstream VQA datasets demonstrate our superiority compared to the state of the arts. Code is available at \url{https://github.com/qizhust/cmcl_vqa_pl}.
Style-Hallucinated Dual Consistency Learning: A Unified Framework for Visual Domain Generalization
Dec 18, 2022
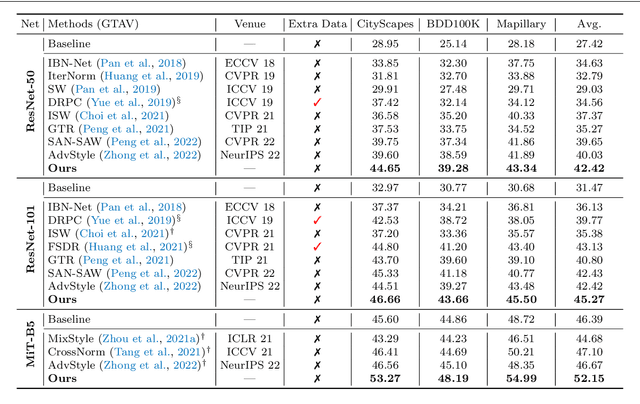
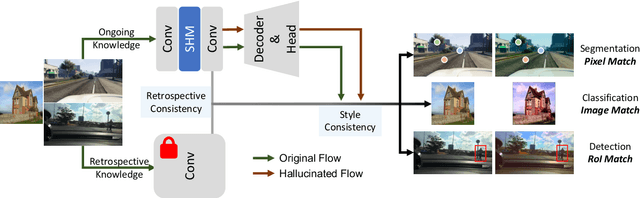
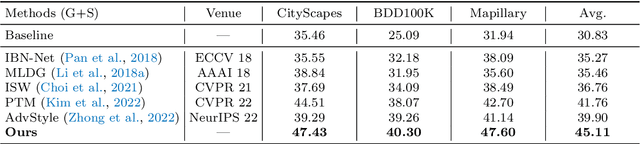
Domain shift widely exists in the visual world, while modern deep neural networks commonly suffer from severe performance degradation under domain shift due to the poor generalization ability, which limits the real-world applications. The domain shift mainly lies in the limited source environmental variations and the large distribution gap between source and unseen target data. To this end, we propose a unified framework, Style-HAllucinated Dual consistEncy learning (SHADE), to handle such domain shift in various visual tasks. Specifically, SHADE is constructed based on two consistency constraints, Style Consistency (SC) and Retrospection Consistency (RC). SC enriches the source situations and encourages the model to learn consistent representation across style-diversified samples. RC leverages general visual knowledge to prevent the model from overfitting to source data and thus largely keeps the representation consistent between the source and general visual models. Furthermore, we present a novel style hallucination module (SHM) to generate style-diversified samples that are essential to consistency learning. SHM selects basis styles from the source distribution, enabling the model to dynamically generate diverse and realistic samples during training. Extensive experiments demonstrate that our versatile SHADE can significantly enhance the generalization in various visual recognition tasks, including image classification, semantic segmentation and object detection, with different models, i.e., ConvNets and Transformer.
Pixel is All You Need: Adversarial Trajectory-Ensemble Active Learning for Salient Object Detection
Dec 13, 2022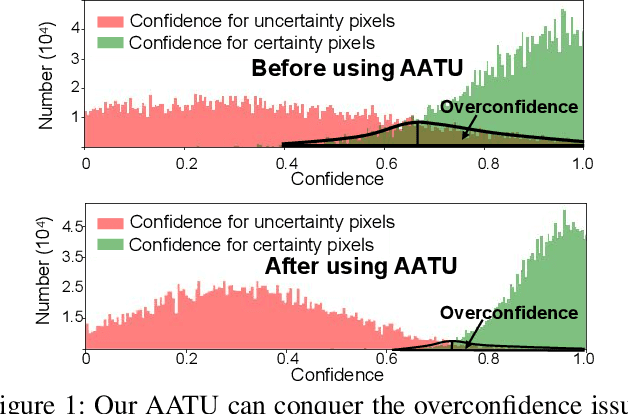
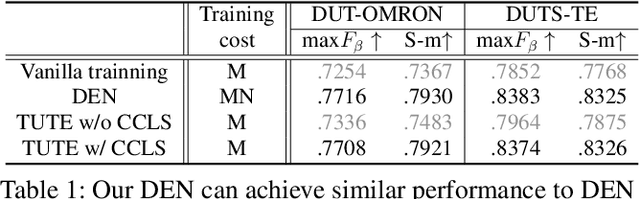
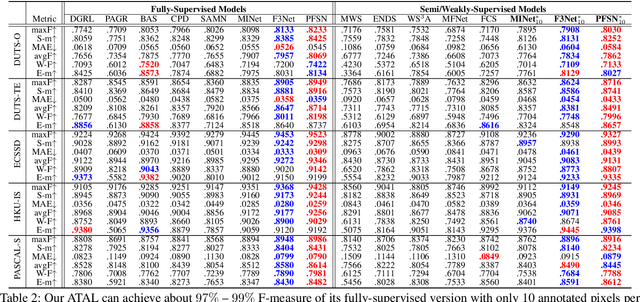
Although weakly-supervised techniques can reduce the labeling effort, it is unclear whether a saliency model trained with weakly-supervised data (e.g., point annotation) can achieve the equivalent performance of its fully-supervised version. This paper attempts to answer this unexplored question by proving a hypothesis: there is a point-labeled dataset where saliency models trained on it can achieve equivalent performance when trained on the densely annotated dataset. To prove this conjecture, we proposed a novel yet effective adversarial trajectory-ensemble active learning (ATAL). Our contributions are three-fold: 1) Our proposed adversarial attack triggering uncertainty can conquer the overconfidence of existing active learning methods and accurately locate these uncertain pixels. {2)} Our proposed trajectory-ensemble uncertainty estimation method maintains the advantages of the ensemble networks while significantly reducing the computational cost. {3)} Our proposed relationship-aware diversity sampling algorithm can conquer oversampling while boosting performance. Experimental results show that our ATAL can find such a point-labeled dataset, where a saliency model trained on it obtained $97\%$ -- $99\%$ performance of its fully-supervised version with only ten annotated points per image.
* 9 pages, 8 figures
Complete-to-Partial 4D Distillation for Self-Supervised Point Cloud Sequence Representation Learning
Dec 13, 2022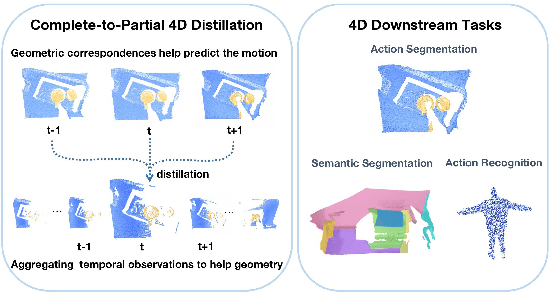
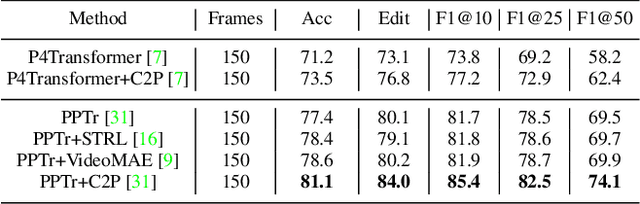
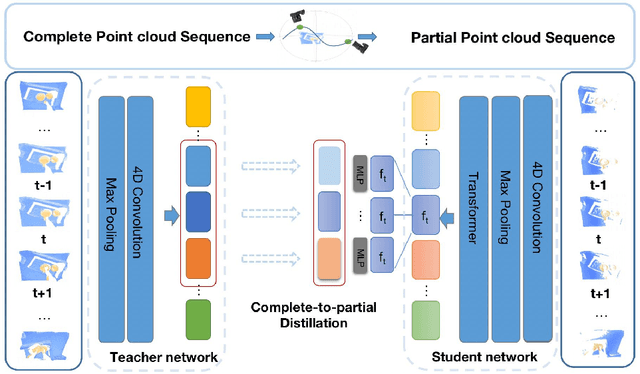
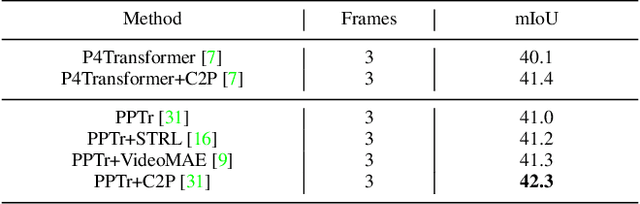
Recent work on 4D point cloud sequences has attracted a lot of attention. However, obtaining exhaustively labeled 4D datasets is often very expensive and laborious, so it is especially important to investigate how to utilize raw unlabeled data. However, most existing self-supervised point cloud representation learning methods only consider geometry from a static snapshot omitting the fact that sequential observations of dynamic scenes could reveal more comprehensive geometric details. And the video representation learning frameworks mostly model motion as image space flows, let alone being 3D-geometric-aware. To overcome such issues, this paper proposes a new 4D self-supervised pre-training method called Complete-to-Partial 4D Distillation. Our key idea is to formulate 4D self-supervised representation learning as a teacher-student knowledge distillation framework and let the student learn useful 4D representations with the guidance of the teacher. Experiments show that this approach significantly outperforms previous pre-training approaches on a wide range of 4D point cloud sequence understanding tasks including indoor and outdoor scenarios.