 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
Apr 09, 2026This paper addresses the task of large-scale 3D scene reconstruction from long video sequences. Recent feed-forward reconstruction models have shown promising results by directly regressing 3D geometry from RGB images without explicit 3D priors or geometric constraints. However, these methods often struggle to maintain reconstruction accuracy and consistency over long sequences due to limited memory capacity and the inability to effectively capture global contextual cues. In contrast, humans can naturally exploit the global understanding of the scene to inform local perception. Motivated by this, we propose a novel neural global context representation that efficiently compresses and retains long-range scene information, enabling the model to leverage extensive contextual cues for enhanced reconstruction accuracy and consistency. The context representation is realized through a set of lightweight neural sub-networks that are rapidly adapted during test time via self-supervised objectives, which substantially increases memory capacity without incurring significant computational overhead. The experiments on multiple large-scale benchmarks, including the KITTI Odometry~\cite{Geiger2012CVPR} and Oxford Spires~\cite{tao2025spires} datasets, demonstrate the effectiveness of our approach in handling ultra-large scenes, achieving leading pose accuracy and state-of-the-art 3D reconstruction accuracy while maintaining efficiency. Code is available at https://zju3dv.github.io/scal3r.
CAMAv2: A Vision-Centric Approach for Static Map Element Annotation
Jul 31, 2024



The recent development of online static map element (a.k.a. HD map) construction algorithms has raised a vast demand for data with ground truth annotations. However, available public datasets currently cannot provide high-quality training data regarding consistency and accuracy. For instance, the manual labelled (low efficiency) nuScenes still contains misalignment and inconsistency between the HD maps and images (e.g., around 8.03 pixels reprojection error on average). To this end, we present CAMAv2: a vision-centric approach for Consistent and Accurate Map Annotation. Without LiDAR inputs, our proposed framework can still generate high-quality 3D annotations of static map elements. Specifically, the annotation can achieve high reprojection accuracy across all surrounding cameras and is spatial-temporal consistent across the whole sequence. We apply our proposed framework to the popular nuScenes dataset to provide efficient and highly accurate annotations. Compared with the original nuScenes static map element, our CAMAv2 annotations achieve lower reprojection errors (e.g., 4.96 vs. 8.03 pixels). Models trained with annotations from CAMAv2 also achieve lower reprojection errors (e.g., 5.62 vs. 8.43 pixels).
VRSO: Visual-Centric Reconstruction for Static Object Annotation
Mar 22, 2024



As a part of the perception results of intelligent driving systems, static object detection (SOD) in 3D space provides crucial cues for driving environment understanding. With the rapid deployment of deep neural networks for SOD tasks, the demand for high-quality training samples soars. The traditional, also reliable, way is manual labeling over the dense LiDAR point clouds and reference images. Though most public driving datasets adopt this strategy to provide SOD ground truth (GT), it is still expensive (requires LiDAR scanners) and low-efficient (time-consuming and unscalable) in practice. This paper introduces VRSO, a visual-centric approach for static object annotation. VRSO is distinguished in low cost, high efficiency, and high quality: (1) It recovers static objects in 3D space with only camera images as input, and (2) manual labeling is barely involved since GT for SOD tasks is generated based on an automatic reconstruction and annotation pipeline. (3) Experiments on the Waymo Open Dataset show that the mean reprojection error from VRSO annotation is only 2.6 pixels, around four times lower than the Waymo labeling (10.6 pixels). Source code is available at: https://github.com/CaiYingFeng/VRSO.
V2X-AHD:Vehicle-to-Everything Cooperation Perception via Asymmetric Heterogenous Distillation Network
Oct 10, 2023



Object detection is the central issue of intelligent traffic systems, and recent advancements in single-vehicle lidar-based 3D detection indicate that it can provide accurate position information for intelligent agents to make decisions and plan. Compared with single-vehicle perception, multi-view vehicle-road cooperation perception has fundamental advantages, such as the elimination of blind spots and a broader range of perception, and has become a research hotspot. However, the current perception of cooperation focuses on improving the complexity of fusion while ignoring the fundamental problems caused by the absence of single-view outlines. We propose a multi-view vehicle-road cooperation perception system, vehicle-to-everything cooperative perception (V2X-AHD), in order to enhance the identification capability, particularly for predicting the vehicle's shape. At first, we propose an asymmetric heterogeneous distillation network fed with different training data to improve the accuracy of contour recognition, with multi-view teacher features transferring to single-view student features. While the point cloud data are sparse, we propose Spara Pillar, a spare convolutional-based plug-in feature extraction backbone, to reduce the number of parameters and improve and enhance feature extraction capabilities. Moreover, we leverage the multi-head self-attention (MSA) to fuse the single-view feature, and the lightweight design makes the fusion feature a smooth expression. The results of applying our algorithm to the massive open dataset V2Xset demonstrate that our method achieves the state-of-the-art result. The V2X-AHD can effectively improve the accuracy of 3D object detection and reduce the number of network parameters, according to this study, which serves as a benchmark for cooperative perception. The code for this article is available at https://github.com/feeling0414-lab/V2X-AHD.
VNI-Net: Vector Neurons-based Rotation-Invariant Descriptor for LiDAR Place Recognition
Aug 24, 2023LiDAR-based place recognition plays a crucial role in Simultaneous Localization and Mapping (SLAM) and LiDAR localization. Despite the emergence of various deep learning-based and hand-crafting-based methods, rotation-induced place recognition failure remains a critical challenge. Existing studies address this limitation through specific training strategies or network structures. However, the former does not produce satisfactory results, while the latter focuses mainly on the reduced problem of SO(2) rotation invariance. Methods targeting SO(3) rotation invariance suffer from limitations in discrimination capability. In this paper, we propose a new method that employs Vector Neurons Network (VNN) to achieve SO(3) rotation invariance. We first extract rotation-equivariant features from neighboring points and map low-dimensional features to a high-dimensional space through VNN. Afterwards, we calculate the Euclidean and Cosine distance in the rotation-equivariant feature space as rotation-invariant feature descriptors. Finally, we aggregate the features using GeM pooling to obtain global descriptors. To address the significant information loss when formulating rotation-invariant descriptors, we propose computing distances between features at different layers within the Euclidean space neighborhood. This greatly improves the discriminability of the point cloud descriptors while ensuring computational efficiency. Experimental results on public datasets show that our approach significantly outperforms other baseline methods implementing rotation invariance, while achieving comparable results with current state-of-the-art place recognition methods that do not consider rotation issues.
Learning Sequence Descriptor based on Spatiotemporal Attention for Visual Place Recognition
May 19, 2023



Sequence-based visual place recognition (sVPR) aims to match frame sequences with frames stored in a reference map for localization. Existing methods include sequence matching and sequence descriptor-based retrieval. The former is based on the assumption of constant velocity, which is difficult to hold in real scenarios and does not get rid of the intrinsic single frame descriptor mismatch. The latter solves this problem by extracting a descriptor for the whole sequence, but current sequence descriptors are only constructed by feature aggregation of multi-frames, with no temporal information interaction. In this paper, we propose a sequential descriptor extraction method to fuse spatiotemporal information effectively and generate discriminative descriptors. Specifically, similar features on the same frame focu on each other and learn space structure, and the same local regions of different frames learn local feature changes over time. And we use sliding windows to control the temporal self-attention range and adpot relative position encoding to construct the positional relationships between different features, which allows our descriptor to capture the inherent dynamics in the frame sequence and local feature motion.
Patch-NetVLAD+: Learned patch descriptor and weighted matching strategy for place recognition
Feb 11, 2022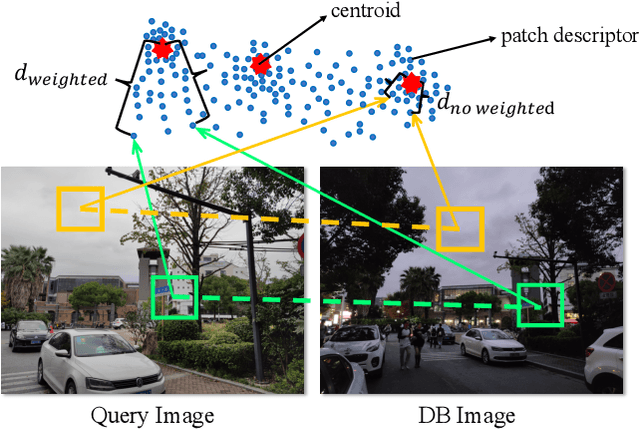
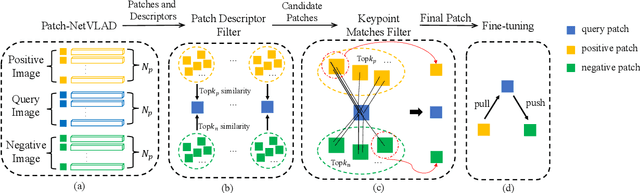
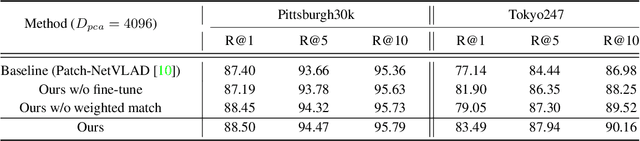
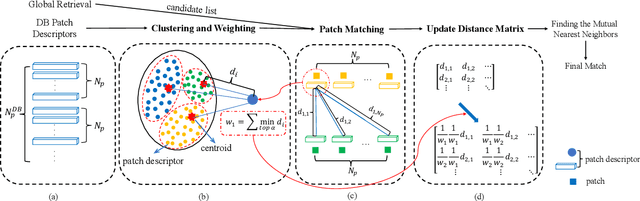
Visual Place Recognition (VPR) in areas with similar scenes such as urban or indoor scenarios is a major challenge. Existing VPR methods using global descriptors have difficulty capturing local specific regions (LSR) in the scene and are therefore prone to localization confusion in such scenarios. As a result, finding the LSR that are critical for location recognition becomes key. To address this challenge, we introduced Patch-NetVLAD+, which was inspired by patch-based VPR researches. Our method proposed a fine-tuning strategy with triplet loss to make NetVLAD suitable for extracting patch-level descriptors. Moreover, unlike existing methods that treat all patches in an image equally, our method extracts patches of LSR, which present less frequently throughout the dataset, and makes them play an important role in VPR by assigning proper weights to them. Experiments on Pittsburgh30k and Tokyo247 datasets show that our approach achieved up to 6.35\% performance improvement than existing patch-based methods.
DSC: Deep Scan Context Descriptor for Large-Scale Place Recognition
Nov 27, 2021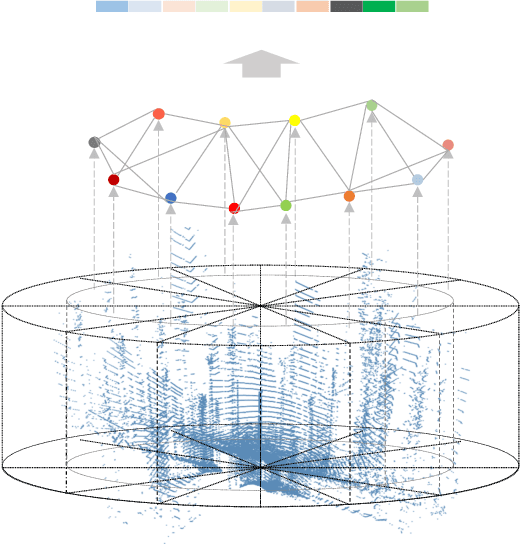
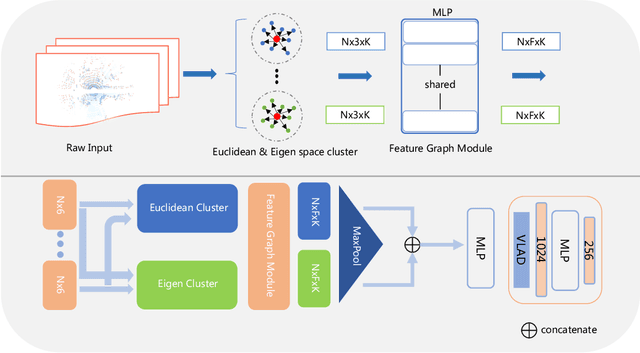
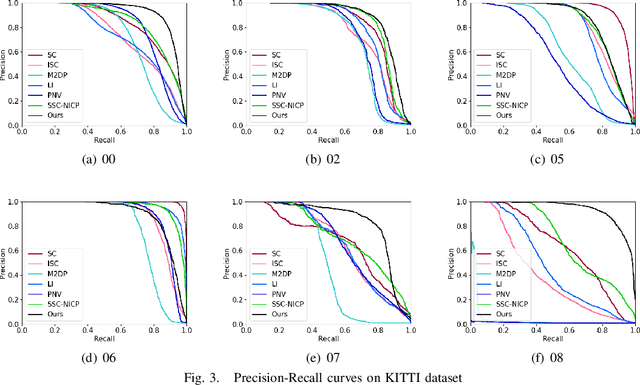
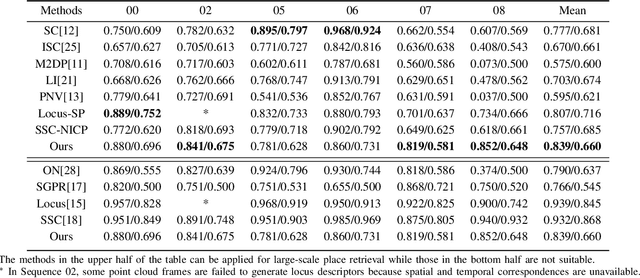
LiDAR-based place recognition is an essential and challenging task both in loop closure detection and global relocalization. We propose Deep Scan Context (DSC), a general and discriminative global descriptor that captures the relationship among segments of a point cloud. Unlike previous methods that utilize either semantics or a sequence of adjacent point clouds for better place recognition, we only use raw point clouds to get competitive results. Concretely, we first segment the point cloud egocentrically to acquire centroids and eigenvalues of the segments. Then, we introduce a graph neural network to aggregate these features into an embedding representation. Extensive experiments conducted on the KITTI dataset show that DSC is robust to scene variants and outperforms existing methods.