 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoding-Free and Privacy-Preserving MCP Framework for Clinical Agentic Research Intelligence System
Apr 14, 2026Clinical research involves labor-intensive processes such as study design, cohort construction, model development, and documentation, requiring domain expertise, programming skills, and access to sensitive patient data. These demands create barriers for clinicians and external researchers conducting data-driven studies. To overcome these limitations, we developed a Clinical Agentic Research Intelligence System (CARIS) that automates the clinical research workflow while preserving data privacy, enabling comprehensive studies without direct access to raw data. CARIS integrates Large Language Models (LLMs) with modular tools via the Model Context Protocol (MCP), enabling natural language-driven orchestration of appropriate tools. Databases remain securely within the MCP server, and users access only the outputs and final research reports. Based on user intent, CARIS automatically executes the full pipeline: research planning, literature search, cohort construction, Institutional Review Board (IRB) documentation, Vibe Machine Learning (ML), and report generation, with iterative human-in-the-loop refinement. We evaluated CARIS on three heterogeneous datasets with distinct clinical tasks. Research plans and IRB documents were finalized within three to four iterations, using evidence from literature and data. The system supported Vibe ML by exploring feature-model combinations, ranking the top ten models, and generating performance visualizations. Final reports showed high completeness based on a checklist derived from the TRIPOD+AI framework, achieving 96% coverage in LLM evaluation and 82% in human evaluation. CARIS demonstrates that agentic AI can transform clinical hypotheses into executable research workflows across heterogeneous datasets. By eliminating the need for coding and direct data access, the system lowers barriers and bridges public and private clinical data environments.
TempGNN: Temporal Graph Neural Networks for Dynamic Session-Based Recommendations
Oct 20, 2023Session-based recommendations which predict the next action by understanding a user's interaction behavior with items within a relatively short ongoing session have recently gained increasing popularity. Previous research has focused on capturing the dynamics of sequential dependencies from complicated item transitions in a session by means of recurrent neural networks, self-attention models, and recently, mostly graph neural networks. Despite the plethora of different models relying on the order of items in a session, few approaches have been proposed for dealing better with the temporal implications between interactions. We present Temporal Graph Neural Networks (TempGNN), a generic framework for capturing the structural and temporal dynamics in complex item transitions utilizing temporal embedding operators on nodes and edges on dynamic session graphs, represented as sequences of timed events. Extensive experimental results show the effectiveness and adaptability of the proposed method by plugging it into existing state-of-the-art models. Finally, TempGNN achieved state-of-the-art performance on two real-world e-commerce datasets.
DeepOnto: A Python Package for Ontology Engineering with Deep Learning
Jul 06, 2023



Applying deep learning techniques, particularly language models (LMs), in ontology engineering has raised widespread attention. However, deep learning frameworks like PyTorch and Tensorflow are predominantly developed for Python programming, while widely-used ontology APIs, such as the OWL API and Jena, are primarily Java-based. To facilitate seamless integration of these frameworks and APIs, we present Deeponto, a Python package designed for ontology engineering. The package encompasses a core ontology processing module founded on the widely-recognised and reliable OWL API, encapsulating its fundamental features in a more "Pythonic" manner and extending its capabilities to include other essential components including reasoning, verbalisation, normalisation, projection, and more. Building on this module, Deeponto offers a suite of tools, resources, and algorithms that support various ontology engineering tasks, such as ontology alignment and completion, by harnessing deep learning methodologies, primarily pre-trained LMs. In this paper, we also demonstrate the practical utility of Deeponto through two use-cases: the Digital Health Coaching in Samsung Research UK and the Bio-ML track of the Ontology Alignment Evaluation Initiative (OAEI).
Revisiting Image Pyramid Structure for High Resolution Salient Object Detection
Sep 26, 2022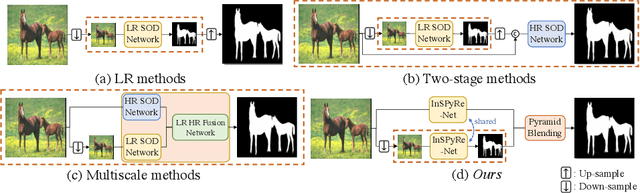
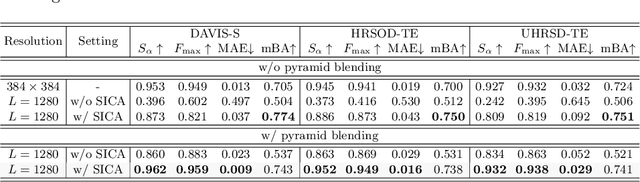

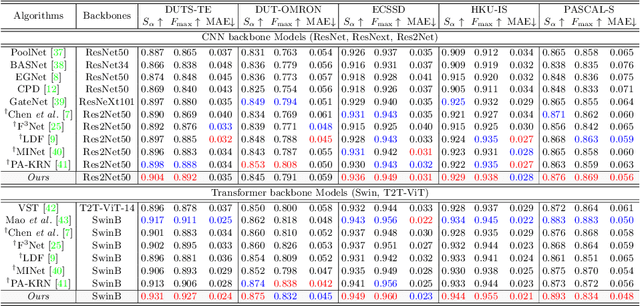
Salient object detection (SOD) has been in the spotlight recently, yet has been studied less for high-resolution (HR) images. Unfortunately, HR images and their pixel-level annotations are certainly more labor-intensive and time-consuming compared to low-resolution (LR) images and annotations. Therefore, we propose an image pyramid-based SOD framework, Inverse Saliency Pyramid Reconstruction Network (InSPyReNet), for HR prediction without any of HR datasets. We design InSPyReNet to produce a strict image pyramid structure of saliency map, which enables to ensemble multiple results with pyramid-based image blending. For HR prediction, we design a pyramid blending method which synthesizes two different image pyramids from a pair of LR and HR scale from the same image to overcome effective receptive field (ERF) discrepancy. Our extensive evaluations on public LR and HR SOD benchmarks demonstrate that InSPyReNet surpasses the State-of-the-Art (SotA) methods on various SOD metrics and boundary accuracy.
SR-GCL: Session-Based Recommendation with Global Context Enhanced Augmentation in Contrastive Learning
Sep 23, 2022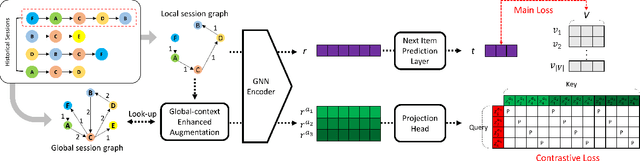
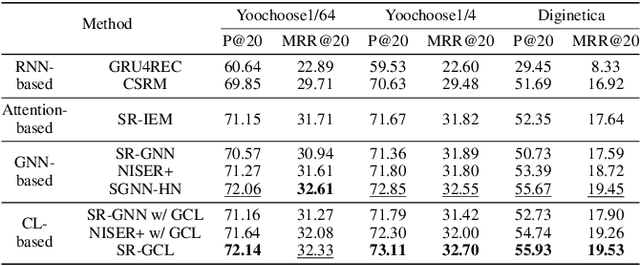
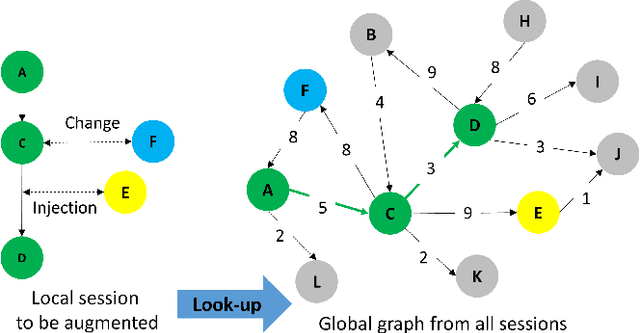
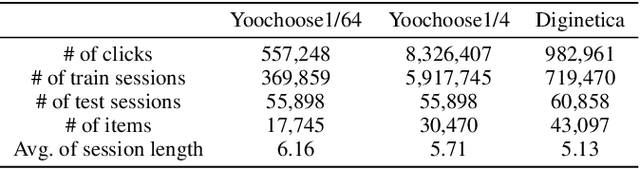
Session-based recommendations aim to predict the next behavior of users based on ongoing sessions. The previous works have been modeling the session as a variable-length of a sequence of items and learning the representation of both individual items and the aggregated session. Recent research has applied graph neural networks with an attention mechanism to capture complicated item transitions and dependencies by modeling the sessions into graph-structured data. However, they still face fundamental challenges in terms of data and learning methodology such as sparse supervision signals and noisy interactions in sessions, leading to sub-optimal performance. In this paper, we propose SR-GCL, a novel contrastive learning framework for a session-based recommendation. As a crucial component of contrastive learning, we propose two global context enhanced data augmentation methods while maintaining the semantics of the original session. The extensive experiment results on two real-world E-commerce datasets demonstrate the superiority of SR-GCL as compared to other state-of-the-art methods.
STING: Self-attention based Time-series Imputation Networks using GAN
Sep 22, 2022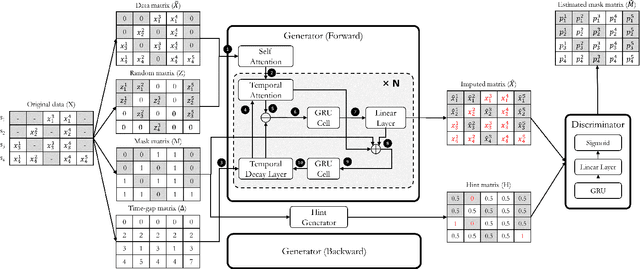
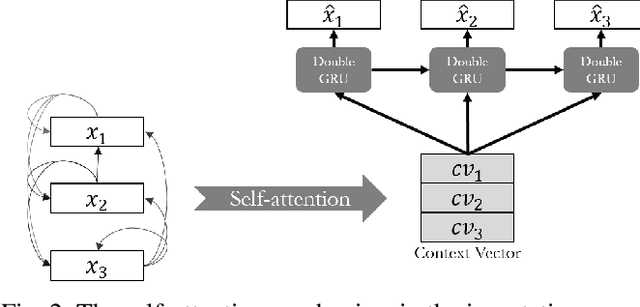
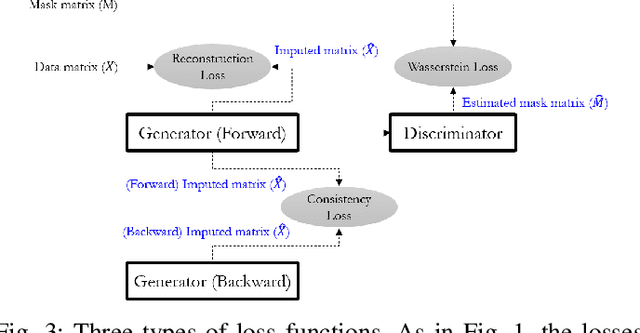
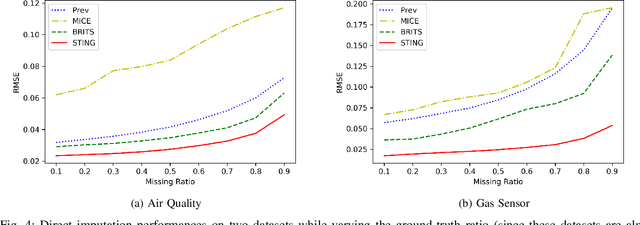
Time series data are ubiquitous in real-world applications. However, one of the most common problems is that the time series data could have missing values by the inherent nature of the data collection process. So imputing missing values from multivariate (correlated) time series data is imperative to improve a prediction performance while making an accurate data-driven decision. Conventional works for imputation simply delete missing values or fill them based on mean/zero. Although recent works based on deep neural networks have shown remarkable results, they still have a limitation to capture the complex generation process of the multivariate time series. In this paper, we propose a novel imputation method for multivariate time series data, called STING (Self-attention based Time-series Imputation Networks using GAN). We take advantage of generative adversarial networks and bidirectional recurrent neural networks to learn latent representations of the time series. In addition, we introduce a novel attention mechanism to capture the weighted correlations of the whole sequence and avoid potential bias brought by unrelated ones. Experimental results on three real-world datasets demonstrate that STING outperforms the existing state-of-the-art methods in terms of imputation accuracy as well as downstream tasks with the imputed values therein.
A Style-aware Discriminator for Controllable Image Translation
Mar 29, 2022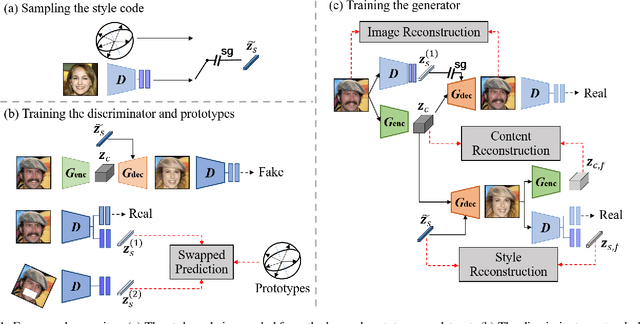
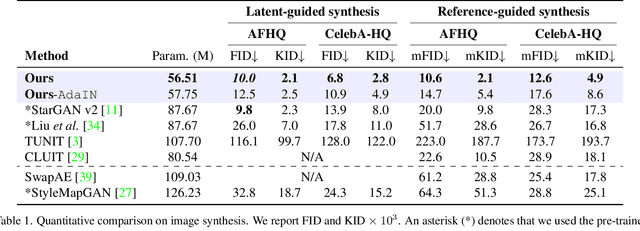

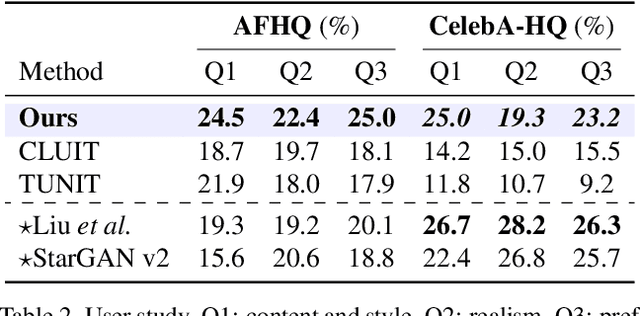
Current image-to-image translations do not control the output domain beyond the classes used during training, nor do they interpolate between different domains well, leading to implausible results. This limitation largely arises because labels do not consider the semantic distance. To mitigate such problems, we propose a style-aware discriminator that acts as a critic as well as a style encoder to provide conditions. The style-aware discriminator learns a controllable style space using prototype-based self-supervised learning and simultaneously guides the generator. Experiments on multiple datasets verify that the proposed model outperforms current state-of-the-art image-to-image translation methods. In contrast with current methods, the proposed approach supports various applications, including style interpolation, content transplantation, and local image translation.
Finding essential parts of the brain in rs-fMRI can improve diagnosing ADHD by Deep Learning
Aug 14, 2021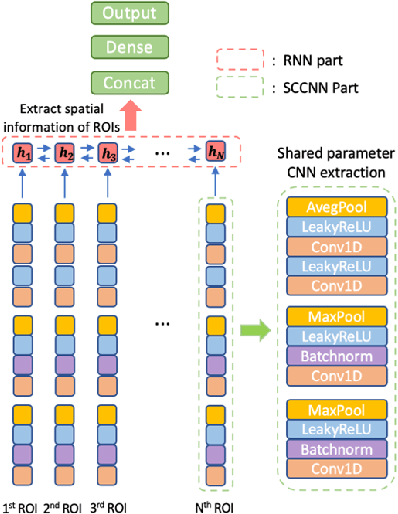

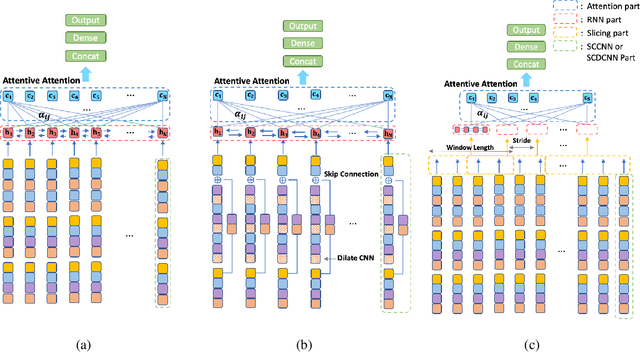

Attention Deficit\Hyperactivity Disorder(ADHD) is considered a very common psychiatric disorder, but it is difficult to establish an accurate diagnostic method for ADHD. Recently, with the development of computing resources and machine learning methods, studies have been conducted to classify ADHD using resting-state functional magnetic resonance(rsfMRI) imaging data. However, most of them utilized all areas of the brain for training the models. In this study, as a different way from this approach, we conducted a study to classify ADHD by selecting areas that are essential for using a deep learning model. For the experiment, rsfMRI data provided by ADHD 200 global competition was used. To obtain an integrated result from the multiple sites, each region of the brain was evaluated with Leave one site out cross-validation. As a result, when we only used 15 important region of interest(ROIs) for training, an accuracy of 70.6% was obtained, significantly exceeding the existing results of 68.6% from all ROIs. In addition, to explore the new structure based on SCCNN-RNN, we performed the same experiment with three modified models: (1) Separate Channel CNN RNN with Attention (ASCRNN), (2) Separate Channel dilate CNN RNN with Attention (ASDRNN), (3) Separate Channel CNN slicing RNN with Attention (ASSRNN). As a result, the ASSRNN model provided a high accuracy of 70.46% when training with only 13 important region of interest (ROI). These results show that finding and using the crucial parts of the brain in diagnosing ADHD by Deep Learning can get better results than using all areas.
UACANet: Uncertainty Augmented Context Attention for Polyp Segmentation
Jul 22, 2021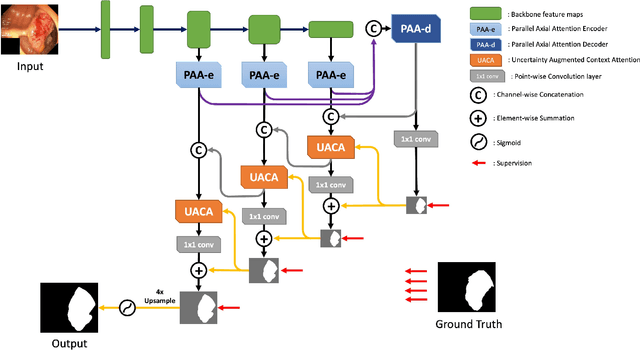
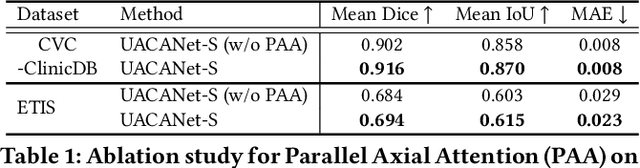
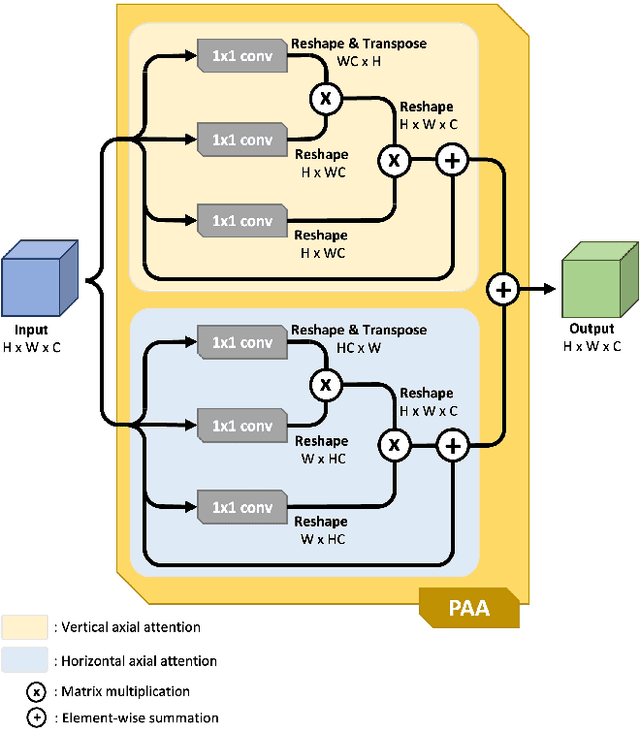
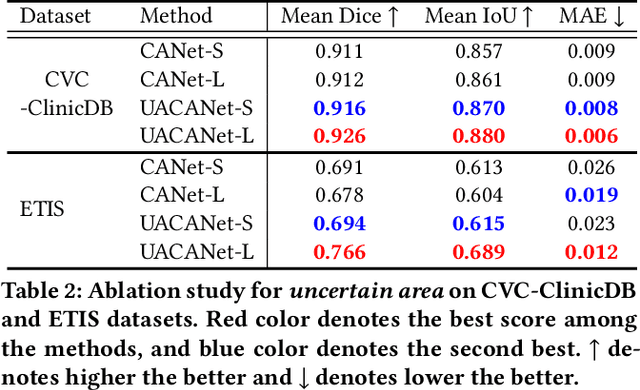
We propose Uncertainty Augmented Context Attention network (UACANet) for polyp segmentation which consider a uncertain area of the saliency map. We construct a modified version of U-Net shape network with additional encoder and decoder and compute a saliency map in each bottom-up stream prediction module and propagate to the next prediction module. In each prediction module, previously predicted saliency map is utilized to compute foreground, background and uncertain area map and we aggregate the feature map with three area maps for each representation. Then we compute the relation between each representation and each pixel in the feature map. We conduct experiments on five popular polyp segmentation benchmarks, Kvasir, CVC-ClinicDB, ETIS, CVC-ColonDB and CVC-300, and achieve state-of-the-art performance. Especially, we achieve 76.6% mean Dice on ETIS dataset which is 13.8% improvement compared to the previous state-of-the-art method. Source code is publicly available at https://github.com/plemeri/UACANet
SpaceMeshLab: Spatial Context Memoization and Meshgrid Atrous Convolution Consensus for Semantic Segmentation
Jun 08, 2021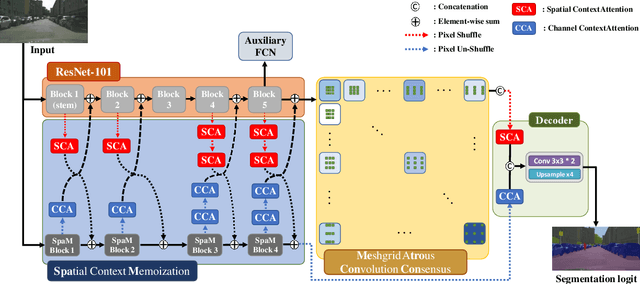

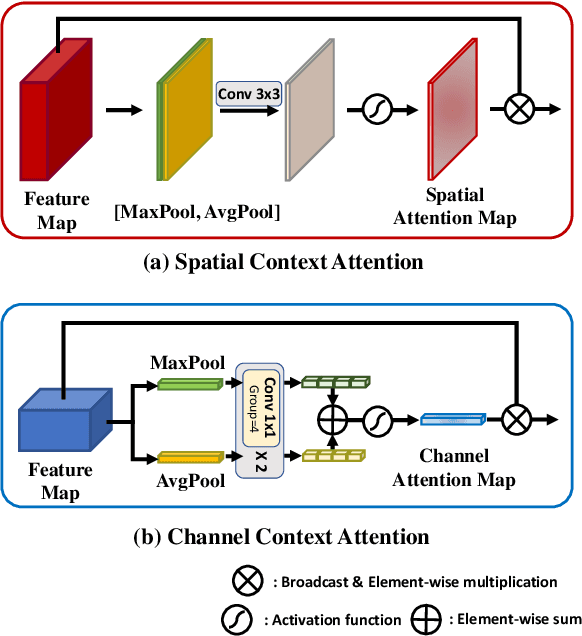

Semantic segmentation networks adopt transfer learning from image classification networks which occurs a shortage of spatial context information. For this reason, we propose Spatial Context Memoization (SpaM), a bypassing branch for spatial context by retaining the input dimension and constantly communicating its spatial context and rich semantic information mutually with the backbone network. Multi-scale context information for semantic segmentation is crucial for dealing with diverse sizes and shapes of target objects in the given scene. Conventional multi-scale context scheme adopts multiple effective receptive fields by multiple dilation rates or pooling operations, but often suffer from misalignment problem with respect to the target pixel. To this end, we propose Meshgrid Atrous Convolution Consensus (MetroCon^2) which brings multi-scale scheme into fine-grained multi-scale object context using convolutions with meshgrid-like scattered dilation rates. SpaceMeshLab (ResNet-101 + SpaM + MetroCon^2) achieves 82.0% mIoU in Cityscapes test and 53.5% mIoU on Pascal-Context validation set.