 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocSum: Domain-Adaptive Pre-training for Document Abstractive Summarization
Dec 11, 2024Abstractive summarization has made significant strides in condensing and rephrasing large volumes of text into coherent summaries. However, summarizing administrative documents presents unique challenges due to domain-specific terminology, OCR-generated errors, and the scarcity of annotated datasets for model fine-tuning. Existing models often struggle to adapt to the intricate structure and specialized content of such documents. To address these limitations, we introduce DocSum, a domain-adaptive abstractive summarization framework tailored for administrative documents. Leveraging pre-training on OCR-transcribed text and fine-tuning with an innovative integration of question-answer pairs, DocSum enhances summary accuracy and relevance. This approach tackles the complexities inherent in administrative content, ensuring outputs that align with real-world business needs. To evaluate its capabilities, we define a novel downstream task setting-Document Abstractive Summarization-which reflects the practical requirements of business and organizational settings. Comprehensive experiments demonstrate DocSum's effectiveness in producing high-quality summaries, showcasing its potential to improve decision-making and operational workflows across the public and private sectors.
KhmerST: A Low-Resource Khmer Scene Text Detection and Recognition Benchmark
Oct 23, 2024



Developing effective scene text detection and recognition models hinges on extensive training data, which can be both laborious and costly to obtain, especially for low-resourced languages. Conventional methods tailored for Latin characters often falter with non-Latin scripts due to challenges like character stacking, diacritics, and variable character widths without clear word boundaries. In this paper, we introduce the first Khmer scene-text dataset, featuring 1,544 expert-annotated images, including 997 indoor and 547 outdoor scenes. This diverse dataset includes flat text, raised text, poorly illuminated text, distant and partially obscured text. Annotations provide line-level text and polygonal bounding box coordinates for each scene. The benchmark includes baseline models for scene-text detection and recognition tasks, providing a robust starting point for future research endeavors. The KhmerST dataset is publicly accessible at https://gitlab.com/vannkinhnom123/khmerst.
Multimodal Adaptive Inference for Document Image Classification with Anytime Early Exiting
May 21, 2024This work addresses the need for a balanced approach between performance and efficiency in scalable production environments for visually-rich document understanding (VDU) tasks. Currently, there is a reliance on large document foundation models that offer advanced capabilities but come with a heavy computational burden. In this paper, we propose a multimodal early exit (EE) model design that incorporates various training strategies, exit layer types and placements. Our goal is to achieve a Pareto-optimal balance between predictive performance and efficiency for multimodal document image classification. Through a comprehensive set of experiments, we compare our approach with traditional exit policies and showcase an improved performance-efficiency trade-off. Our multimodal EE design preserves the model's predictive capabilities, enhancing both speed and latency. This is achieved through a reduction of over 20% in latency, while fully retaining the baseline accuracy. This research represents the first exploration of multimodal EE design within the VDU community, highlighting as well the effectiveness of calibration in improving confidence scores for exiting at different layers. Overall, our findings contribute to practical VDU applications by enhancing both performance and efficiency.
IDTrust: Deep Identity Document Quality Detection with Bandpass Filtering
Mar 01, 2024



The increasing use of digital technologies and mobile-based registration procedures highlights the vital role of personal identity documents (IDs) in verifying users and safeguarding sensitive information. However, the rise in counterfeit ID production poses a significant challenge, necessitating the development of reliable and efficient automated verification methods. This paper introduces IDTrust, a deep-learning framework for assessing the quality of IDs. IDTrust is a system that enhances the quality of identification documents by using a deep learning-based approach. This method eliminates the need for relying on original document patterns for quality checks and pre-processing steps for alignment. As a result, it offers significant improvements in terms of dataset applicability. By utilizing a bandpass filtering-based method, the system aims to effectively detect and differentiate ID quality. Comprehensive experiments on the MIDV-2020 and L3i-ID datasets identify optimal parameters, significantly improving discrimination performance and effectively distinguishing between original and scanned ID documents.
TransferDoc: A Self-Supervised Transferable Document Representation Learning Model Unifying Vision and Language
Sep 11, 2023



The field of visual document understanding has witnessed a rapid growth in emerging challenges and powerful multi-modal strategies. However, they rely on an extensive amount of document data to learn their pretext objectives in a ``pre-train-then-fine-tune'' paradigm and thus, suffer a significant performance drop in real-world online industrial settings. One major reason is the over-reliance on OCR engines to extract local positional information within a document page. Therefore, this hinders the model's generalizability, flexibility and robustness due to the lack of capturing global information within a document image. We introduce TransferDoc, a cross-modal transformer-based architecture pre-trained in a self-supervised fashion using three novel pretext objectives. TransferDoc learns richer semantic concepts by unifying language and visual representations, which enables the production of more transferable models. Besides, two novel downstream tasks have been introduced for a ``closer-to-real'' industrial evaluation scenario where TransferDoc outperforms other state-of-the-art approaches.
EAML: Ensemble Self-Attention-based Mutual Learning Network for Document Image Classification
May 11, 2023In the recent past, complex deep neural networks have received huge interest in various document understanding tasks such as document image classification and document retrieval. As many document types have a distinct visual style, learning only visual features with deep CNNs to classify document images have encountered the problem of low inter-class discrimination, and high intra-class structural variations between its categories. In parallel, text-level understanding jointly learned with the corresponding visual properties within a given document image has considerably improved the classification performance in terms of accuracy. In this paper, we design a self-attention-based fusion module that serves as a block in our ensemble trainable network. It allows to simultaneously learn the discriminant features of image and text modalities throughout the training stage. Besides, we encourage mutual learning by transferring the positive knowledge between image and text modalities during the training stage. This constraint is realized by adding a truncated-Kullback-Leibler divergence loss Tr-KLD-Reg as a new regularization term, to the conventional supervised setting. To the best of our knowledge, this is the first time to leverage a mutual learning approach along with a self-attention-based fusion module to perform document image classification. The experimental results illustrate the effectiveness of our approach in terms of accuracy for the single-modal and multi-modal modalities. Thus, the proposed ensemble self-attention-based mutual learning model outperforms the state-of-the-art classification results based on the benchmark RVL-CDIP and Tobacco-3482 datasets.
VLCDoC: Vision-Language Contrastive Pre-Training Model for Cross-Modal Document Classification
May 24, 2022
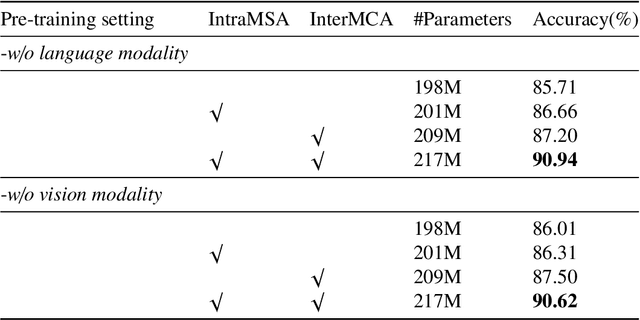
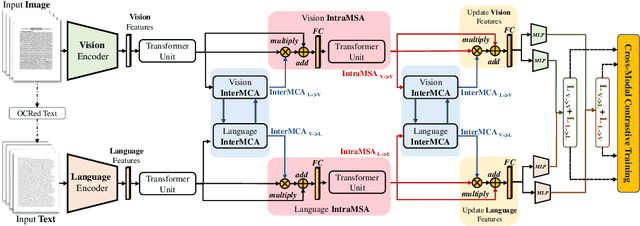
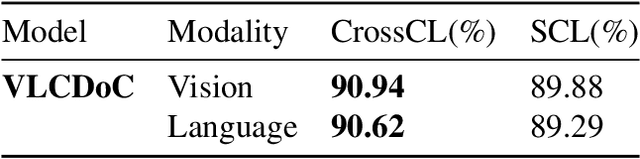
Multimodal learning from document data has achieved great success lately as it allows to pre-train semantically meaningful features as a prior into a learnable downstream approach. In this paper, we approach the document classification problem by learning cross-modal representations through language and vision cues, considering intra- and inter-modality relationships. Instead of merging features from different modalities into a common representation space, the proposed method exploits high-level interactions and learns relevant semantic information from effective attention flows within and across modalities. The proposed learning objective is devised between intra- and inter-modality alignment tasks, where the similarity distribution per task is computed by contracting positive sample pairs while simultaneously contrasting negative ones in the common feature representation space}. Extensive experiments on public document classification datasets demonstrate the effectiveness and the generalization capacity of our model on both low-scale and large-scale datasets.
Face Detection in Camera Captured Images of Identity Documents under Challenging Conditions
Nov 08, 2019
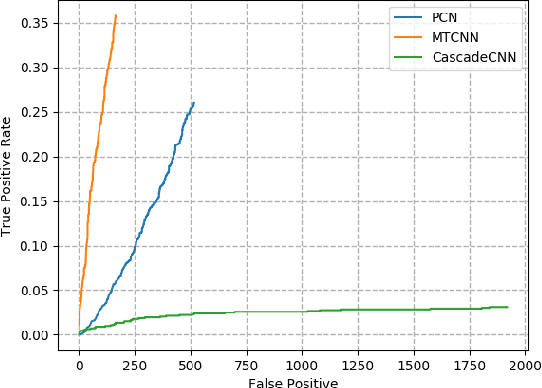


Benefiting from the advance of deep convolutional neural network approaches (CNNs), many face detection algorithms have achieved state-of-the-art performance in terms of accuracy and very high speed in unconstrained applications. However, due to the lack of public datasets and due to the variation of the orientation of face images, the complex background and lighting, defocus and the varying illumination of camera captured images, face detection on identity documents under unconstrained environments has not been sufficiently studied. To address this problem more efficiently, we survey three state-of-the-art face detection methods based on general images, i.e. Cascade-CNN, MTCNN and PCN, for face detection in camera captured images of identity documents, given different image quality assessments. For that, The MIDV-500 dataset, which is the largest and most challenging dataset for identity documents, is used to evaluate the three methods. The evaluation results show the performance and the limitations of the current methods for face detection on identity documents under the wild complex environments. These results show that the face detection task in camera captured images of identity documents is challenging, providing a space to improve in the future works.