 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Graph Attention for Enhanced Spatial Context
Jul 12, 2023



Global contexts in images are quite valuable in image-to-image translation problems. Conventional attention-based and graph-based models capture the global context to a large extent, however, these are computationally expensive. Moreover, the existing approaches are limited to only learning the pairwise semantic relation between any two points on the image. In this paper, we present Latent Graph Attention (LGA) a computationally inexpensive (linear to the number of nodes) and stable, modular framework for incorporating the global context in the existing architectures, especially empowering small-scale architectures to give performance closer to large size architectures, thus making the light-weight architectures more useful for edge devices with lower compute power and lower energy needs. LGA propagates information spatially using a network of locally connected graphs, thereby facilitating to construct a semantically coherent relation between any two spatially distant points that also takes into account the influence of the intermediate pixels. Moreover, the depth of the graph network can be used to adapt the extent of contextual spread to the target dataset, thereby being able to explicitly control the added computational cost. To enhance the learning mechanism of LGA, we also introduce a novel contrastive loss term that helps our LGA module to couple well with the original architecture at the expense of minimal additional computational load. We show that incorporating LGA improves the performance on three challenging applications, namely transparent object segmentation, image restoration for dehazing and optical flow estimation.
Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective
Mar 10, 2023



Coreset selection is among the most effective ways to reduce the training time of CNNs, however, only limited is known on how the resultant models will behave under variations of the coreset size, and choice of datasets and models. Moreover, given the recent paradigm shift towards transformer-based models, it is still an open question how coreset selection would impact their performance. There are several similar intriguing questions that need to be answered for a wide acceptance of coreset selection methods, and this paper attempts to answer some of these. We present a systematic benchmarking setup and perform a rigorous comparison of different coreset selection methods on CNNs and transformers. Our investigation reveals that under certain circumstances, random selection of subsets is more robust and stable when compared with the SOTA selection methods. We demonstrate that the conventional concept of uniform subset sampling across the various classes of the data is not the appropriate choice. Rather samples should be adaptively chosen based on the complexity of the data distribution for each class. Transformers are generally pretrained on large datasets, and we show that for certain target datasets, it helps to keep their performance stable at even very small coreset sizes. We further show that when no pretraining is done or when the pretrained transformer models are used with non-natural images (e.g. medical data), CNNs tend to generalize better than transformers at even very small coreset sizes. Lastly, we demonstrate that in the absence of the right pretraining, CNNs are better at learning the semantic coherence between spatially distant objects within an image, and these tend to outperform transformers at almost all choices of the coreset size.
Patch Gradient Descent: Training Neural Networks on Very Large Images
Jan 31, 2023



Traditional CNN models are trained and tested on relatively low resolution images (<300 px), and cannot be directly operated on large-scale images due to compute and memory constraints. We propose Patch Gradient Descent (PatchGD), an effective learning strategy that allows to train the existing CNN architectures on large-scale images in an end-to-end manner. PatchGD is based on the hypothesis that instead of performing gradient-based updates on an entire image at once, it should be possible to achieve a good solution by performing model updates on only small parts of the image at a time, ensuring that the majority of it is covered over the course of iterations. PatchGD thus extensively enjoys better memory and compute efficiency when training models on large scale images. PatchGD is thoroughly evaluated on two datasets - PANDA and UltraMNIST with ResNet50 and MobileNetV2 models under different memory constraints. Our evaluation clearly shows that PatchGD is much more stable and efficient than the standard gradient-descent method in handling large images, and especially when the compute memory is limited.
On Using Deep Learning Proxies as Forward Models in Deep Learning Problems
Jan 16, 2023



Physics-based optimization problems are generally very time-consuming, especially due to the computational complexity associated with the forward model. Recent works have demonstrated that physics-modelling can be approximated with neural networks. However, there is always a certain degree of error associated with this learning, and we study this aspect in this paper. We demonstrate through experiments on popular mathematical benchmarks, that neural network approximations (NN-proxies) of such functions when plugged into the optimization framework, can lead to erroneous results. In particular, we study the behavior of particle swarm optimization and genetic algorithm methods and analyze their stability when coupled with NN-proxies. The correctness of the approximate model depends on the extent of sampling conducted in the parameter space, and through numerical experiments, we demonstrate that caution needs to be taken when constructing this landscape with neural networks. Further, the NN-proxies are hard to train for higher dimensional functions, and we present our insights for 4D and 10D problems. The error is higher for such cases, and we demonstrate that it is sensitive to the choice of the sampling scheme used to build the NN-proxy. The code is available at https://github.com/Fa-ti-ma/NN-proxy-in-optimization.
On designing light-weight object trackers through network pruning: Use CNNs or transformers?
Nov 24, 2022



Object trackers deployed on low-power devices need to be light-weight, however, most of the current state-of-the-art (SOTA) methods rely on using compute-heavy backbones built using CNNs or transformers. Large sizes of such models do not allow their deployment in low-power conditions and designing compressed variants of large tracking models is of great importance. This paper demonstrates how highly compressed light-weight object trackers can be designed using neural architectural pruning of large CNN and transformer based trackers. Further, a comparative study on architectural choices best suited to design light-weight trackers is provided. A comparison between SOTA trackers using CNNs, transformers as well as the combination of the two is presented to study their stability at various compression ratios. Finally results for extreme pruning scenarios going as low as 1% in some cases are shown to study the limits of network pruning in object tracking. This work provides deeper insights into designing highly efficient trackers from existing SOTA methods.
MixBin: Towards Budgeted Binarization
Nov 12, 2022



Binarization has proven to be amongst the most effective ways of neural network compression, reducing the FLOPs of the original model by a large extent. However, such levels of compression are often accompanied by a significant drop in the performance. There exist some approaches that reduce this performance drop by facilitating partial binarization of the network, however, a systematic approach to mix binary and full-precision parameters in a single network is still missing. In this paper, we propose a paradigm to perform partial binarization of neural networks in a controlled sense, thereby constructing budgeted binary neural network (B2NN). We present MixBin, an iterative search-based strategy that constructs B2NN through optimized mixing of the binary and full-precision components. MixBin allows to explicitly choose the approximate fraction of the network to be kept as binary, thereby presenting the flexibility to adapt the inference cost at a prescribed budget. We demonstrate through experiments that B2NNs obtained from our MixBin strategy are significantly better than those obtained from random selection of the network layers. To perform partial binarization in an effective manner, it is important that both the full-precision as well as the binary components of the B2NN are appropriately optimized. We also demonstrate that the choice of the activation function can have a significant effect on this process, and to circumvent this issue, we present BinReLU, that can be used as an effective activation function for the full-precision as well as the binary components of any B2NN. Experimental investigations reveal that BinReLU outperforms the other activation functions in all possible scenarios of B2NN: zero-, partial- as well as full binarization. Finally, we demonstrate the efficacy of MixBin on the tasks of classification and object tracking using benchmark datasets.
UltraMNIST Classification: A Benchmark to Train CNNs for Very Large Images
Jun 25, 2022
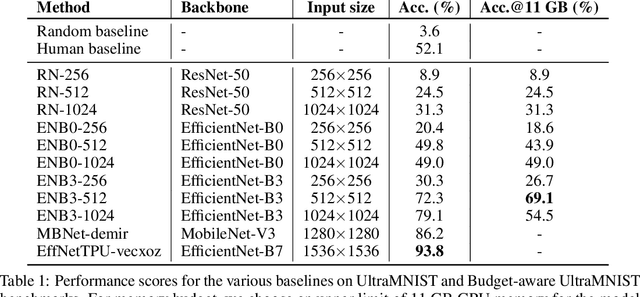

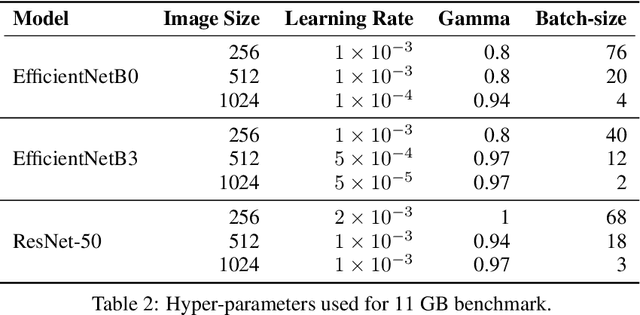
Convolutional neural network (CNN) approaches available in the current literature are designed to work primarily with low-resolution images. When applied on very large images, challenges related to GPU memory, smaller receptive field than needed for semantic correspondence and the need to incorporate multi-scale features arise. The resolution of input images can be reduced, however, with significant loss of critical information. Based on the outlined issues, we introduce a novel research problem of training CNN models for very large images, and present 'UltraMNIST dataset', a simple yet representative benchmark dataset for this task. UltraMNIST has been designed using the popular MNIST digits with additional levels of complexity added to replicate well the challenges of real-world problems. We present two variants of the problem: 'UltraMNIST classification' and 'Budget-aware UltraMNIST classification'. The standard UltraMNIST classification benchmark is intended to facilitate the development of novel CNN training methods that make the effective use of the best available GPU resources. The budget-aware variant is intended to promote development of methods that work under constrained GPU memory. For the development of competitive solutions, we present several baseline models for the standard benchmark and its budget-aware variant. We study the effect of reducing resolution on the performance and present results for baseline models involving pretrained backbones from among the popular state-of-the-art models. Finally, with the presented benchmark dataset and the baselines, we hope to pave the ground for a new generation of CNN methods suitable for handling large images in an efficient and resource-light manner.
Dynamic Kernel Selection for Improved Generalization and Memory Efficiency in Meta-learning
Jun 03, 2022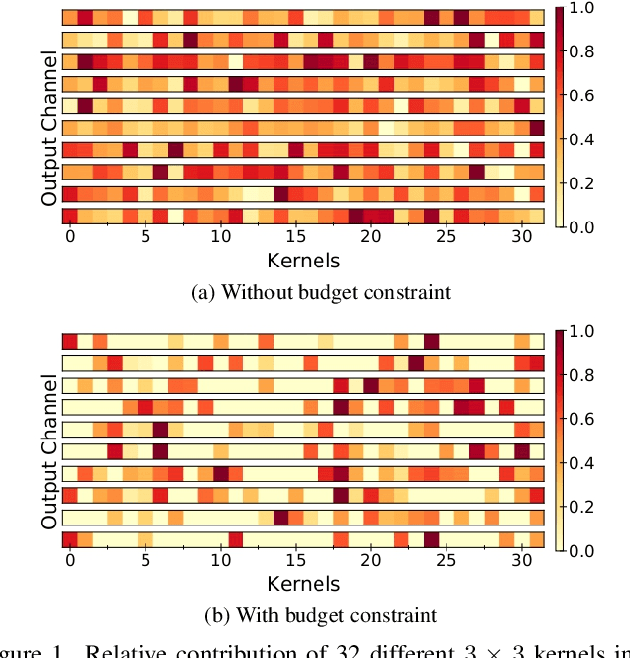
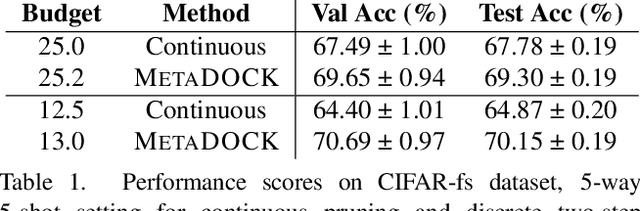
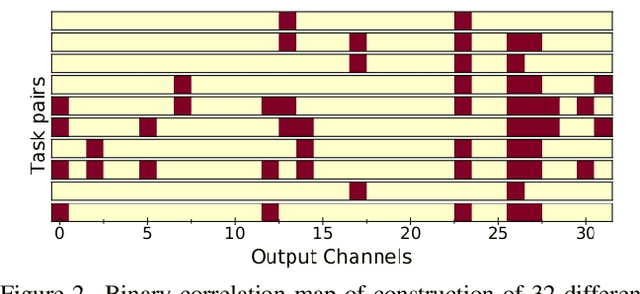
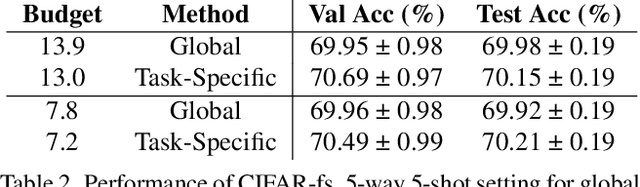
Gradient based meta-learning methods are prone to overfit on the meta-training set, and this behaviour is more prominent with large and complex networks. Moreover, large networks restrict the application of meta-learning models on low-power edge devices. While choosing smaller networks avoid these issues to a certain extent, it affects the overall generalization leading to reduced performance. Clearly, there is an approximately optimal choice of network architecture that is best suited for every meta-learning problem, however, identifying it beforehand is not straightforward. In this paper, we present MetaDOCK, a task-specific dynamic kernel selection strategy for designing compressed CNN models that generalize well on unseen tasks in meta-learning. Our method is based on the hypothesis that for a given set of similar tasks, not all kernels of the network are needed by each individual task. Rather, each task uses only a fraction of the kernels, and the selection of the kernels per task can be learnt dynamically as a part of the inner update steps. MetaDOCK compresses the meta-model as well as the task-specific inner models, thus providing significant reduction in model size for each task, and through constraining the number of active kernels for every task, it implicitly mitigates the issue of meta-overfitting. We show that for the same inference budget, pruned versions of large CNN models obtained using our approach consistently outperform the conventional choices of CNN models. MetaDOCK couples well with popular meta-learning approaches such as iMAML. The efficacy of our method is validated on CIFAR-fs and mini-ImageNet datasets, and we have observed that our approach can provide improvements in model accuracy of up to 2% on standard meta-learning benchmark, while reducing the model size by more than 75%.
Implicit Equivariance in Convolutional Networks
Nov 28, 2021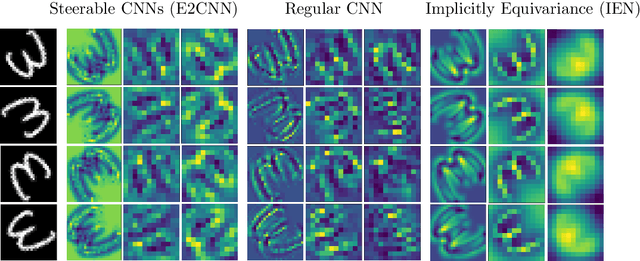
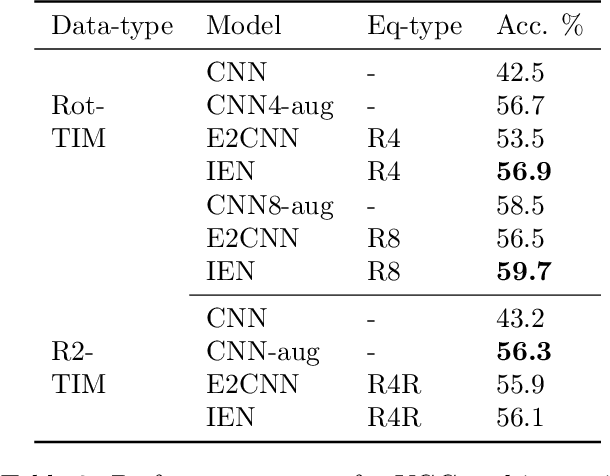
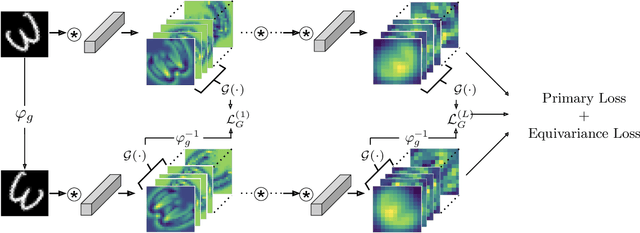
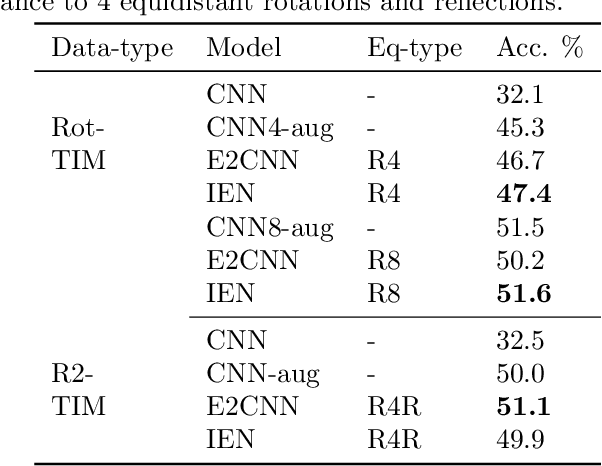
Convolutional Neural Networks(CNN) are inherently equivariant under translations, however, they do not have an equivalent embedded mechanism to handle other transformations such as rotations and change in scale. Several approaches exist that make CNNs equivariant under other transformation groups by design. Among these, steerable CNNs have been especially effective. However, these approaches require redesigning standard networks with filters mapped from combinations of predefined basis involving complex analytical functions. We experimentally demonstrate that these restrictions in the choice of basis can lead to model weights that are sub-optimal for the primary deep learning task (e.g. classification). Moreover, such hard-baked explicit formulations make it difficult to design composite networks comprising heterogeneous feature groups. To circumvent such issues, we propose Implicitly Equivariant Networks (IEN) which induce equivariance in the different layers of a standard CNN model by optimizing a multi-objective loss function that combines the primary loss with an equivariance loss term. Through experiments with VGG and ResNet models on Rot-MNIST , Rot-TinyImageNet, Scale-MNIST and STL-10 datasets, we show that IEN, even with its simple formulation, performs better than steerable networks. Also, IEN facilitates construction of heterogeneous filter groups allowing reduction in number of channels in CNNs by a factor of over 30% while maintaining performance on par with baselines. The efficacy of IEN is further validated on the hard problem of visual object tracking. We show that IEN outperforms the state-of-the-art rotation equivariant tracking method while providing faster inference speed.
Livestock Monitoring with Transformer
Nov 02, 2021

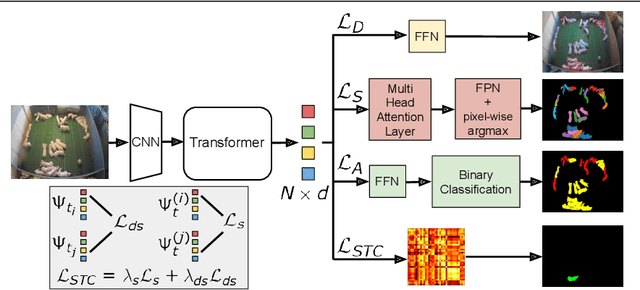
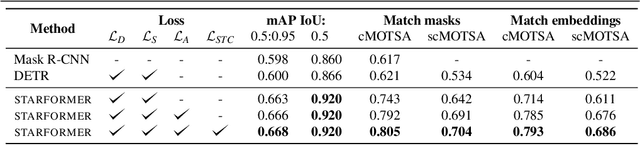
Tracking the behaviour of livestock enables early detection and thus prevention of contagious diseases in modern animal farms. Apart from economic gains, this would reduce the amount of antibiotics used in livestock farming which otherwise enters the human diet exasperating the epidemic of antibiotic resistance - a leading cause of death. We could use standard video cameras, available in most modern farms, to monitor livestock. However, most computer vision algorithms perform poorly on this task, primarily because, (i) animals bred in farms look identical, lacking any obvious spatial signature, (ii) none of the existing trackers are robust for long duration, and (iii) real-world conditions such as changing illumination, frequent occlusion, varying camera angles, and sizes of the animals make it hard for models to generalize. Given these challenges, we develop an end-to-end behaviour monitoring system for group-housed pigs to perform simultaneous instance level segmentation, tracking, action recognition and re-identification (STAR) tasks. We present starformer, the first end-to-end multiple-object livestock monitoring framework that learns instance-level embeddings for grouped pigs through the use of transformer architecture. For benchmarking, we present Pigtrace, a carefully curated dataset comprising video sequences with instance level bounding box, segmentation, tracking and activity classification of pigs in real indoor farming environment. Using simultaneous optimization on STAR tasks we show that starformer outperforms popular baseline models trained for individual tasks.