 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2xset
Papers and Code
AFFormer: Adaptive Feature Fusion Transformer for V2X Cooperative Perception under Channel Impairments
May 03, 2026Accurate 3D object detection is essential for ensuring the safety of autonomous vehicles. Cooperative perception, which leverages vehicle-to-everything (V2X) communication to share perceptual data, enhances detection but is vulnerable to channel impairments, such as noise, fading, and interference. To strengthen the reliability of intelligent transportation systems, this work improves the robustness of V2X cooperative perception under communication conditions that reflect common channel impairments. This paper proposes an Adaptive Feature Fusion Transformer (AFFormer), a Transformer-based framework that mitigates the adverse effects of corrupted features by modeling temporal, inter-agent, and spatial correlations. AFFormer introduces three key modules: Multi-Agent and Temporal Aggregation for context-aware fusion across agents and over time, Dual Spatial Attention for efficient modeling of spatial dependencies, and Uncertainty-Guided Fusion for entropy-driven refinement of fused features. A teacher-student knowledge distillation strategy further enhances robustness by aligning fused features with reliable early-collaboration supervision. AFFormer is validated on the V2XSet and DAIR-V2X datasets, where it consistently outperforms existing methods under both ideal and impaired communication conditions, demonstrating improved robustness to communication-induced feature degradation while maintaining a competitive efficiency-accuracy trade-off.
Which2comm: An Efficient Collaborative Perception Framework for 3D Object Detection
Mar 21, 2025



Collaborative perception allows real-time inter-agent information exchange and thus offers invaluable opportunities to enhance the perception capabilities of individual agents. However, limited communication bandwidth in practical scenarios restricts the inter-agent data transmission volume, consequently resulting in performance declines in collaborative perception systems. This implies a trade-off between perception performance and communication cost. To address this issue, we propose Which2comm, a novel multi-agent 3D object detection framework leveraging object-level sparse features. By integrating semantic information of objects into 3D object detection boxes, we introduce semantic detection boxes (SemDBs). Innovatively transmitting these information-rich object-level sparse features among agents not only significantly reduces the demanding communication volume, but also improves 3D object detection performance. Specifically, a fully sparse network is constructed to extract SemDBs from individual agents; a temporal fusion approach with a relative temporal encoding mechanism is utilized to obtain the comprehensive spatiotemporal features. Extensive experiments on the V2XSet and OPV2V datasets demonstrate that Which2comm consistently outperforms other state-of-the-art methods on both perception performance and communication cost, exhibiting better robustness to real-world latency. These results present that for multi-agent collaborative 3D object detection, transmitting only object-level sparse features is sufficient to achieve high-precision and robust performance.
V2X-DG: Domain Generalization for Vehicle-to-Everything Cooperative Perception
Mar 19, 2025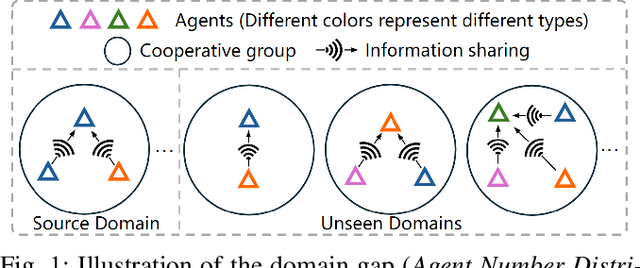
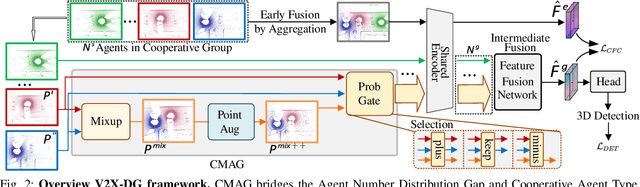
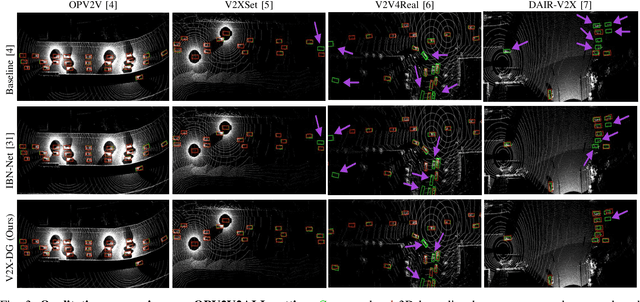

LiDAR-based Vehicle-to-Everything (V2X) cooperative perception has demonstrated its impact on the safety and effectiveness of autonomous driving. Since current cooperative perception algorithms are trained and tested on the same dataset, the generalization ability of cooperative perception systems remains underexplored. This paper is the first work to study the Domain Generalization problem of LiDAR-based V2X cooperative perception (V2X-DG) for 3D detection based on four widely-used open source datasets: OPV2V, V2XSet, V2V4Real and DAIR-V2X. Our research seeks to sustain high performance not only within the source domain but also across other unseen domains, achieved solely through training on source domain. To this end, we propose Cooperative Mixup Augmentation based Generalization (CMAG) to improve the model generalization capability by simulating the unseen cooperation, which is designed compactly for the domain gaps in cooperative perception. Furthermore, we propose a constraint for the regularization of the robust generalized feature representation learning: Cooperation Feature Consistency (CFC), which aligns the intermediately fused features of the generalized cooperation by CMAG and the early fused features of the original cooperation in source domain. Extensive experiments demonstrate that our approach achieves significant performance gains when generalizing to other unseen datasets while it also maintains strong performance on the source dataset.
CoopDETR: A Unified Cooperative Perception Framework for 3D Detection via Object Query
Feb 26, 2025



Cooperative perception enhances the individual perception capabilities of autonomous vehicles (AVs) by providing a comprehensive view of the environment. However, balancing perception performance and transmission costs remains a significant challenge. Current approaches that transmit region-level features across agents are limited in interpretability and demand substantial bandwidth, making them unsuitable for practical applications. In this work, we propose CoopDETR, a novel cooperative perception framework that introduces object-level feature cooperation via object query. Our framework consists of two key modules: single-agent query generation, which efficiently encodes raw sensor data into object queries, reducing transmission cost while preserving essential information for detection; and cross-agent query fusion, which includes Spatial Query Matching (SQM) and Object Query Aggregation (OQA) to enable effective interaction between queries. Our experiments on the OPV2V and V2XSet datasets demonstrate that CoopDETR achieves state-of-the-art performance and significantly reduces transmission costs to 1/782 of previous methods.
AgentAlign: Misalignment-Adapted Multi-Agent Perception for Resilient Inter-Agent Sensor Correlations
Dec 09, 2024Cooperative perception has attracted wide attention given its capability to leverage shared information across connected automated vehicles (CAVs) and smart infrastructures to address sensing occlusion and range limitation issues. However, existing research overlooks the fragile multi-sensor correlations in multi-agent settings, as the heterogeneous agent sensor measurements are highly susceptible to environmental factors, leading to weakened inter-agent sensor interactions. The varying operational conditions and other real-world factors inevitably introduce multifactorial noise and consequentially lead to multi-sensor misalignment, making the deployment of multi-agent multi-modality perception particularly challenging in the real world. In this paper, we propose AgentAlign, a real-world heterogeneous agent cross-modality feature alignment framework, to effectively address these multi-modality misalignment issues. Our method introduces a cross-modality feature alignment space (CFAS) and heterogeneous agent feature alignment (HAFA) mechanism to harmonize multi-modality features across various agents dynamically. Additionally, we present a novel V2XSet-noise dataset that simulates realistic sensor imperfections under diverse environmental conditions, facilitating a systematic evaluation of our approach's robustness. Extensive experiments on the V2X-Real and V2XSet-Noise benchmarks demonstrate that our framework achieves state-of-the-art performance, underscoring its potential for real-world applications in cooperative autonomous driving. The controllable V2XSet-Noise dataset and generation pipeline will be released in the future.
IFTR: An Instance-Level Fusion Transformer for Visual Collaborative Perception
Jul 13, 2024



Multi-agent collaborative perception has emerged as a widely recognized technology in the field of autonomous driving in recent years. However, current collaborative perception predominantly relies on LiDAR point clouds, with significantly less attention given to methods using camera images. This severely impedes the development of budget-constrained collaborative systems and the exploitation of the advantages offered by the camera modality. This work proposes an instance-level fusion transformer for visual collaborative perception (IFTR), which enhances the detection performance of camera-only collaborative perception systems through the communication and sharing of visual features. To capture the visual information from multiple agents, we design an instance feature aggregation that interacts with the visual features of individual agents using predefined grid-shaped bird eye view (BEV) queries, generating more comprehensive and accurate BEV features. Additionally, we devise a cross-domain query adaptation as a heuristic to fuse 2D priors, implicitly encoding the candidate positions of targets. Furthermore, IFTR optimizes communication efficiency by sending instance-level features, achieving an optimal performance-bandwidth trade-off. We evaluate the proposed IFTR on a real dataset, DAIR-V2X, and two simulated datasets, OPV2V and V2XSet, achieving performance improvements of 57.96%, 9.23% and 12.99% in AP@70 metrics compared to the previous SOTAs, respectively. Extensive experiments demonstrate the superiority of IFTR and the effectiveness of its key components. The code is available at https://github.com/wangsh0111/IFTR.
V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions
Mar 29, 2024



Current LiDAR-based Vehicle-to-Everything (V2X) multi-agent perception systems have shown the significant success on 3D object detection. While these models perform well in the trained clean weather, they struggle in unseen adverse weather conditions with the real-world domain gap. In this paper, we propose a domain generalization approach, named V2X-DGW, for LiDAR-based 3D object detection on multi-agent perception system under adverse weather conditions. Not only in the clean weather does our research aim to ensure favorable multi-agent performance, but also in the unseen adverse weather conditions by learning only on the clean weather data. To advance research in this area, we have simulated the impact of three prevalent adverse weather conditions on two widely-used multi-agent datasets, resulting in the creation of two novel benchmark datasets: OPV2V-w and V2XSet-w. To this end, we first introduce the Adaptive Weather Augmentation (AWA) to mimic the unseen adverse weather conditions, and then propose two alignments for generalizable representation learning: Trust-region Weather-invariant Alignment (TWA) and Agent-aware Contrastive Alignment (ACA). Extensive experimental results demonstrate that our V2X-DGW achieved improvements in the unseen adverse weather conditions.
Breaking Data Silos: Cross-Domain Learning for Multi-Agent Perception from Independent Private Sources
Feb 20, 2024



The diverse agents in multi-agent perception systems may be from different companies. Each company might use the identical classic neural network architecture based encoder for feature extraction. However, the data source to train the various agents is independent and private in each company, leading to the Distribution Gap of different private data for training distinct agents in multi-agent perception system. The data silos by the above Distribution Gap could result in a significant performance decline in multi-agent perception. In this paper, we thoroughly examine the impact of the distribution gap on existing multi-agent perception systems. To break the data silos, we introduce the Feature Distribution-aware Aggregation (FDA) framework for cross-domain learning to mitigate the above Distribution Gap in multi-agent perception. FDA comprises two key components: Learnable Feature Compensation Module and Distribution-aware Statistical Consistency Module, both aimed at enhancing intermediate features to minimize the distribution gap among multi-agent features. Intensive experiments on the public OPV2V and V2XSet datasets underscore FDA's effectiveness in point cloud-based 3D object detection, presenting it as an invaluable augmentation to existing multi-agent perception systems.
DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection
Dec 25, 2023



Vehicle-to-Everything (V2X) collaborative perception has recently gained significant attention due to its capability to enhance scene understanding by integrating information from various agents, e.g., vehicles, and infrastructure. However, current works often treat the information from each agent equally, ignoring the inherent domain gap caused by the utilization of different LiDAR sensors of each agent, thus leading to suboptimal performance. In this paper, we propose DI-V2X, that aims to learn Domain-Invariant representations through a new distillation framework to mitigate the domain discrepancy in the context of V2X 3D object detection. DI-V2X comprises three essential components: a domain-mixing instance augmentation (DMA) module, a progressive domain-invariant distillation (PDD) module, and a domain-adaptive fusion (DAF) module. Specifically, DMA builds a domain-mixing 3D instance bank for the teacher and student models during training, resulting in aligned data representation. Next, PDD encourages the student models from different domains to gradually learn a domain-invariant feature representation towards the teacher, where the overlapping regions between agents are employed as guidance to facilitate the distillation process. Furthermore, DAF closes the domain gap between the students by incorporating calibration-aware domain-adaptive attention. Extensive experiments on the challenging DAIR-V2X and V2XSet benchmark datasets demonstrate DI-V2X achieves remarkable performance, outperforming all the previous V2X models. Code is available at https://github.com/Serenos/DI-V2X
DUSA: Decoupled Unsupervised Sim2Real Adaptation for Vehicle-to-Everything Collaborative Perception
Oct 12, 2023Vehicle-to-Everything (V2X) collaborative perception is crucial for autonomous driving. However, achieving high-precision V2X perception requires a significant amount of annotated real-world data, which can always be expensive and hard to acquire. Simulated data have raised much attention since they can be massively produced at an extremely low cost. Nevertheless, the significant domain gap between simulated and real-world data, including differences in sensor type, reflectance patterns, and road surroundings, often leads to poor performance of models trained on simulated data when evaluated on real-world data. In addition, there remains a domain gap between real-world collaborative agents, e.g. different types of sensors may be installed on autonomous vehicles and roadside infrastructures with different extrinsics, further increasing the difficulty of sim2real generalization. To take full advantage of simulated data, we present a new unsupervised sim2real domain adaptation method for V2X collaborative detection named Decoupled Unsupervised Sim2Real Adaptation (DUSA). Our new method decouples the V2X collaborative sim2real domain adaptation problem into two sub-problems: sim2real adaptation and inter-agent adaptation. For sim2real adaptation, we design a Location-adaptive Sim2Real Adapter (LSA) module to adaptively aggregate features from critical locations of the feature map and align the features between simulated data and real-world data via a sim/real discriminator on the aggregated global feature. For inter-agent adaptation, we further devise a Confidence-aware Inter-agent Adapter (CIA) module to align the fine-grained features from heterogeneous agents under the guidance of agent-wise confidence maps. Experiments demonstrate the effectiveness of the proposed DUSA approach on unsupervised sim2real adaptation from the simulated V2XSet dataset to the real-world DAIR-V2X-C dataset.