 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning Guided by Signal Temporal Logic Specifications
Jun 11, 2023



There has been growing interest in deep reinforcement learning (DRL) algorithm design, and reward design is one key component of DRL. Among the various techniques, formal methods integrated with DRL have garnered considerable attention due to their expressiveness and ability to define the requirements for the states and actions of the agent. However, the literature of Signal Temporal Logic (STL) in guiding multi-agent reinforcement learning (MARL) reward design remains limited. In this paper, we propose a novel STL-guided multi-agent reinforcement learning algorithm. The STL specifications are designed to include both task specifications according to the objective of each agent and safety specifications, and the robustness values of the STL specifications are leveraged to generate rewards. We validate the advantages of our method through empirical studies. The experimental results demonstrate significant performance improvements compared to MARL without STL guidance, along with a remarkable increase in the overall safety rate of the multi-agent systems.
Privacy-preserving and Uncertainty-aware Federated Trajectory Prediction for Connected Autonomous Vehicles
Mar 08, 2023Deep learning is the method of choice for trajectory prediction for autonomous vehicles. Unfortunately, its data-hungry nature implicitly requires the availability of sufficiently rich and high-quality centralized datasets, which easily leads to privacy leakage. Besides, uncertainty-awareness becomes increasingly important for safety-crucial cyber physical systems whose prediction module heavily relies on machine learning tools. In this paper, we relax the data collection requirement and enhance uncertainty-awareness by using Federated Learning on Connected Autonomous Vehicles with an uncertainty-aware global objective. We name our algorithm as FLTP. We further introduce ALFLTP which boosts FLTP via using active learning techniques in adaptatively selecting participating clients. We consider both negative log-likelihood (NLL) and aleatoric uncertainty (AU) as client selection metrics. Experiments on Argoverse dataset show that FLTP significantly outperforms the model trained on local data. In addition, ALFLTP-AU converges faster in training regression loss and performs better in terms of NLL, minADE and MR than FLTP in most rounds, and has more stable round-wise performance than ALFLTP-NLL.
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 15, 2023



The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
Spatial-Temporal-Aware Safe Multi-Agent Reinforcement Learning of Connected Autonomous Vehicles in Challenging Scenarios
Oct 05, 2022
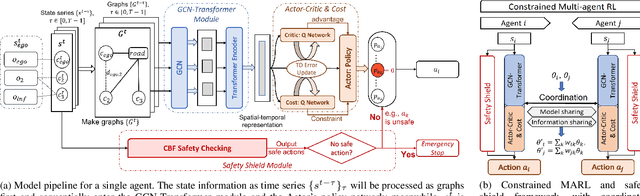
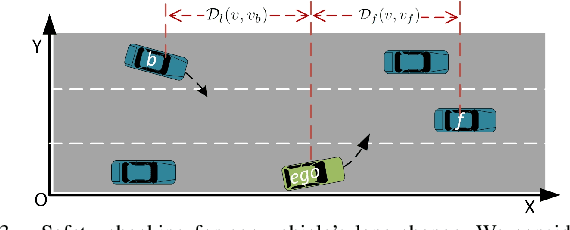

Communication technologies enable coordination among connected and autonomous vehicles (CAVs). However, it remains unclear how to utilize shared information to improve the safety and efficiency of the CAV system. In this work, we propose a framework of constrained multi-agent reinforcement learning (MARL) with a parallel safety shield for CAVs in challenging driving scenarios. The coordination mechanisms of the proposed MARL include information sharing and cooperative policy learning, with Graph Convolutional Network (GCN)-Transformer as a spatial-temporal encoder that enhances the agent's environment awareness. The safety shield module with Control Barrier Functions (CBF)-based safety checking protects the agents from taking unsafe actions. We design a constrained multi-agent advantage actor-critic (CMAA2C) algorithm to train safe and cooperative policies for CAVs. With the experiment deployed in the CARLA simulator, we verify the effectiveness of the safety checking, spatial-temporal encoder, and coordination mechanisms designed in our method by comparative experiments in several challenging scenarios with the defined hazard vehicles (HAZV). Results show that our proposed methodology significantly increases system safety and efficiency in challenging scenarios.