 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Latent Graph Attention for Enhanced Spatial Context
Jul 12, 2023

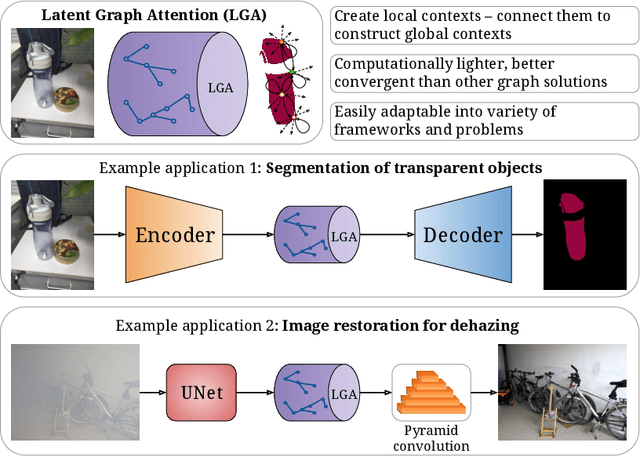
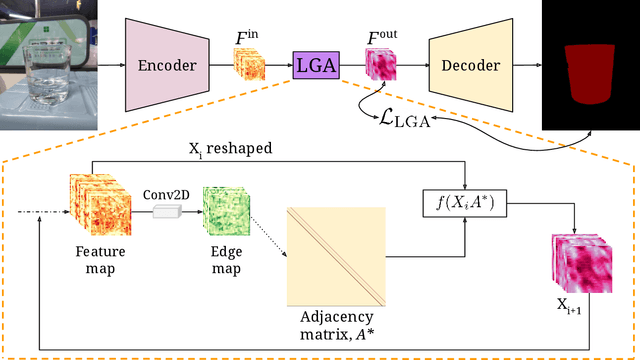
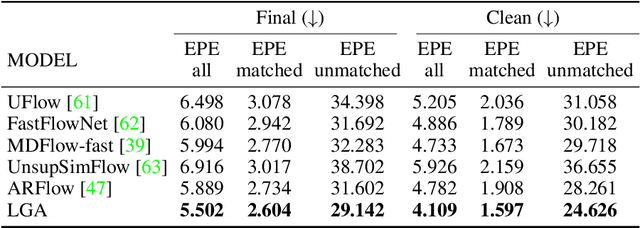
Global contexts in images are quite valuable in image-to-image translation problems. Conventional attention-based and graph-based models capture the global context to a large extent, however, these are computationally expensive. Moreover, the existing approaches are limited to only learning the pairwise semantic relation between any two points on the image. In this paper, we present Latent Graph Attention (LGA) a computationally inexpensive (linear to the number of nodes) and stable, modular framework for incorporating the global context in the existing architectures, especially empowering small-scale architectures to give performance closer to large size architectures, thus making the light-weight architectures more useful for edge devices with lower compute power and lower energy needs. LGA propagates information spatially using a network of locally connected graphs, thereby facilitating to construct a semantically coherent relation between any two spatially distant points that also takes into account the influence of the intermediate pixels. Moreover, the depth of the graph network can be used to adapt the extent of contextual spread to the target dataset, thereby being able to explicitly control the added computational cost. To enhance the learning mechanism of LGA, we also introduce a novel contrastive loss term that helps our LGA module to couple well with the original architecture at the expense of minimal additional computational load. We show that incorporating LGA improves the performance on three challenging applications, namely transparent object segmentation, image restoration for dehazing and optical flow estimation.
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Aug 02, 2023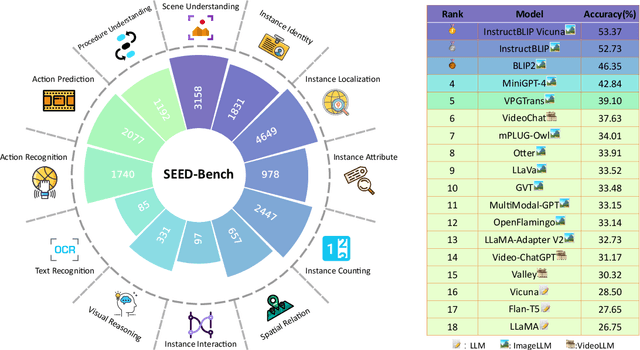

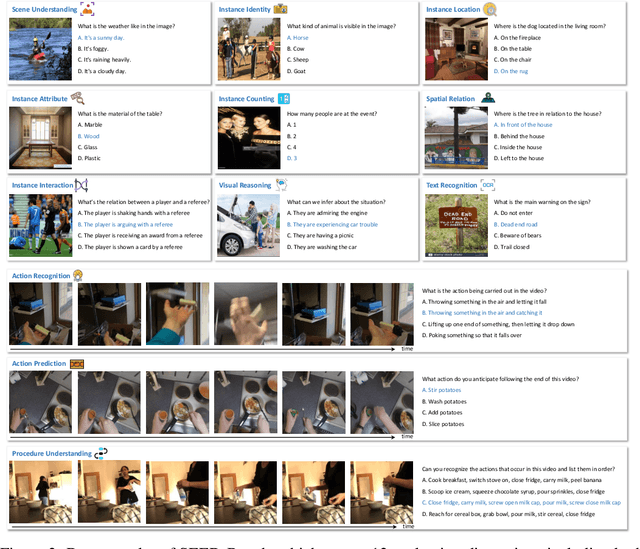
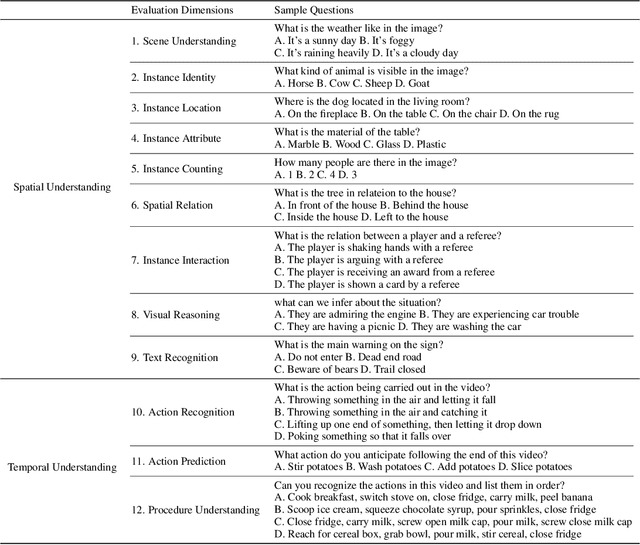
Based on powerful Large Language Models (LLMs), recent generative Multimodal Large Language Models (MLLMs) have gained prominence as a pivotal research area, exhibiting remarkable capability for both comprehension and generation. In this work, we address the evaluation of generative comprehension in MLLMs as a preliminary step towards a comprehensive assessment of generative models, by introducing a benchmark named SEED-Bench. SEED-Bench consists of 19K multiple choice questions with accurate human annotations (x 6 larger than existing benchmarks), which spans 12 evaluation dimensions including the comprehension of both the image and video modality. We develop an advanced pipeline for generating multiple-choice questions that target specific evaluation dimensions, integrating both automatic filtering and manual verification processes. Multiple-choice questions with groundtruth options derived from human annotation enables an objective and efficient assessment of model performance, eliminating the need for human or GPT intervention during evaluation. We further evaluate the performance of 18 models across all 12 dimensions, covering both the spatial and temporal understanding. By revealing the limitations of existing MLLMs through evaluation results, we aim for SEED-Bench to provide insights for motivating future research. We will launch and consistently maintain a leaderboard to provide a platform for the community to assess and investigate model capability.
Incorporating Season and Solar Specificity into Renderings made by a NeRF Architecture using Satellite Images
Aug 02, 2023As a result of Shadow NeRF and Sat-NeRF, it is possible to take the solar angle into account in a NeRF-based framework for rendering a scene from a novel viewpoint using satellite images for training. Our work extends those contributions and shows how one can make the renderings season-specific. Our main challenge was creating a Neural Radiance Field (NeRF) that could render seasonal features independently of viewing angle and solar angle while still being able to render shadows. We teach our network to render seasonal features by introducing one more input variable -- time of the year. However, the small training datasets typical of satellite imagery can introduce ambiguities in cases where shadows are present in the same location for every image of a particular season. We add additional terms to the loss function to discourage the network from using seasonal features for accounting for shadows. We show the performance of our network on eight Areas of Interest containing images captured by the Maxar WorldView-3 satellite. This evaluation includes tests measuring the ability of our framework to accurately render novel views, generate height maps, predict shadows, and specify seasonal features independently from shadows. Our ablation studies justify the choices made for network design parameters.
Push the Boundary of SAM: A Pseudo-label Correction Framework for Medical Segmentation
Aug 02, 2023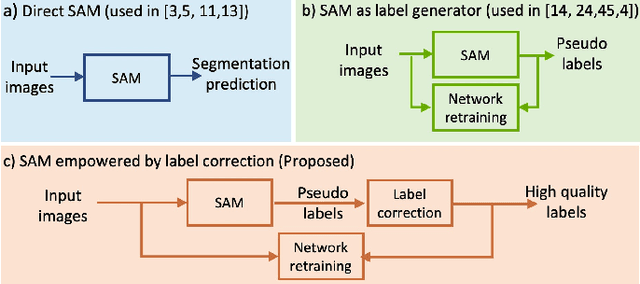
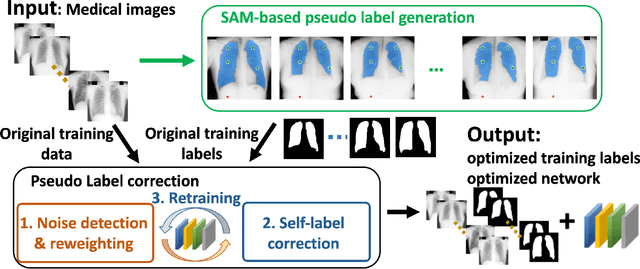
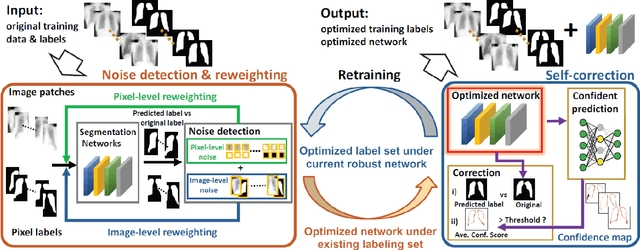
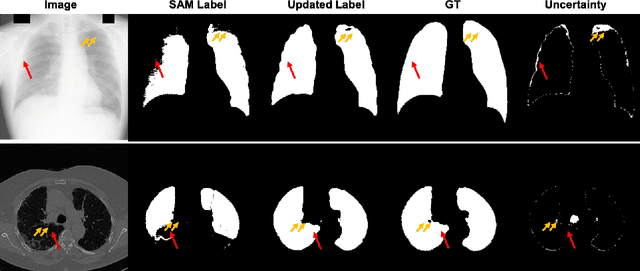
Segment anything model (SAM) has emerged as the leading approach for zero-shot learning in segmentation, offering the advantage of avoiding pixel-wise annotation. It is particularly appealing in medical image segmentation where annotation is laborious and expertise-demanding. However, the direct application of SAM often yields inferior results compared to conventional fully supervised segmentation networks. While using SAM generated pseudo label could also benefit the training of fully supervised segmentation, the performance is limited by the quality of pseudo labels. In this paper, we propose a novel label corruption to push the boundary of SAM-based segmentation. Our model utilizes a novel noise detection module to distinguish between noisy labels from clean labels. This enables us to correct the noisy labels using an uncertainty-based self-correction module, thereby enriching the clean training set. Finally, we retrain the network with updated labels to optimize its weights for future predictions. One key advantage of our model is its ability to train deep networks using SAM-generated pseudo labels without relying on a subset of expert-level annotations. We demonstrate the effectiveness of our proposed model on both X-ray and lung CT datasets, indicating its ability to improve segmentation accuracy and outperform baseline methods in label correction.
Dynamic Token Pruning in Plain Vision Transformers for Semantic Segmentation
Aug 02, 2023
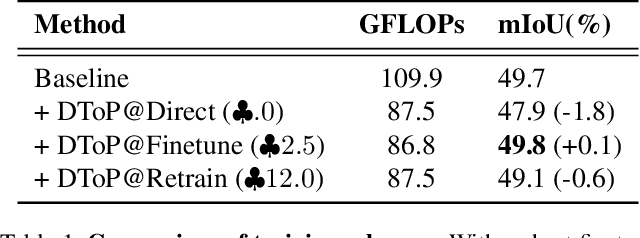
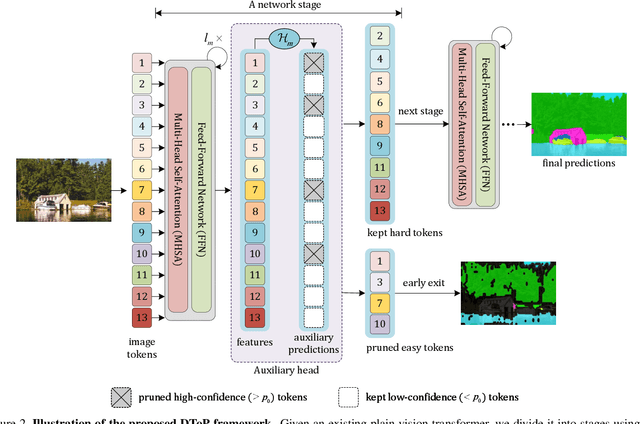
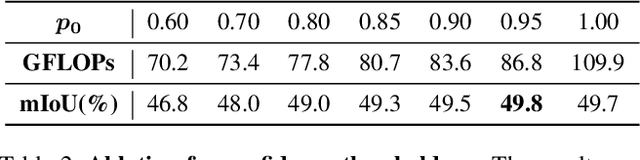
Vision transformers have achieved leading performance on various visual tasks yet still suffer from high computational complexity. The situation deteriorates in dense prediction tasks like semantic segmentation, as high-resolution inputs and outputs usually imply more tokens involved in computations. Directly removing the less attentive tokens has been discussed for the image classification task but can not be extended to semantic segmentation since a dense prediction is required for every patch. To this end, this work introduces a Dynamic Token Pruning (DToP) method based on the early exit of tokens for semantic segmentation. Motivated by the coarse-to-fine segmentation process by humans, we naturally split the widely adopted auxiliary-loss-based network architecture into several stages, where each auxiliary block grades every token's difficulty level. We can finalize the prediction of easy tokens in advance without completing the entire forward pass. Moreover, we keep $k$ highest confidence tokens for each semantic category to uphold the representative context information. Thus, computational complexity will change with the difficulty of the input, akin to the way humans do segmentation. Experiments suggest that the proposed DToP architecture reduces on average $20\% - 35\%$ of computational cost for current semantic segmentation methods based on plain vision transformers without accuracy degradation.
Domain Adaptation based Enhanced Detection for Autonomous Driving in Foggy and Rainy Weather
Jul 20, 2023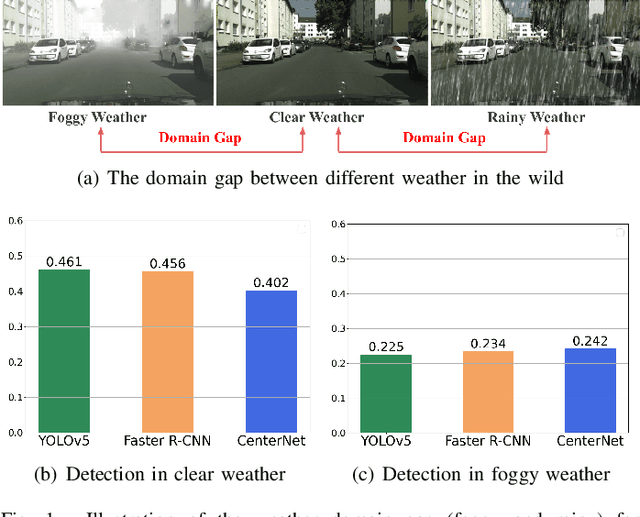
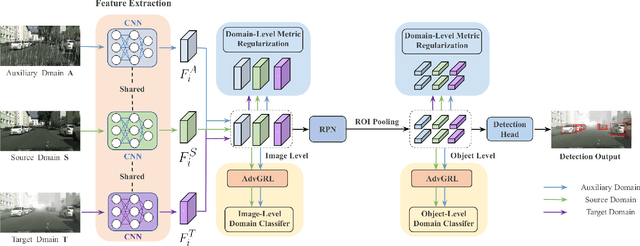
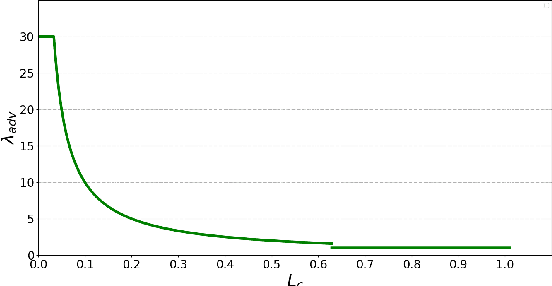

Typically, object detection methods for autonomous driving that rely on supervised learning make the assumption of a consistent feature distribution between the training and testing data, however such assumption may fail in different weather conditions. Due to the domain gap, a detection model trained under clear weather may not perform well in foggy and rainy conditions. Overcoming detection bottlenecks in foggy and rainy weather is a real challenge for autonomous vehicles deployed in the wild. To bridge the domain gap and improve the performance of object detectionin foggy and rainy weather, this paper presents a novel framework for domain-adaptive object detection. The adaptations at both the image-level and object-level are intended to minimize the differences in image style and object appearance between domains. Furthermore, in order to improve the model's performance on challenging examples, we introduce a novel adversarial gradient reversal layer that conducts adversarial mining on difficult instances in addition to domain adaptation. Additionally, we suggest generating an auxiliary domain through data augmentation to enforce a new domain-level metric regularization. Experimental findings on public V2V benchmark exhibit a substantial enhancement in object detection specifically for foggy and rainy driving scenarios.
EAML: Ensemble Self-Attention-based Mutual Learning Network for Document Image Classification
May 11, 2023In the recent past, complex deep neural networks have received huge interest in various document understanding tasks such as document image classification and document retrieval. As many document types have a distinct visual style, learning only visual features with deep CNNs to classify document images have encountered the problem of low inter-class discrimination, and high intra-class structural variations between its categories. In parallel, text-level understanding jointly learned with the corresponding visual properties within a given document image has considerably improved the classification performance in terms of accuracy. In this paper, we design a self-attention-based fusion module that serves as a block in our ensemble trainable network. It allows to simultaneously learn the discriminant features of image and text modalities throughout the training stage. Besides, we encourage mutual learning by transferring the positive knowledge between image and text modalities during the training stage. This constraint is realized by adding a truncated-Kullback-Leibler divergence loss Tr-KLD-Reg as a new regularization term, to the conventional supervised setting. To the best of our knowledge, this is the first time to leverage a mutual learning approach along with a self-attention-based fusion module to perform document image classification. The experimental results illustrate the effectiveness of our approach in terms of accuracy for the single-modal and multi-modal modalities. Thus, the proposed ensemble self-attention-based mutual learning model outperforms the state-of-the-art classification results based on the benchmark RVL-CDIP and Tobacco-3482 datasets.
Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
Apr 26, 2023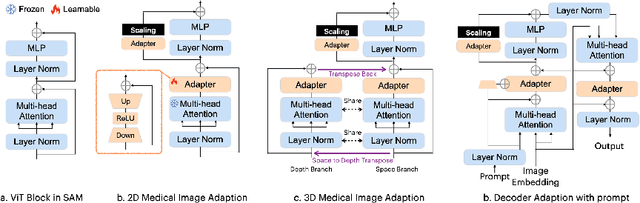
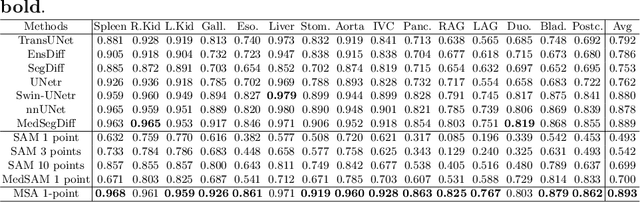
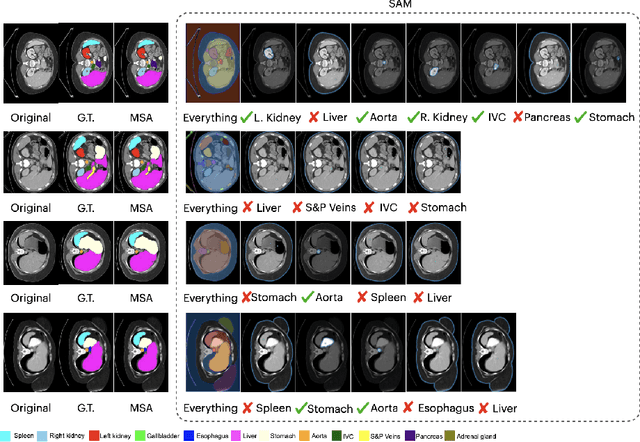
The Segment Anything Model (SAM) has recently gained popularity in the field of image segmentation. Thanks to its impressive capabilities in all-round segmentation tasks and its prompt-based interface, SAM has sparked intensive discussion within the community. It is even said by many prestigious experts that image segmentation task has been "finished" by SAM. However, medical image segmentation, although an important branch of the image segmentation family, seems not to be included in the scope of Segmenting "Anything". Many individual experiments and recent studies have shown that SAM performs subpar in medical image segmentation. A natural question is how to find the missing piece of the puzzle to extend the strong segmentation capability of SAM to medical image segmentation. In this paper, instead of fine-tuning the SAM model, we propose Med SAM Adapter, which integrates the medical specific domain knowledge to the segmentation model, by a simple yet effective adaptation technique. Although this work is still one of a few to transfer the popular NLP technique Adapter to computer vision cases, this simple implementation shows surprisingly good performance on medical image segmentation. A medical image adapted SAM, which we have dubbed Medical SAM Adapter (MSA), shows superior performance on 19 medical image segmentation tasks with various image modalities including CT, MRI, ultrasound image, fundus image, and dermoscopic images. MSA outperforms a wide range of state-of-the-art (SOTA) medical image segmentation methods, such as nnUNet, TransUNet, UNetr, MedSegDiff, and also outperforms the fully fine-turned MedSAM with a considerable performance gap. Code will be released at: https://github.com/WuJunde/Medical-SAM-Adapter.
Scale-aware Test-time Click Adaptation for Pulmonary Nodule and Mass Segmentation
Jul 28, 2023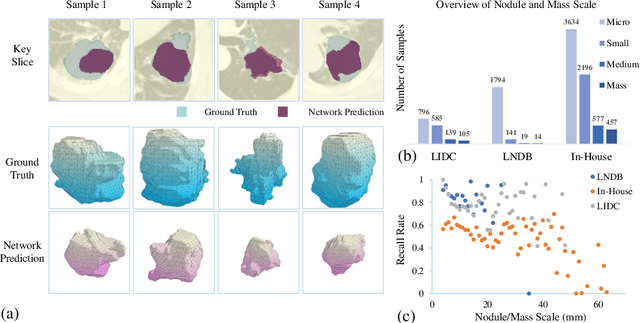
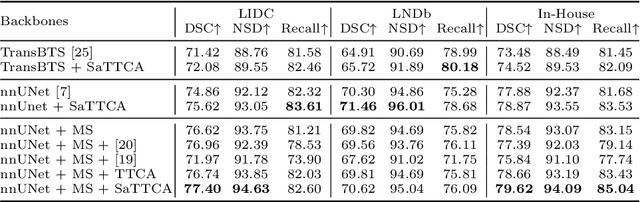
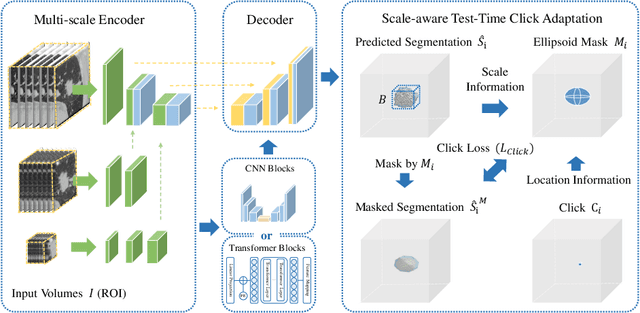
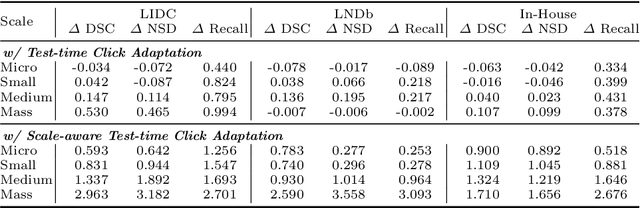
Pulmonary nodules and masses are crucial imaging features in lung cancer screening that require careful management in clinical diagnosis. Despite the success of deep learning-based medical image segmentation, the robust performance on various sizes of lesions of nodule and mass is still challenging. In this paper, we propose a multi-scale neural network with scale-aware test-time adaptation to address this challenge. Specifically, we introduce an adaptive Scale-aware Test-time Click Adaptation method based on effortlessly obtainable lesion clicks as test-time cues to enhance segmentation performance, particularly for large lesions. The proposed method can be seamlessly integrated into existing networks. Extensive experiments on both open-source and in-house datasets consistently demonstrate the effectiveness of the proposed method over some CNN and Transformer-based segmentation methods. Our code is available at https://github.com/SplinterLi/SaTTCA
Meta-Optimization for Higher Model Generalizability in Single-Image Depth Prediction
May 12, 2023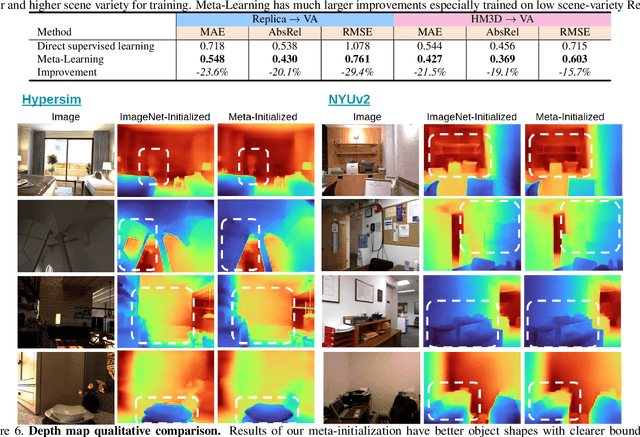
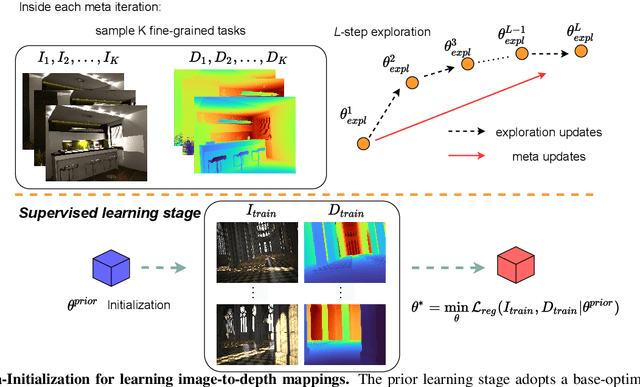
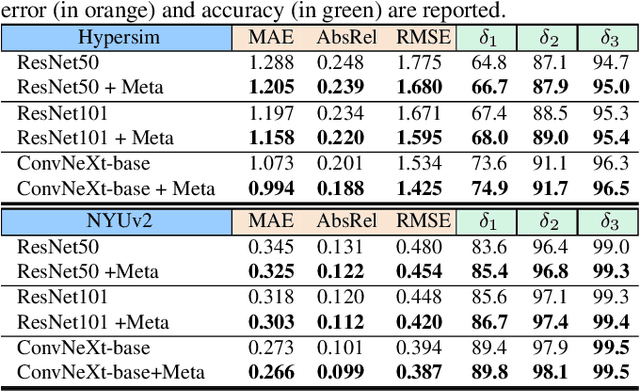
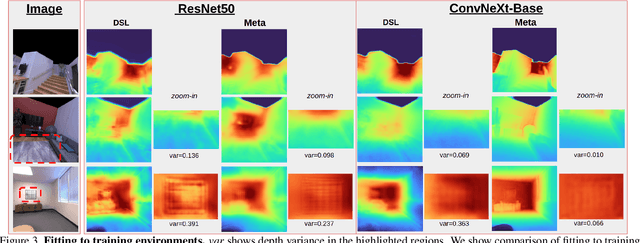
Model generalizability to unseen datasets, concerned with in-the-wild robustness, is less studied for indoor single-image depth prediction. We leverage gradient-based meta-learning for higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied image classification in meta-learning, depth is pixel-level continuous range values, and mappings from each image to depth vary widely across environments. Thus no explicit task boundaries exist. We instead propose fine-grained task that treats each RGB-D pair as a task in our meta-optimization. We first show meta-learning on limited data induces much better prior (max +29.4\%). Using meta-learned weights as initialization for following supervised learning, without involving extra data or information, it consistently outperforms baselines without the method. Compared to most indoor-depth methods that only train/ test on a single dataset, we propose zero-shot cross-dataset protocols, closely evaluate robustness, and show consistently higher generalizability and accuracy by our meta-initialization. The work at the intersection of depth and meta-learning potentially drives both research streams to step closer to practical use.