 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermined by User Needs: A Salient Object Detection Rationale Beyond Conventional Visual Stimuli
Apr 04, 2026Existing \textbf{s}alient \textbf{o}bject \textbf{d}etection (SOD) methods adopt a \textbf{passive} visual stimulus-based rationale--objects with the strongest visual stimuli are perceived as the user's primary focus (i.e., salient objects). They ignore the decisive role of users' \textbf{proactive needs} in segmenting salient objects--if a user has a need before seeing an image, the user's salient objects align with their needs, e.g., if a user's need is ``white apple'', when this user sees an image, the user's primary focus is on the ``white apple'' or ``the most white apple-like'' objects in the image. Such an oversight not only \textbf{fails to satisfy users}, but also \textbf{limits the development of downstream tasks}. For instance, in salient object ranking tasks, focusing solely on visual stimuli-based salient objects is insufficient for conducting an analysis of fine-grained relationships between users' viewing order (usually determined by user's needs) and scenes, which may result in wrong ranking results. Clearly, it is essential to detect salient objects based on user needs. Thus, we advocate a \textbf{User} \textbf{S}alient \textbf{O}bject \textbf{D}etection (UserSOD) task, which focuses on \textbf{detecting salient objects align with users' proactive needs when user have needs}. The main challenge for this new task is the lack of datasets for model training and testing.
READ-Net: Clarifying Emotional Ambiguity via Adaptive Feature Recalibration for Audio-Visual Depression Detection
Jan 21, 2026Depression is a severe global mental health issue that impairs daily functioning and overall quality of life. Although recent audio-visual approaches have improved automatic depression detection, methods that ignore emotional cues often fail to capture subtle depressive signals hidden within emotional expressions. Conversely, those incorporating emotions frequently confuse transient emotional expressions with stable depressive symptoms in feature representations, a phenomenon termed \emph{Emotional Ambiguity}, thereby leading to detection errors. To address this critical issue, we propose READ-Net, the first audio-visual depression detection framework explicitly designed to resolve Emotional Ambiguity through Adaptive Feature Recalibration (AFR). The core insight of AFR is to dynamically adjust the weights of emotional features to enhance depression-related signals. Rather than merely overlooking or naively combining emotional information, READ-Net innovatively identifies and preserves depressive-relevant cues within emotional features, while adaptively filtering out irrelevant emotional noise. This recalibration strategy significantly clarifies feature representations, and effectively mitigates the persistent challenge of emotional interference. Additionally, READ-Net can be easily integrated into existing frameworks for improved performance. Extensive evaluations on three publicly available datasets show that READ-Net outperforms state-of-the-art methods, with average gains of 4.55\% in accuracy and 1.26\% in F1-score, demonstrating its robustness to emotional disturbances and improving audio-visual depression detection.
EditEmoTalk: Controllable Speech-Driven 3D Facial Animation with Continuous Expression Editing
Jan 15, 2026Speech-driven 3D facial animation aims to generate realistic and expressive facial motions directly from audio. While recent methods achieve high-quality lip synchronization, they often rely on discrete emotion categories, limiting continuous and fine-grained emotional control. We present EditEmoTalk, a controllable speech-driven 3D facial animation framework with continuous emotion editing. The key idea is a boundary-aware semantic embedding that learns the normal directions of inter-emotion decision boundaries, enabling a continuous expression manifold for smooth emotion manipulation. Moreover, we introduce an emotional consistency loss that enforces semantic alignment between the generated motion dynamics and the target emotion embedding through a mapping network, ensuring faithful emotional expression. Extensive experiments demonstrate that EditEmoTalk achieves superior controllability, expressiveness, and generalization while maintaining accurate lip synchronization. Code and pretrained models will be released.
GenCAMO: Scene-Graph Contextual Decoupling for Environment-aware and Mask-free Camouflage Image-Dense Annotation Generation
Jan 03, 2026Conceal dense prediction (CDP), especially RGB-D camouflage object detection and open-vocabulary camouflage object segmentation, plays a crucial role in advancing the understanding and reasoning of complex camouflage scenes. However, high-quality and large-scale camouflage datasets with dense annotation remain scarce due to expensive data collection and labeling costs. To address this challenge, we explore leveraging generative models to synthesize realistic camouflage image-dense data for training CDP models with fine-grained representations, prior knowledge, and auxiliary reasoning. Concretely, our contributions are threefold: (i) we introduce GenCAMO-DB, a large-scale camouflage dataset with multi-modal annotations, including depth maps, scene graphs, attribute descriptions, and text prompts; (ii) we present GenCAMO, an environment-aware and mask-free generative framework that produces high-fidelity camouflage image-dense annotations; (iii) extensive experiments across multiple modalities demonstrate that GenCAMO significantly improves dense prediction performance on complex camouflage scenes by providing high-quality synthetic data. The code and datasets will be released after paper acceptance.
Unveiling Context-Related Anomalies: Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection
Sep 05, 2024Detecting anomalies in human-related videos is crucial for surveillance applications. Current methods primarily include appearance-based and action-based techniques. Appearance-based methods rely on low-level visual features such as color, texture, and shape. They learn a large number of pixel patterns and features related to known scenes during training, making them effective in detecting anomalies within these familiar contexts. However, when encountering new or significantly changed scenes, i.e., unknown scenes, they often fail because existing SOTA methods do not effectively capture the relationship between actions and their surrounding scenes, resulting in low generalization. In contrast, action-based methods focus on detecting anomalies in human actions but are usually less informative because they tend to overlook the relationship between actions and their scenes, leading to incorrect detection. For instance, the normal event of running on the beach and the abnormal event of running on the street might both be considered normal due to the lack of scene information. In short, current methods struggle to integrate low-level visual and high-level action features, leading to poor anomaly detection in varied and complex scenes. To address this challenge, we propose a novel decoupling-based architecture for human-related video anomaly detection (DecoAD). DecoAD significantly improves the integration of visual and action features through the decoupling and interweaving of scenes and actions, thereby enabling a more intuitive and accurate understanding of complex behaviors and scenes. DecoAD supports fully supervised, weakly supervised, and unsupervised settings.
Colorectal Polyp Segmentation in the Deep Learning Era: A Comprehensive Survey
Jan 22, 2024Colorectal polyp segmentation (CPS), an essential problem in medical image analysis, has garnered growing research attention. Recently, the deep learning-based model completely overwhelmed traditional methods in the field of CPS, and more and more deep CPS methods have emerged, bringing the CPS into the deep learning era. To help the researchers quickly grasp the main techniques, datasets, evaluation metrics, challenges, and trending of deep CPS, this paper presents a systematic and comprehensive review of deep-learning-based CPS methods from 2014 to 2023, a total of 115 technical papers. In particular, we first provide a comprehensive review of the current deep CPS with a novel taxonomy, including network architectures, level of supervision, and learning paradigm. More specifically, network architectures include eight subcategories, the level of supervision comprises six subcategories, and the learning paradigm encompasses 12 subcategories, totaling 26 subcategories. Then, we provided a comprehensive analysis the characteristics of each dataset, including the number of datasets, annotation types, image resolution, polyp size, contrast values, and polyp location. Following that, we summarized CPS's commonly used evaluation metrics and conducted a detailed analysis of 40 deep SOTA models, including out-of-distribution generalization and attribute-based performance analysis. Finally, we discussed deep learning-based CPS methods' main challenges and opportunities.
Rethinking Object Saliency Ranking: A Novel Whole-flow Processing Paradigm
Dec 06, 2023



Existing salient object detection methods are capable of predicting binary maps that highlight visually salient regions. However, these methods are limited in their ability to differentiate the relative importance of multiple objects and the relationships among them, which can lead to errors and reduced accuracy in downstream tasks that depend on the relative importance of multiple objects. To conquer, this paper proposes a new paradigm for saliency ranking, which aims to completely focus on ranking salient objects by their "importance order". While previous works have shown promising performance, they still face ill-posed problems. First, the saliency ranking ground truth (GT) orders generation methods are unreasonable since determining the correct ranking order is not well-defined, resulting in false alarms. Second, training a ranking model remains challenging because most saliency ranking methods follow the multi-task paradigm, leading to conflicts and trade-offs among different tasks. Third, existing regression-based saliency ranking methods are complex for saliency ranking models due to their reliance on instance mask-based saliency ranking orders. These methods require a significant amount of data to perform accurately and can be challenging to implement effectively. To solve these problems, this paper conducts an in-depth analysis of the causes and proposes a whole-flow processing paradigm of saliency ranking task from the perspective of "GT data generation", "network structure design" and "training protocol". The proposed approach outperforms existing state-of-the-art methods on the widely-used SALICON set, as demonstrated by extensive experiments with fair and reasonable comparisons. The saliency ranking task is still in its infancy, and our proposed unified framework can serve as a fundamental strategy to guide future work.
WinDB: HMD-free and Distortion-free Panoptic Video Fixation Learning
May 23, 2023To date, the widely-adopted way to perform fixation collection in panoptic video is based on a head-mounted display (HMD), where participants' fixations are collected while wearing an HMD to explore the given panoptic scene freely. However, this widely-used data collection method is insufficient for training deep models to accurately predict which regions in a given panoptic are most important when it contains intermittent salient events. The main reason is that there always exist "blind zooms" when using HMD to collect fixations since the participants cannot keep spinning their heads to explore the entire panoptic scene all the time. Consequently, the collected fixations tend to be trapped in some local views, leaving the remaining areas to be the "blind zooms". Therefore, fixation data collected using HMD-based methods that accumulate local views cannot accurately represent the overall global importance of complex panoramic scenes. This paper introduces the auxiliary Window with a Dynamic Blurring (WinDB) fixation collection approach for panoptic video, which doesn't need HMD and is blind-zoom-free. Thus, the collected fixations can well reflect the regional-wise importance degree. Using our WinDB approach, we have released a new PanopticVideo-300 dataset, containing 300 panoptic clips covering over 225 categories. Besides, we have presented a simple baseline design to take full advantage of PanopticVideo-300 to handle the blind-zoom-free attribute-induced fixation shifting problem. Our WinDB approach, PanopticVideo-300, and tailored fixation prediction model are all publicly available at https://github.com/360submit/WinDB.
Pixel is All You Need: Adversarial Trajectory-Ensemble Active Learning for Salient Object Detection
Dec 13, 2022



Although weakly-supervised techniques can reduce the labeling effort, it is unclear whether a saliency model trained with weakly-supervised data (e.g., point annotation) can achieve the equivalent performance of its fully-supervised version. This paper attempts to answer this unexplored question by proving a hypothesis: there is a point-labeled dataset where saliency models trained on it can achieve equivalent performance when trained on the densely annotated dataset. To prove this conjecture, we proposed a novel yet effective adversarial trajectory-ensemble active learning (ATAL). Our contributions are three-fold: 1) Our proposed adversarial attack triggering uncertainty can conquer the overconfidence of existing active learning methods and accurately locate these uncertain pixels. {2)} Our proposed trajectory-ensemble uncertainty estimation method maintains the advantages of the ensemble networks while significantly reducing the computational cost. {3)} Our proposed relationship-aware diversity sampling algorithm can conquer oversampling while boosting performance. Experimental results show that our ATAL can find such a point-labeled dataset, where a saliency model trained on it obtained $97\%$ -- $99\%$ performance of its fully-supervised version with only ten annotated points per image.
* 9 pages, 8 figures
Synthetic Data Supervised Salient Object Detection
Oct 25, 2022
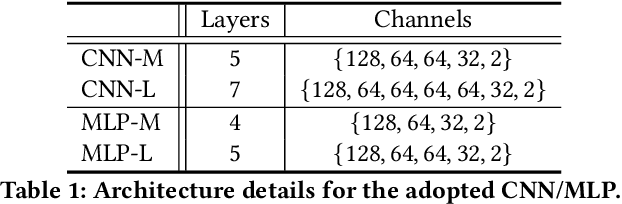
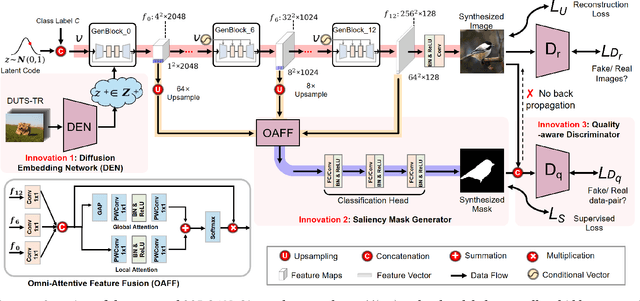
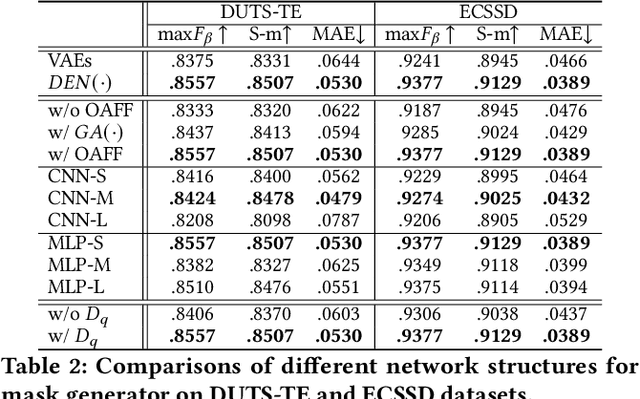
Although deep salient object detection (SOD) has achieved remarkable progress, deep SOD models are extremely data-hungry, requiring large-scale pixel-wise annotations to deliver such promising results. In this paper, we propose a novel yet effective method for SOD, coined SODGAN, which can generate infinite high-quality image-mask pairs requiring only a few labeled data, and these synthesized pairs can replace the human-labeled DUTS-TR to train any off-the-shelf SOD model. Its contribution is three-fold. 1) Our proposed diffusion embedding network can address the manifold mismatch and is tractable for the latent code generation, better matching with the ImageNet latent space. 2) For the first time, our proposed few-shot saliency mask generator can synthesize infinite accurate image synchronized saliency masks with a few labeled data. 3) Our proposed quality-aware discriminator can select highquality synthesized image-mask pairs from noisy synthetic data pool, improving the quality of synthetic data. For the first time, our SODGAN tackles SOD with synthetic data directly generated from the generative model, which opens up a new research paradigm for SOD. Extensive experimental results show that the saliency model trained on synthetic data can achieve $98.4\%$ F-measure of the saliency model trained on the DUTS-TR. Moreover, our approach achieves a new SOTA performance in semi/weakly-supervised methods, and even outperforms several fully-supervised SOTA methods. Code is available at https://github.com/wuzhenyubuaa/SODGAN
* 9 pages, 8 figures