 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCam: Unified Novel View Synthesis via Structured Denoising Dynamics
May 13, 2026Generative novel view synthesis faces a fundamental dilemma: geometric priors provide spatial alignment but become sparse and inaccurate under view changes, while appearance priors offer visual fidelity but lack geometric correspondence. Existing methods either propagate geometric errors throughout generation or suffer from signal conflicts when fusing both statically. We introduce MoCam, which employs structured denoising dynamics to orchestrate a coordinated progression from geometry to appearance within the diffusion process. MoCam first leverages geometric priors in early stages to anchor coarse structures and tolerate their incompleteness, then switches to appearance priors in later stages to actively correct geometric errors and refine details. This design naturally unifies static and dynamic view synthesis by temporally decoupling geometric alignment and appearance refinement within the diffusion process. Experiments demonstrate that MoCam significantly outperforms prior methods, particularly when point clouds contain severe holes or distortions, achieving robust geometry-appearance disentanglement.
Minimizing Worst-Case Weighted Latency for Multi-Robot Persistent Monitoring: Theory and RL-Based Solutions
May 10, 2026We study multi-robot persistent monitoring on weighted graphs, where node weights encode monitoring priorities and edge weights encode travel distances. The goal is to design joint robot trajectories that minimize the worst-case weighted latency across all nodes over an infinite time horizon. The widely adopted worst-case latency objective evaluates team performance over the entire time horizon and therefore may fail to distinguish strategies with poor transient behavior but strong asymptotic performance. To address this limitation, we propose a family of tail-performance objectives that generalize the standard objective and study the resulting functional optimization problems. We establish several key theoretical properties, including the existence of optimal strategies, relationships among the proposed objectives and their corresponding optimization problems, approximation by periodic solutions to arbitrary accuracy, and reductions to event-driven decision models with discretized waiting times. Building on these results, we construct an equivalent event-driven Markov decision process (MDP), called the Tail Worst-case Latency-Optimizing Markov Decision Process (TWLO-MDP), which reformulates the tail-performance objective as a standard average-reward criterion. We then develop reinforcement-learning-based solution methods for the TWLO-MDP and introduce the multi-robot monitoring benchmark (M2Bench), a unified platform that supports the evaluation and comparison of heuristic and learning-based monitoring algorithms. Experiments on synthetic and realistic monitoring scenarios show that our methods effectively reduce the worst-case weighted latency and outperform representative baselines.
LSA: A Long-Short-term Aspect Interest Transformer for Aspect-Based Recommendation
Mar 22, 2026Aspect-based recommendation methods extract aspect terms from reviews, such as price, to model fine-grained user preferences on items, making them a critical approach in personalized recommender systems. Existing methods utilize graphs to represent the relationships among users, items, and aspect terms, modeling user preferences based on graph neural networks. However, they overlook the dynamic nature of user interests - users may temporarily focus on aspects they previously paid little attention to - making it difficult to assign accurate weights to aspect terms for each user-item interaction. In this paper, we propose a long-short-term aspect interest Transformer (LSA) for aspect-based recommendation, which effectively captures the dynamic nature of user preferences by integrating both long-term and short-term aspect interests. Specifically, the short-term interests model the temporal changes in the importance of recently interacted aspect terms, while the long-term interests consider global behavioral patterns, including aspects that users have not interacted with recently. Finally, LSA combines long- and short-term interests to evaluate the importance of aspects within the union of user and item aspect neighbors, therefore accurately assigns aspect weights for each user-item interaction. Experiments conducted on four real-world datasets demonstrate that LSA improves MSE by 2.55% on average over the best baseline.
VecGlypher: Unified Vector Glyph Generation with Language Models
Feb 25, 2026Vector glyphs are the atomic units of digital typography, yet most learning-based pipelines still depend on carefully curated exemplar sheets and raster-to-vector postprocessing, which limits accessibility and editability. We introduce VecGlypher, a single multimodal language model that generates high-fidelity vector glyphs directly from text descriptions or image exemplars. Given a style prompt, optional reference glyph images, and a target character, VecGlypher autoregressively emits SVG path tokens, avoiding raster intermediates and producing editable, watertight outlines in one pass. A typography-aware data and training recipe makes this possible: (i) a large-scale continuation stage on 39K noisy Envato fonts to master SVG syntax and long-horizon geometry, followed by (ii) post-training on 2.5K expert-annotated Google Fonts with descriptive tags and exemplars to align language and imagery with geometry; preprocessing normalizes coordinate frames, canonicalizes paths, de-duplicates families, and quantizes coordinates for stable long-sequence decoding. On cross-family OOD evaluation, VecGlypher substantially outperforms both general-purpose LLMs and specialized vector-font baselines for text-only generation, while image-referenced generation reaches a state-of-the-art performance, with marked gains over DeepVecFont-v2 and DualVector. Ablations show that model scale and the two-stage recipe are critical and that absolute-coordinate serialization yields the best geometry. VecGlypher lowers the barrier to font creation by letting users design with words or exemplars, and provides a scalable foundation for future multimodal design tools.
MoCha:End-to-End Video Character Replacement without Structural Guidance
Jan 14, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
End-to-End Video Character Replacement without Structural Guidance
Jan 13, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision
Jan 08, 2026While Unified Multimodal Models (UMMs) have achieved remarkable success in cross-modal comprehension, a significant gap persists in their ability to leverage such internal knowledge for high-quality generation. We formalize this discrepancy as Conduction Aphasia, a phenomenon where models accurately interpret multimodal inputs but struggle to translate that understanding into faithful and controllable synthesis. To address this, we propose UniCorn, a simple yet elegant self-improvement framework that eliminates the need for external data or teacher supervision. By partitioning a single UMM into three collaborative roles: Proposer, Solver, and Judge, UniCorn generates high-quality interactions via self-play and employs cognitive pattern reconstruction to distill latent understanding into explicit generative signals. To validate the restoration of multimodal coherence, we introduce UniCycle, a cycle-consistency benchmark based on a Text to Image to Text reconstruction loop. Extensive experiments demonstrate that UniCorn achieves comprehensive and substantial improvements over the base model across six general image generation benchmarks. Notably, it achieves SOTA performance on TIIF(73.8), DPG(86.8), CompBench(88.5), and UniCycle while further delivering substantial gains of +5.0 on WISE and +6.5 on OneIG. These results highlight that our method significantly enhances T2I generation while maintaining robust comprehension, demonstrating the scalability of fully self-supervised refinement for unified multimodal intelligence.
MARMOT: Masked Autoencoder for Modeling Transient Imaging
Jun 10, 2025
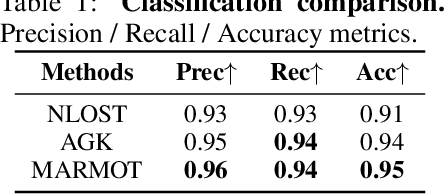


Pretrained models have demonstrated impressive success in many modalities such as language and vision. Recent works facilitate the pretraining paradigm in imaging research. Transients are a novel modality, which are captured for an object as photon counts versus arrival times using a precisely time-resolved sensor. In particular for non-line-of-sight (NLOS) scenarios, transients of hidden objects are measured beyond the sensor's direct line of sight. Using NLOS transients, the majority of previous works optimize volume density or surfaces to reconstruct the hidden objects and do not transfer priors learned from datasets. In this work, we present a masked autoencoder for modeling transient imaging, or MARMOT, to facilitate NLOS applications. Our MARMOT is a self-supervised model pretrianed on massive and diverse NLOS transient datasets. Using a Transformer-based encoder-decoder, MARMOT learns features from partially masked transients via a scanning pattern mask (SPM), where the unmasked subset is functionally equivalent to arbitrary sampling, and predicts full measurements. Pretrained on TransVerse-a synthesized transient dataset of 500K 3D models-MARMOT adapts to downstream imaging tasks using direct feature transfer or decoder finetuning. Comprehensive experiments are carried out in comparisons with state-of-the-art methods. Quantitative and qualitative results demonstrate the efficiency of our MARMOT.
TimeZero: Temporal Video Grounding with Reasoning-Guided LVLM
Mar 17, 2025We introduce TimeZero, a reasoning-guided LVLM designed for the temporal video grounding (TVG) task. This task requires precisely localizing relevant video segments within long videos based on a given language query. TimeZero tackles this challenge by extending the inference process, enabling the model to reason about video-language relationships solely through reinforcement learning. To evaluate the effectiveness of TimeZero, we conduct experiments on two benchmarks, where TimeZero achieves state-of-the-art performance on Charades-STA. Code is available at https://github.com/www-Ye/TimeZero.
TransiT: Transient Transformer for Non-line-of-sight Videography
Mar 14, 2025



High quality and high speed videography using Non-Line-of-Sight (NLOS) imaging benefit autonomous navigation, collision prevention, and post-disaster search and rescue tasks. Current solutions have to balance between the frame rate and image quality. High frame rates, for example, can be achieved by reducing either per-point scanning time or scanning density, but at the cost of lowering the information density at individual frames. Fast scanning process further reduces the signal-to-noise ratio and different scanning systems exhibit different distortion characteristics. In this work, we design and employ a new Transient Transformer architecture called TransiT to achieve real-time NLOS recovery under fast scans. TransiT directly compresses the temporal dimension of input transients to extract features, reducing computation costs and meeting high frame rate requirements. It further adopts a feature fusion mechanism as well as employs a spatial-temporal Transformer to help capture features of NLOS transient videos. Moreover, TransiT applies transfer learning to bridge the gap between synthetic and real-measured data. In real experiments, TransiT manages to reconstruct from sparse transients of $16 \times 16$ measured at an exposure time of 0.4 ms per point to NLOS videos at a $64 \times 64$ resolution at 10 frames per second. We will make our code and dataset available to the community.