 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Living Images: A Recursive Approach to Computing the Structural Beauty of Images or the Livingness of Space
Jan 04, 2023


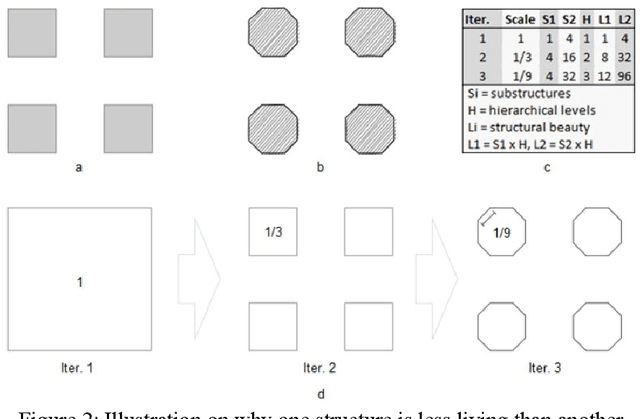
Any image is perceived subconsciously as a coherent structure (or whole) with two contrast substructures: figure and ground. The figure consists of numerous auto-generated substructures with an inherent hierarchy of far more smalls than larges. Through these substructures, the structural beauty of an image (L) can be computed by the multiplication of the number of substructures (S) and their inherent hierarchy (H). This definition implies that the more substructures, the more living or more structurally beautiful, and the higher hierarchy of the substructures, the more living or more structurally beautiful. This is the non-recursive approach to the structural beauty of images or the livingness of space. In this paper we develop a recursive approach, which derives all substructures of an image (instead of its figure) and continues the deriving process for those decomposable substructures until none of them are decomposable. All of the substructures derived at different iterations (or recursive levels) together constitute a living structure; hence the notion of living images. We applied the recursive approach to a set of images and found that (1) the number of substructures of an image is far lower (3 percent on average) than the number of pixels and the centroids of the substructures can effectively capture the skeleton or saliency of the image; (2) all the images have the recursive levels more than three, indicating that they are indeed living images; (3) no more than 2 percent of the substructures are decomposable; (4) structural beauty can be measured by the recursively defined substructures, as well as their decomposable subsets. The recursive approach is proved to be more robust than the non-recursive approach. The recursive approach and the non-recursive approach both provide a powerful means to study the livingness or vitality of space in cities and communities.
Class-Continuous Conditional Generative Neural Radiance Field
Jan 09, 2023

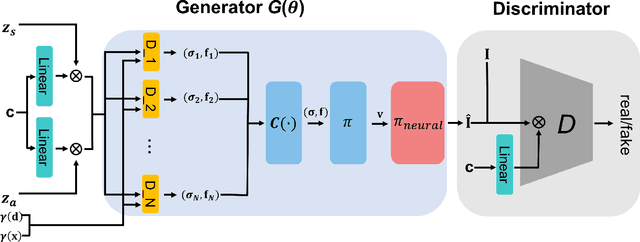
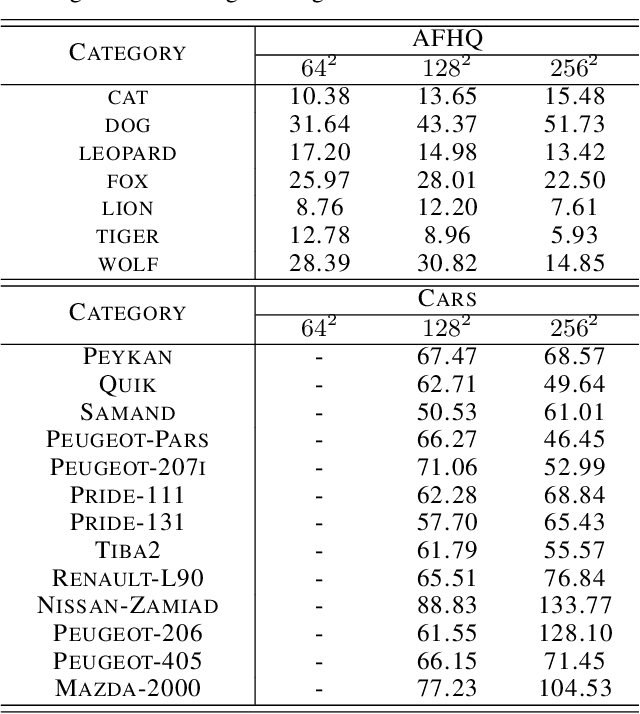
The 3D-aware image synthesis focuses on conserving spatial consistency besides generating high-resolution images with fine details. Recently, Neural Radiance Field (NeRF) has been introduced for synthesizing novel views with low computational cost and superior performance. While several works investigate a generative NeRF and show remarkable achievement, they cannot handle conditional and continuous feature manipulation in the generation procedure. In this work, we introduce a novel model, called Class-Continuous Conditional Generative NeRF ($\text{C}^{3}$G-NeRF), which can synthesize conditionally manipulated photorealistic 3D-consistent images by projecting conditional features to the generator and the discriminator. The proposed $\text{C}^{3}$G-NeRF is evaluated with three image datasets, AFHQ, CelebA, and Cars. As a result, our model shows strong 3D-consistency with fine details and smooth interpolation in conditional feature manipulation. For instance, $\text{C}^{3}$G-NeRF exhibits a Fr\'echet Inception Distance (FID) of 7.64 in 3D-aware face image synthesis with a $\text{128}^{2}$ resolution. Additionally, we provide FIDs of generated 3D-aware images of each class of the datasets as it is possible to synthesize class-conditional images with $\text{C}^{3}$G-NeRF.
ELMformer: Efficient Raw Image Restoration with a Locally Multiplicative Transformer
Aug 31, 2022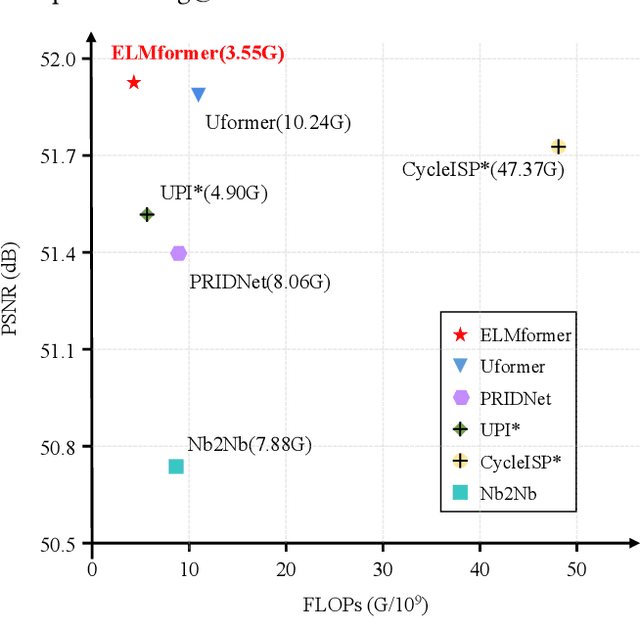
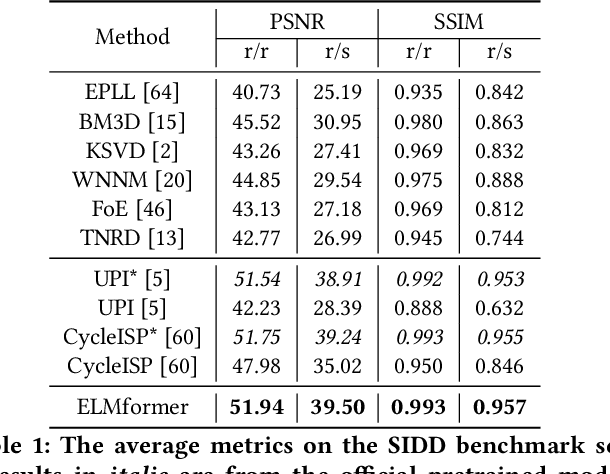
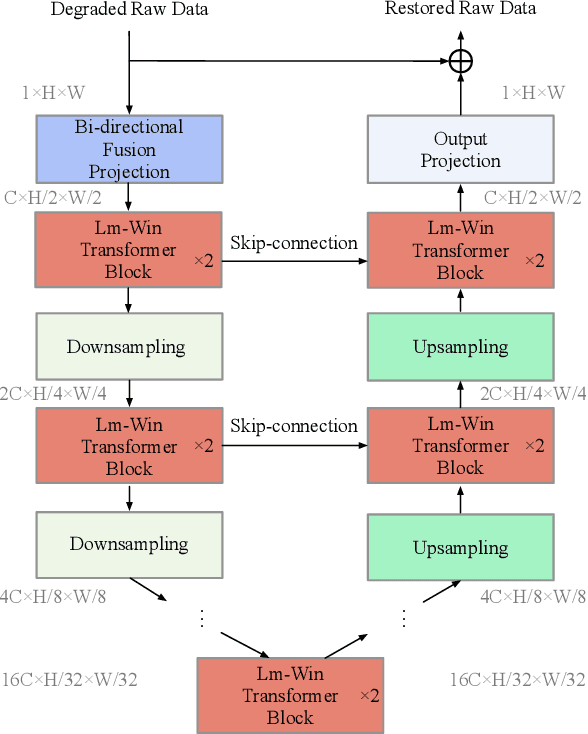
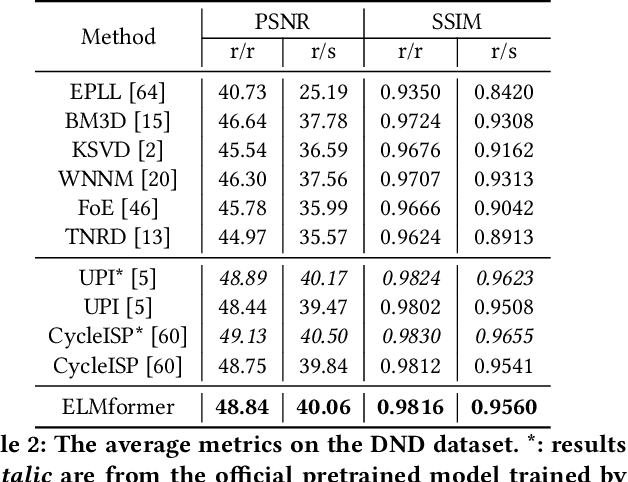
In order to get raw images of high quality for downstream Image Signal Process (ISP), in this paper we present an Efficient Locally Multiplicative Transformer called ELMformer for raw image restoration. ELMformer contains two core designs especially for raw images whose primitive attribute is single-channel. The first design is a Bi-directional Fusion Projection (BFP) module, where we consider both the color characteristics of raw images and spatial structure of single-channel. The second one is that we propose a Locally Multiplicative Self-Attention (L-MSA) scheme to effectively deliver information from the local space to relevant parts. ELMformer can efficiently reduce the computational consumption and perform well on raw image restoration tasks. Enhanced by these two core designs, ELMformer achieves the highest performance and keeps the lowest FLOPs on raw denoising and raw deblurring benchmarks compared with state-of-the-arts. Extensive experiments demonstrate the superiority and generalization ability of ELMformer. On SIDD benchmark, our method has even better denoising performance than ISP-based methods which need huge amount of additional sRGB training images. The codes are release at https://github.com/leonmakise/ELMformer.
Unsupervised ensemble-based phenotyping helps enhance the discoverability of genes related to heart morphology
Jan 07, 2023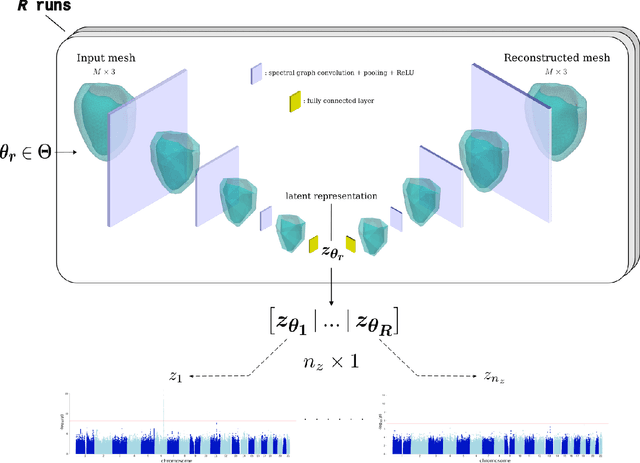
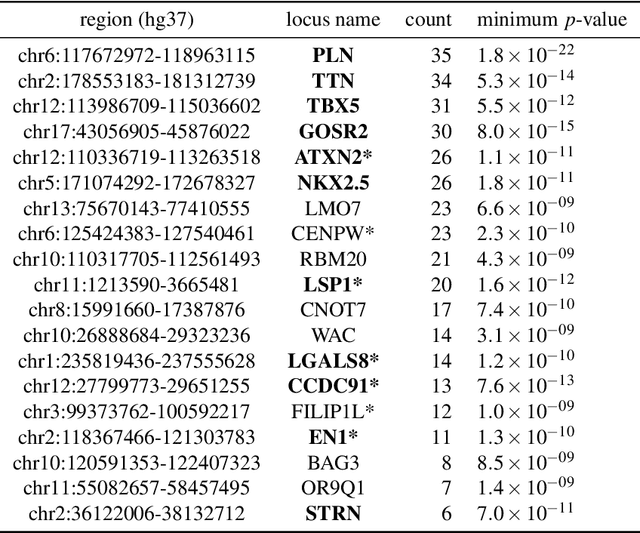
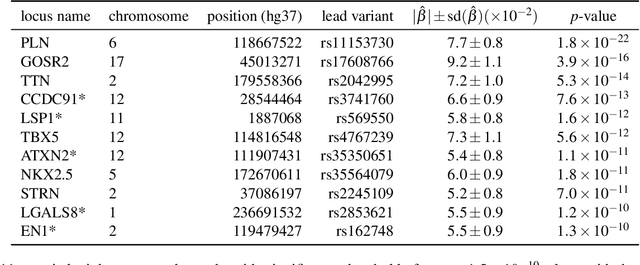
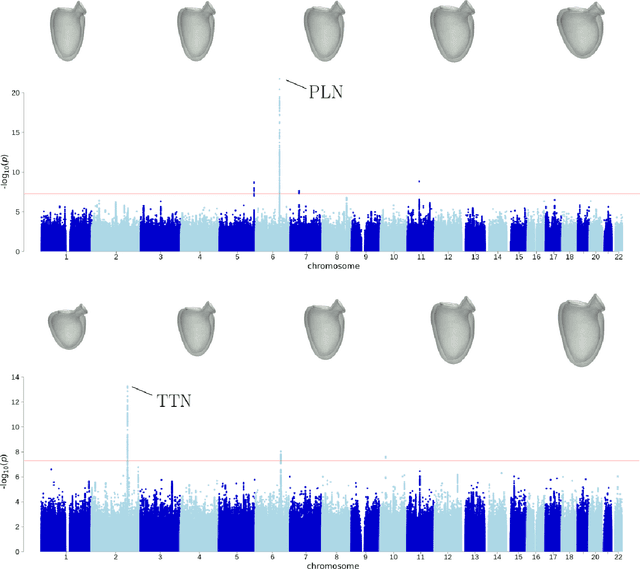
Recent genome-wide association studies (GWAS) have been successful in identifying associations between genetic variants and simple cardiac parameters derived from cardiac magnetic resonance (CMR) images. However, the emergence of big databases including genetic data linked to CMR, facilitates investigation of more nuanced patterns of shape variability. Here, we propose a new framework for gene discovery entitled Unsupervised Phenotype Ensembles (UPE). UPE builds a redundant yet highly expressive representation by pooling a set of phenotypes learned in an unsupervised manner, using deep learning models trained with different hyperparameters. These phenotypes are then analyzed via (GWAS), retaining only highly confident and stable associations across the ensemble. We apply our approach to the UK Biobank database to extract left-ventricular (LV) geometric features from image-derived three-dimensional meshes. We demonstrate that our approach greatly improves the discoverability of genes influencing LV shape, identifying 11 loci with study-wide significance and 8 with suggestive significance. We argue that our approach would enable more extensive discovery of gene associations with image-derived phenotypes for other organs or image modalities.
Learning Customized Visual Models with Retrieval-Augmented Knowledge
Jan 17, 2023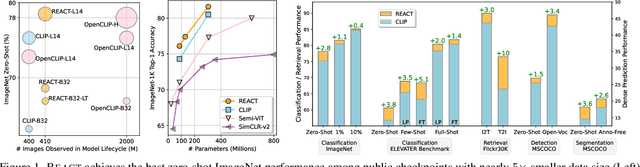
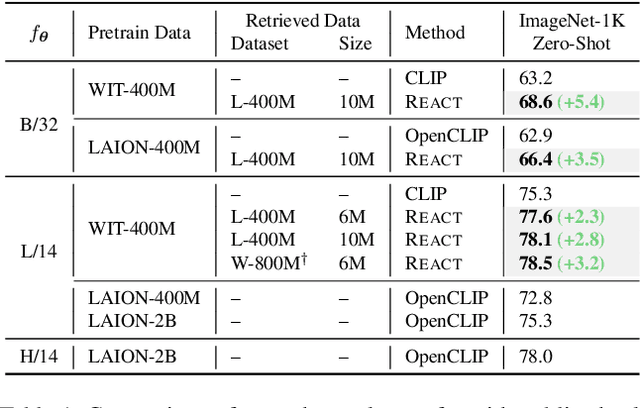
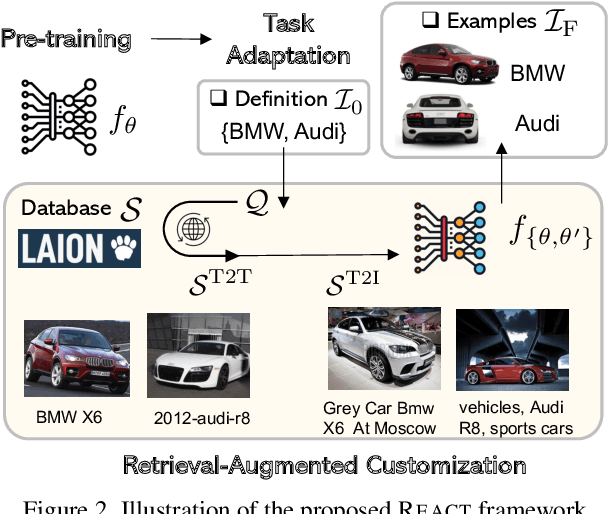
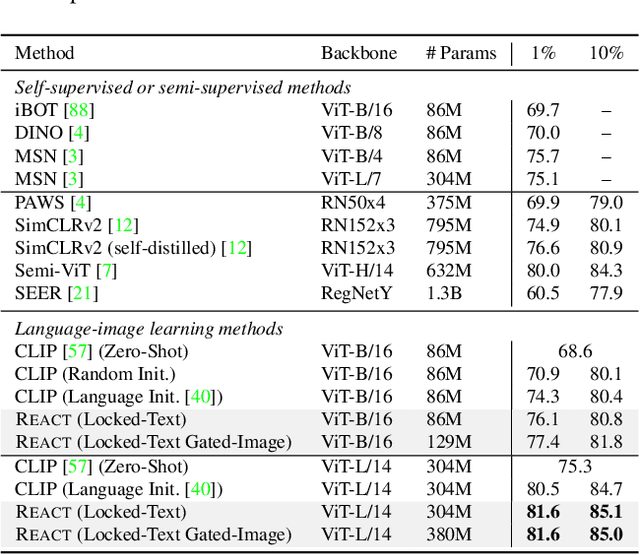
Image-text contrastive learning models such as CLIP have demonstrated strong task transfer ability. The high generality and usability of these visual models is achieved via a web-scale data collection process to ensure broad concept coverage, followed by expensive pre-training to feed all the knowledge into model weights. Alternatively, we propose REACT, REtrieval-Augmented CusTomization, a framework to acquire the relevant web knowledge to build customized visual models for target domains. We retrieve the most relevant image-text pairs (~3% of CLIP pre-training data) from the web-scale database as external knowledge, and propose to customize the model by only training new modualized blocks while freezing all the original weights. The effectiveness of REACT is demonstrated via extensive experiments on classification, retrieval, detection and segmentation tasks, including zero, few, and full-shot settings. Particularly, on the zero-shot classification task, compared with CLIP, it achieves up to 5.4% improvement on ImageNet and 3.7% on the ELEVATER benchmark (20 datasets).
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 15, 2023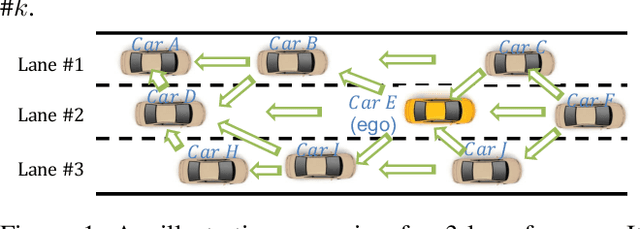

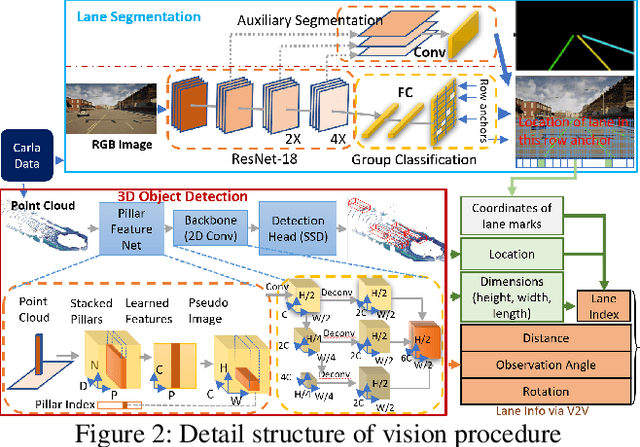
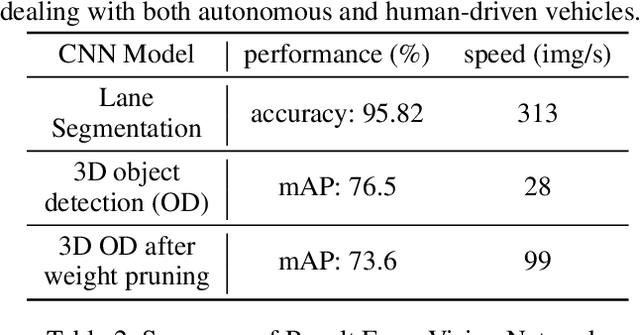
The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
Topological Neural Discrete Representation Learning à la Kohonen
Feb 15, 2023
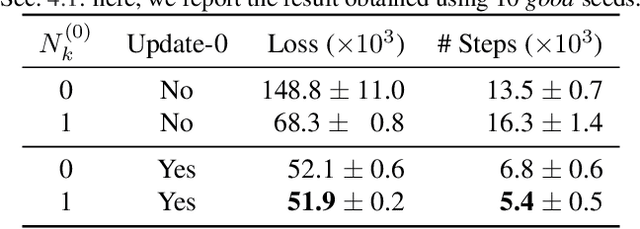
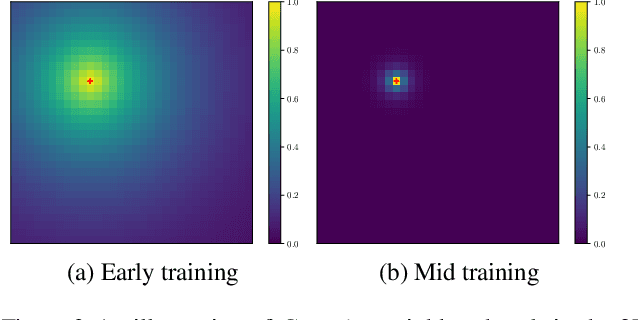

Unsupervised learning of discrete representations from continuous ones in neural networks (NNs) is the cornerstone of several applications today. Vector Quantisation (VQ) has become a popular method to achieve such representations, in particular in the context of generative models such as Variational Auto-Encoders (VAEs). For example, the exponential moving average-based VQ (EMA-VQ) algorithm is often used. Here we study an alternative VQ algorithm based on the learning rule of Kohonen Self-Organising Maps (KSOMs; 1982) of which EMA-VQ is a special case. In fact, KSOM is a classic VQ algorithm which is known to offer two potential benefits over the latter: empirically, KSOM is known to perform faster VQ, and discrete representations learned by KSOM form a topological structure on the grid whose nodes are the discrete symbols, resulting in an artificial version of the topographic map in the brain. We revisit these properties by using KSOM in VQ-VAEs for image processing. In particular, our experiments show that, while the speed-up compared to well-configured EMA-VQ is only observable at the beginning of training, KSOM is generally much more robust than EMA-VQ, e.g., w.r.t. the choice of initialisation schemes. Our code is public.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023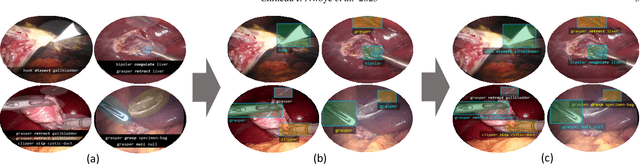
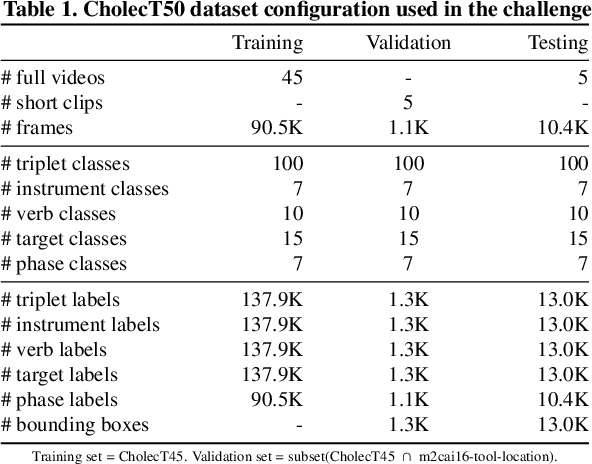
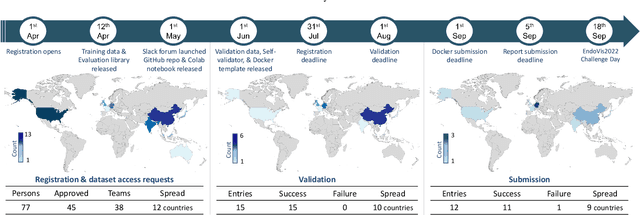
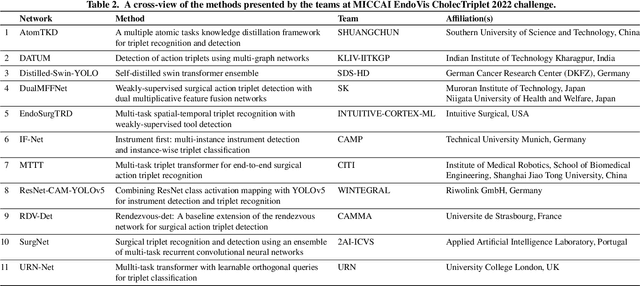
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
UniAdapter: Unified Parameter-Efficient Transfer Learning for Cross-modal Modeling
Feb 13, 2023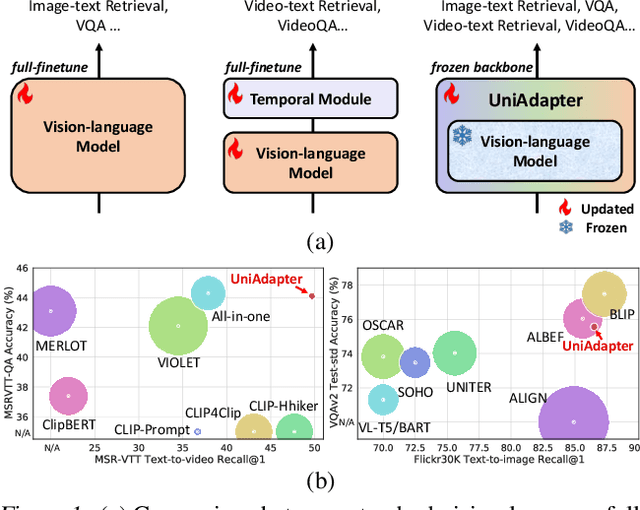
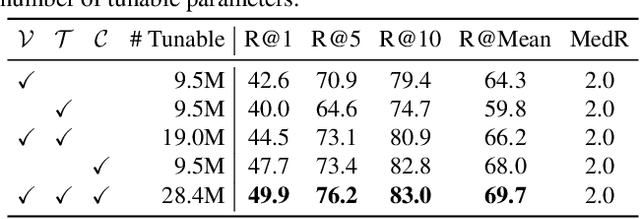
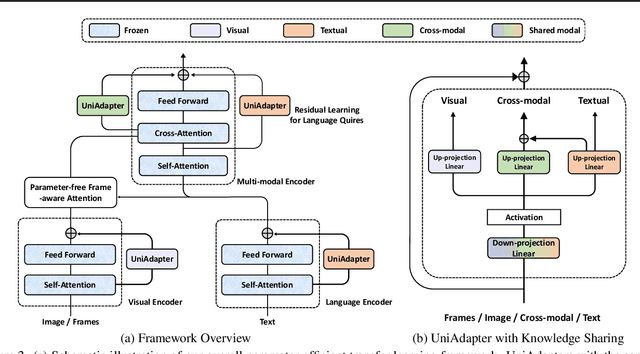
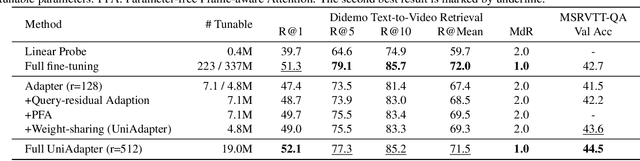
Large-scale vision-language pre-trained models have shown promising transferability to various downstream tasks. As the size of these foundation models and the number of downstream tasks grow, the standard full fine-tuning paradigm becomes unsustainable due to heavy computational and storage costs. This paper proposes UniAdapter, which unifies unimodal and multimodal adapters for parameter-efficient cross-modal adaptation on pre-trained vision-language models. Specifically, adapters are distributed to different modalities and their interactions, with the total number of tunable parameters reduced by partial weight sharing. The unified and knowledge-sharing design enables powerful cross-modal representations that can benefit various downstream tasks, requiring only 1.0%-2.0% tunable parameters of the pre-trained model. Extensive experiments on 6 cross-modal downstream benchmarks (including video-text retrieval, image-text retrieval, VideoQA, and VQA) show that in most cases, UniAdapter not only outperforms the state-of-the-arts, but even beats the full fine-tuning strategy. Particularly, on the MSRVTT retrieval task, UniAdapter achieves 49.7% recall@1 with 2.2% model parameters, outperforming the latest competitors by 2.0%. The code and models are available at https://github.com/RERV/UniAdapter.
Interpretable Multimodal Emotion Recognition using Hybrid Fusion of Speech and Image Data
Aug 25, 2022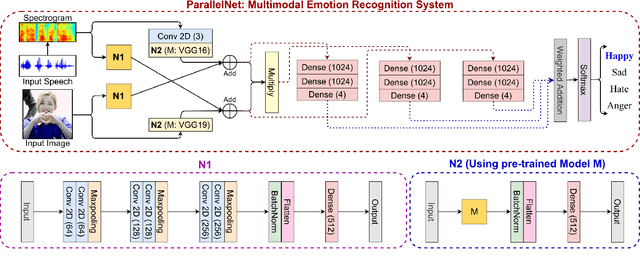
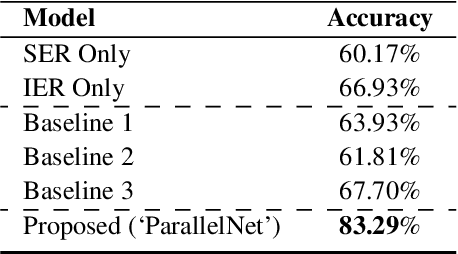
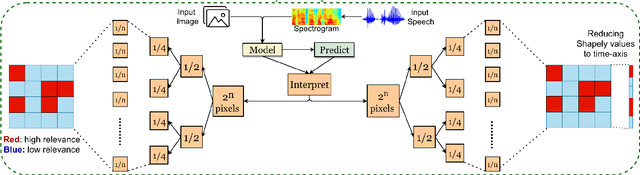

This paper proposes a multimodal emotion recognition system based on hybrid fusion that classifies the emotions depicted by speech utterances and corresponding images into discrete classes. A new interpretability technique has been developed to identify the important speech & image features leading to the prediction of particular emotion classes. The proposed system's architecture has been determined through intensive ablation studies. It fuses the speech & image features and then combines speech, image, and intermediate fusion outputs. The proposed interpretability technique incorporates the divide & conquer approach to compute shapely values denoting each speech & image feature's importance. We have also constructed a large-scale dataset (IIT-R SIER dataset), consisting of speech utterances, corresponding images, and class labels, i.e., 'anger,' 'happy,' 'hate,' and 'sad.' The proposed system has achieved 83.29% accuracy for emotion recognition. The enhanced performance of the proposed system advocates the importance of utilizing complementary information from multiple modalities for emotion recognition.