 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Aliasing Snapshot HDR Imaging Using Non-Regular Sensing
Mar 05, 2026Snapshot HDR imaging is essential to capture the full dynamic range of a scene in a single exposure, making it essential for video and dynamic environments where motion prevents the use of multi-exposure techniques or complex hardware set-ups. This work presents a snapshot HDR imaging sensor that is based on spatially varying apertures, implemented by combining two differently sized prototype pixels. The different light integration areas physically extend the dynamic range towards the lower end, compared to a standard high resolution sensor. A non-regular pixel arrangement is suggested, to mitigate aliasing and overcome a loss in spatial resolution that is associated with increased light integration area of the larger prototype pixel. Subsequent reconstruction in the Fourier domain, where natural images can be sparsely represented allows to recover the image with high detail. The image acquisition approach with the proposed non-regular HDR sensor is simulated and analysed with special emphasis on the spatial resolution. The results suggest the snapshot HDR sensor layout to be an effective way to acquire images with high dynamic range and free from aliasing artefacts.
Towards Object Segmentation Mask Selection Using Specular Reflections
Feb 25, 2026Specular reflections pose a significant challenge for object segmentation, as their sharp intensity transitions often mislead both conventional algorithms and deep learning based methods. However, as the specular reflection must lie on the surface of the object, this fact can be exploited to improve the segmentation masks. By identifying the largest region containing the reflection as the object, we derive a more accurate object mask without requiring specialized training data or model adaption. We evaluate our method on both synthetic and real world images and compare it against established and state-of-the-art techniques including Otsu thresholding, YOLO, and SAM2. Compared to the best performing baseline SAM2, our approach achieves up to 26.7% improvement in IoU, 22.3% in DSC, and 9.7% in pixel accuracy. Qualitative evaluations on real world images further confirm the robustness and generalizability of the proposed approach.
Domain Adaptation for Camera-Specific Image Characteristics using Shallow Discriminators
Nov 13, 2025



Each image acquisition setup leads to its own camera-specific image characteristics degrading the image quality. In learning-based perception algorithms, characteristics occurring during the application phase, but absent in the training data, lead to a domain gap impeding the performance. Previously, pixel-level domain adaptation through unpaired learning of the pristine-to-distorted mapping function has been proposed. In this work, we propose shallow discriminator architectures to address limitations of these approaches. We show that a smaller receptive field size improves learning of unknown image distortions by more accurately reproducing local distortion characteristics at a low network complexity. In a domain adaptation setup for instance segmentation, we achieve mean average precision increases over previous methods of up to 0.15 for individual distortions and up to 0.16 for camera-specific image characteristics in a simplified camera model. In terms of number of parameters, our approach matches the complexity of one state of the art method while reducing complexity by a factor of 20 compared to another, demonstrating superior efficiency without compromising performance.
Inter-Camera Color Correction for Multispectral Imaging with Camera Arrays Using a Consensus Image
Oct 30, 2024



This paper introduces a novel method for inter-camera color calibration for multispectral imaging with camera arrays using a consensus image. Capturing images using multispectral camera arrays has gained importance in medical, agricultural, and environmental processes. Due to fabrication differences, noise, or device altering, varying pixel sensitivities occur, influencing classification processes. Therefore, color calibration between the cameras is necessary. In existing methods, one of the camera images is chosen and considered as a reference, ignoring the color information of all other recordings. Our new approach does not just take one image as reference, but uses statistical information such as the location parameter to generate a consensus image as basis for calibration. This way, we managed to improve the PSNR values for the linear regression color correction algorithm by 1.15 dB and the improved color difference (iCID) values by 2.81.
Conditional Optimal Filter Selection for Multispectral Object Classification
Oct 02, 2024



Capturing images using multispectral camera arrays has gained importance in medical, agricultural and environmental processes. However, using all available spectral bands is infeasible and produces much data, while only a fraction is needed for a given task. Nearby bands may contain similar information, therefore redundant spectral bands should not be considered in the evaluation process to keep complexity and the data load low. In current methods, a restricted and pre-determined number of spectral bands is selected. Our approach improves this procedure by including preset conditions such as noise or the bandwidth of available filters, minimizing spectral redundancy. Furthermore, a minimal filter selection can be conducted, keeping the hardware setup at low costs, while still obtaining all important spectral information. In comparison to the fast binary search filter band selection method, we managed to reduce the amount of misclassified objects of the SMM dataset from 318 to 124 using a random forest classifier.
Fast Edge-Aware Occlusion Detection in the Context of Multispectral Camera Arrays
Aug 26, 2024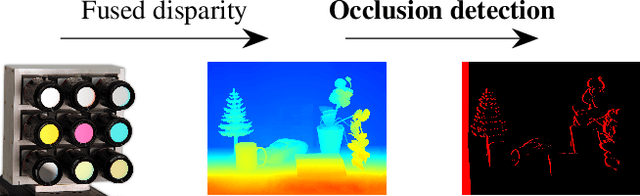
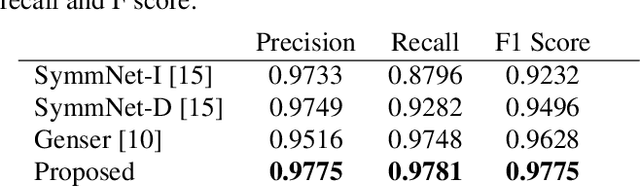
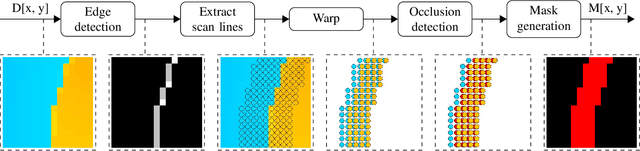
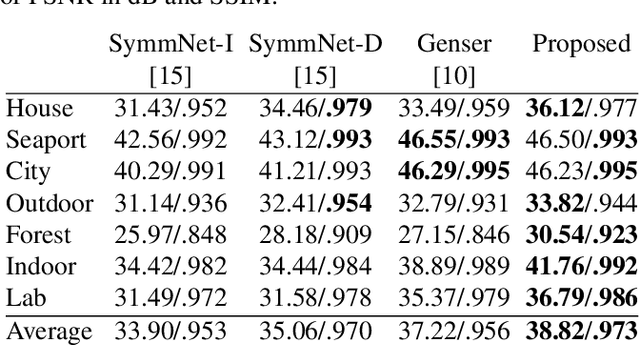
Multispectral imaging is very beneficial in diverse applications, like healthcare and agriculture, since it can capture absorption bands of molecules in different spectral areas. A promising approach for multispectral snapshot imaging are camera arrays. Image processing is necessary to warp all different views to the same view to retrieve a consistent multispectral datacube. This process is also called multispectral image registration. After a cross spectral disparity estimation, an occlusion detection is required to find the pixels that were not recorded by the peripheral cameras. In this paper, a novel fast edge-aware occlusion detection is presented, which is shown to reduce the runtime by at least a factor of 12. Moreover, an evaluation on ground truth data reveals better performance in terms of precision and recall. Finally, the quality of a final multispectral datacube can be improved by more than 1.5 dB in terms of PSNR as well as in terms of SSIM in an existing multispectral registration pipeline. The source code is available at \url{https://github.com/FAU-LMS/fast-occlusion-detection}.
High-Resolution Hyperspectral Video Imaging Using A Hexagonal Camera Array
Jul 12, 2024



Retrieving the reflectance spectrum from objects is an essential task for many classification and detection problems, since many materials and processes have a unique spectral behaviour. In many cases, it is highly desirable to capture hyperspectral images due to the high spectral flexibility. Often, it is even necessary to capture hyperspectral videos or at least to be able to record a hyperspectral image at once, also called snapshot hyperspectral imaging, to avoid spectral smearing. For this task, a high-resolution snapshot hyperspectral camera array using a hexagonal shape is introduced.The hexagonal array for hyperspectral imaging uses off-the-shelf hardware, which enables high flexibility regarding employed cameras, lenses and filters. Hence, the spectral range can be easily varied by mounting a different set of filters. Moreover, the concept of using off-the-shelf hardware enables low prices in comparison to other approaches with highly specialized hardware. Since classical industrial cameras are used in this hyperspectral camera array, the spatial and temporal resolution is very high, while recording 37 hyperspectral channels in the range from 400 nm to 760 nm in 10 nm steps. A registration process is required for near-field imaging, which maps the peripheral camera views to the center view. It is shown that this combination using a hyperspectral camera array and the corresponding image registration pipeline is superior in comparison to other popular snapshot approaches. For this evaluation, a synthetic hyperspectral database is rendered. On the synthetic data, the novel approach outperforms its best competitor by more than 3 dB in reconstruction quality. This synthetic data is also used to show the superiority of the hexagonal shape in comparison to an orthogonal-spaced one. Moreover, a real-world high resolution hyperspectral video database is provided.
A Study on the Effect of Color Spaces in Learned Image Compression
Jun 19, 2024



In this work, we present a comparison between color spaces namely YUV, LAB, RGB and their effect on learned image compression. For this we use the structure and color based learned image codec (SLIC) from our prior work, which consists of two branches - one for the luminance component (Y or L) and another for chrominance components (UV or AB). However, for the RGB variant we input all 3 channels in a single branch, similar to most learned image codecs operating in RGB. The models are trained for multiple bitrate configurations in each color space. We report the findings from our experiments by evaluating them on various datasets and compare the results to state-of-the-art image codecs. The YUV model performs better than the LAB variant in terms of MS-SSIM with a Bj{\o}ntegaard delta bitrate (BD-BR) gain of 7.5\% using VTM intra-coding mode as the baseline. Whereas the LAB variant has a better performance than YUV model in terms of CIEDE2000 having a BD-BR gain of 8\%. Overall, the RGB variant of SLIC achieves the best performance with a BD-BR gain of 13.14\% in terms of MS-SSIM and a gain of 17.96\% in CIEDE2000 at the cost of a higher model complexity.
Multispectral Snapshot Image Registration Using Learned Cross Spectral Disparity Estimation and a Deep Guided Occlusion Reconstruction Network
Jun 17, 2024



Multispectral imaging aims at recording images in different spectral bands. This is extremely beneficial in diverse discrimination applications, for example in agriculture, recycling or healthcare. One approach for snapshot multispectral imaging, which is capable of recording multispectral videos, is by using camera arrays, where each camera records a different spectral band. Since the cameras are at different spatial positions, a registration procedure is necessary to map every camera to the same view. In this paper, we present a multispectral snapshot image registration with three novel components. First, a cross spectral disparity estimation network is introduced, which is trained on a popular stereo database using pseudo spectral data augmentation. Subsequently, this disparity estimation is used to accurately detect occlusions by warping the disparity map in a layer-wise manner. Finally, these detected occlusions are reconstructed by a learned deep guided neural network, which leverages the structure from other spectral components. It is shown that each element of this registration process as well as the final result is superior to the current state of the art. In terms of PSNR, our registration achieves an improvement of over 3 dB. At the same time, the runtime is decreased by a factor of over 3 on a CPU. Additionally, the registration is executable on a GPU, where the runtime can be decreased by a factor of 111. The source code and the data is available at https://github.com/FAU-LMS/MSIR.
A Guided Upsampling Network for Short Wave Infrared Images Using Graph Regularization
Dec 14, 2023



Exploiting the infrared area of the spectrum for classification problems is getting increasingly popular, because many materials have characteristic absorption bands in this area. However, sensors in the short wave infrared (SWIR) area and even higher wavelengths have a very low spatial resolution in comparison to classical cameras that operate in the visible wavelength area. Thus, in this paper an upsampling method for SWIR images guided by a visible image is presented. For that, the proposed guided upsampling network (GUNet) uses a graph-regularized optimization problem based on learned affinities is presented. The evaluation is based on a novel synthetic near-field visible-SWIR stereo database. Different guided upsampling methods are evaluated, which shows an improvement of nearly 1 dB on this database for the proposed upsampling method in comparison to the second best guided upsampling network. Furthermore, a visual example of an upsampled SWIR image of a real-world scene is depicted for showing real-world applicability.