 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO-Count: Differentiable Object Counting for Text-to-Image Generation
Aug 01, 2025



We propose YOLO-Count, a differentiable open-vocabulary object counting model that tackles both general counting challenges and enables precise quantity control for text-to-image (T2I) generation. A core contribution is the 'cardinality' map, a novel regression target that accounts for variations in object size and spatial distribution. Leveraging representation alignment and a hybrid strong-weak supervision scheme, YOLO-Count bridges the gap between open-vocabulary counting and T2I generation control. Its fully differentiable architecture facilitates gradient-based optimization, enabling accurate object count estimation and fine-grained guidance for generative models. Extensive experiments demonstrate that YOLO-Count achieves state-of-the-art counting accuracy while providing robust and effective quantity control for T2I systems.
UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid Robots
Jul 10, 2025Humanoid robots must achieve diverse, robust, and generalizable whole-body control to operate effectively in complex, human-centric environments. However, existing methods, particularly those based on teacher-student frameworks often suffer from a loss of motion diversity during policy distillation and exhibit limited generalization to unseen behaviors. In this work, we present UniTracker, a simplified yet powerful framework that integrates a Conditional Variational Autoencoder (CVAE) into the student policy to explicitly model the latent diversity of human motion. By leveraging a learned CVAE prior, our method enables the student to retain expressive motion characteristics while improving robustness and adaptability under partial observations. The result is a single policy capable of tracking a wide spectrum of whole-body motions with high fidelity and stability. Comprehensive experiments in both simulation and real-world deployments demonstrate that UniTracker significantly outperforms MLP-based DAgger baselines in motion quality, generalization to unseen references, and deployment robustness, offering a practical and scalable solution for expressive humanoid control.
Active View Selector: Fast and Accurate Active View Selection with Cross Reference Image Quality Assessment
Jun 24, 2025We tackle active view selection in novel view synthesis and 3D reconstruction. Existing methods like FisheRF and ActiveNeRF select the next best view by minimizing uncertainty or maximizing information gain in 3D, but they require specialized designs for different 3D representations and involve complex modelling in 3D space. Instead, we reframe this as a 2D image quality assessment (IQA) task, selecting views where current renderings have the lowest quality. Since ground-truth images for candidate views are unavailable, full-reference metrics like PSNR and SSIM are inapplicable, while no-reference metrics, such as MUSIQ and MANIQA, lack the essential multi-view context. Inspired by a recent cross-referencing quality framework CrossScore, we train a model to predict SSIM within a multi-view setup and use it to guide view selection. Our cross-reference IQA framework achieves substantial quantitative and qualitative improvements across standard benchmarks, while being agnostic to 3D representations, and runs 14-33 times faster than previous methods.
Seeing in the Dark: Benchmarking Egocentric 3D Vision with the Oxford Day-and-Night Dataset
Jun 04, 2025



We introduce Oxford Day-and-Night, a large-scale, egocentric dataset for novel view synthesis (NVS) and visual relocalisation under challenging lighting conditions. Existing datasets often lack crucial combinations of features such as ground-truth 3D geometry, wide-ranging lighting variation, and full 6DoF motion. Oxford Day-and-Night addresses these gaps by leveraging Meta ARIA glasses to capture egocentric video and applying multi-session SLAM to estimate camera poses, reconstruct 3D point clouds, and align sequences captured under varying lighting conditions, including both day and night. The dataset spans over 30 $\mathrm{km}$ of recorded trajectories and covers an area of 40,000 $\mathrm{m}^2$, offering a rich foundation for egocentric 3D vision research. It supports two core benchmarks, NVS and relocalisation, providing a unique platform for evaluating models in realistic and diverse environments.
VEAttack: Downstream-agnostic Vision Encoder Attack against Large Vision Language Models
May 23, 2025Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in multimodal understanding and generation, yet their vulnerability to adversarial attacks raises significant robustness concerns. While existing effective attacks always focus on task-specific white-box settings, these approaches are limited in the context of LVLMs, which are designed for diverse downstream tasks and require expensive full-model gradient computations. Motivated by the pivotal role and wide adoption of the vision encoder in LVLMs, we propose a simple yet effective Vision Encoder Attack (VEAttack), which targets the vision encoder of LVLMs only. Specifically, we propose to generate adversarial examples by minimizing the cosine similarity between the clean and perturbed visual features, without accessing the following large language models, task information, and labels. It significantly reduces the computational overhead while eliminating the task and label dependence of traditional white-box attacks in LVLMs. To make this simple attack effective, we propose to perturb images by optimizing image tokens instead of the classification token. We provide both empirical and theoretical evidence that VEAttack can easily generalize to various tasks. VEAttack has achieved a performance degradation of 94.5% on image caption task and 75.7% on visual question answering task. We also reveal some key observations to provide insights into LVLM attack/defense: 1) hidden layer variations of LLM, 2) token attention differential, 3) M\"obius band in transfer attack, 4) low sensitivity to attack steps. The code is available at https://github.com/hfmei/VEAttack-LVLM
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025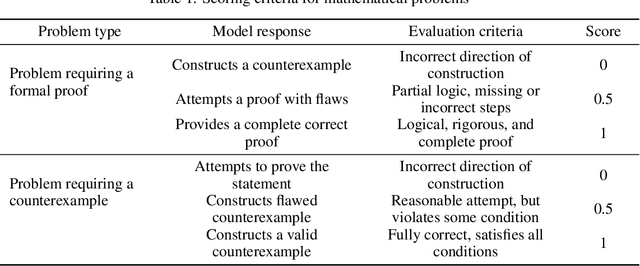
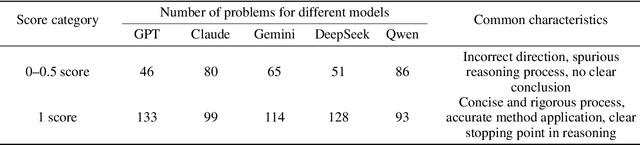
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
DifIISR: A Diffusion Model with Gradient Guidance for Infrared Image Super-Resolution
Mar 03, 2025



Infrared imaging is essential for autonomous driving and robotic operations as a supportive modality due to its reliable performance in challenging environments. Despite its popularity, the limitations of infrared cameras, such as low spatial resolution and complex degradations, consistently challenge imaging quality and subsequent visual tasks. Hence, infrared image super-resolution (IISR) has been developed to address this challenge. While recent developments in diffusion models have greatly advanced this field, current methods to solve it either ignore the unique modal characteristics of infrared imaging or overlook the machine perception requirements. To bridge these gaps, we propose DifIISR, an infrared image super-resolution diffusion model optimized for visual quality and perceptual performance. Our approach achieves task-based guidance for diffusion by injecting gradients derived from visual and perceptual priors into the noise during the reverse process. Specifically, we introduce an infrared thermal spectrum distribution regulation to preserve visual fidelity, ensuring that the reconstructed infrared images closely align with high-resolution images by matching their frequency components. Subsequently, we incorporate various visual foundational models as the perceptual guidance for downstream visual tasks, infusing generalizable perceptual features beneficial for detection and segmentation. As a result, our approach gains superior visual results while attaining State-Of-The-Art downstream task performance. Code is available at https://github.com/zirui0625/DifIISR
VB-Com: Learning Vision-Blind Composite Humanoid Locomotion Against Deficient Perception
Feb 20, 2025The performance of legged locomotion is closely tied to the accuracy and comprehensiveness of state observations. Blind policies, which rely solely on proprioception, are considered highly robust due to the reliability of proprioceptive observations. However, these policies significantly limit locomotion speed and often require collisions with the terrain to adapt. In contrast, Vision policies allows the robot to plan motions in advance and respond proactively to unstructured terrains with an online perception module. However, perception is often compromised by noisy real-world environments, potential sensor failures, and the limitations of current simulations in presenting dynamic or deformable terrains. Humanoid robots, with high degrees of freedom and inherently unstable morphology, are particularly susceptible to misguidance from deficient perception, which can result in falls or termination on challenging dynamic terrains. To leverage the advantages of both vision and blind policies, we propose VB-Com, a composite framework that enables humanoid robots to determine when to rely on the vision policy and when to switch to the blind policy under perceptual deficiency. We demonstrate that VB-Com effectively enables humanoid robots to traverse challenging terrains and obstacles despite perception deficiencies caused by dynamic terrains or perceptual noise.
Learning Humanoid Standing-up Control across Diverse Postures
Feb 12, 2025Standing-up control is crucial for humanoid robots, with the potential for integration into current locomotion and loco-manipulation systems, such as fall recovery. Existing approaches are either limited to simulations that overlook hardware constraints or rely on predefined ground-specific motion trajectories, failing to enable standing up across postures in real-world scenes. To bridge this gap, we present HoST (Humanoid Standing-up Control), a reinforcement learning framework that learns standing-up control from scratch, enabling robust sim-to-real transfer across diverse postures. HoST effectively learns posture-adaptive motions by leveraging a multi-critic architecture and curriculum-based training on diverse simulated terrains. To ensure successful real-world deployment, we constrain the motion with smoothness regularization and implicit motion speed bound to alleviate oscillatory and violent motions on physical hardware, respectively. After simulation-based training, the learned control policies are directly deployed on the Unitree G1 humanoid robot. Our experimental results demonstrate that the controllers achieve smooth, stable, and robust standing-up motions across a wide range of laboratory and outdoor environments. Videos are available at https://taohuang13.github.io/humanoid-standingup.github.io/.
ARFlow: Autogressive Flow with Hybrid Linear Attention
Jan 27, 2025



Flow models are effective at progressively generating realistic images, but they generally struggle to capture long-range dependencies during the generation process as they compress all the information from previous time steps into a single corrupted image. To address this limitation, we propose integrating autoregressive modeling -- known for its excellence in modeling complex, high-dimensional joint probability distributions -- into flow models. During training, at each step, we construct causally-ordered sequences by sampling multiple images from the same semantic category and applying different levels of noise, where images with higher noise levels serve as causal predecessors to those with lower noise levels. This design enables the model to learn broader category-level variations while maintaining proper causal relationships in the flow process. During generation, the model autoregressively conditions the previously generated images from earlier denoising steps, forming a contextual and coherent generation trajectory. Additionally, we design a customized hybrid linear attention mechanism tailored to our modeling approach to enhance computational efficiency. Our approach, termed ARFlow, under 400k training steps, achieves 14.08 FID scores on ImageNet at 128 * 128 without classifier-free guidance, reaching 4.34 FID with classifier-free guidance 1.5, significantly outperforming the previous flow-based model SiT's 9.17 FID. Extensive ablation studies demonstrate the effectiveness of our modeling strategy and chunk-wise attention design.