 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANCHOR: Agentic Noise Creation Framework for Human Simulation and Denoising Recommendation
Jun 04, 2026Distilling accurate user preferences from noisy implicit feedback remains a fundamental bottleneck in recommendation systems, highlighting the need for recommendation denoising. However, real-world data lack explicit noise annotations, forcing existing methods to rely on unsupervised side information or handcrafted heuristics. These approaches often incur high external costs, generalize poorly, or depend on unreliable priors, causing noise misidentification and corrupting true user preference representations. To address these limitations, we propose a paradigm-level reformulation of recommendation denoising. Instead of indirectly inferring noisy interactions through heuristics, our Creation-Recognition paradigm proactively creates labeled noisy interactions and trains a dedicated recognizer to identify them, transforming denoising from heuristic filtering into supervised learning. Based on this paradigm, we present ANCHOR, an agent-based framework inspired by recent LLM-as-User research. ANCHOR simulates user behaviors to generate realistic noise labels and enables supervised denoising through two stages: noise creation and noise recognition. In the noise creation stage, ANCHOR adopts a recommender-in-the-loop agentic architecture to synthesize both diverse out-of-preference noise and informative boundary-adjacent noise. For out-of-preference noise, it implements five extensible simulation mechanisms to approximate major sources of noisy implicit feedback. For boundary-adjacent noise, an adversarial boundary refinement mechanism generates ambiguous interactions that challenge the recognizer and target the decision boundary. In the noise recognition stage, ANCHOR leverages the generated labels to train a reusable parametric recognizer that integrates collaborative signals and semantic representations to detect noise patterns in real interaction data.
Reasoning as an Attack Surface: Adaptive Evolutionary CoT Jailbreaks for LLMs
May 23, 2026Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in reasoning and generation tasks and are increasingly deployed in real-world applications. However, their explicit chain-of-thought (CoT) mechanism introduces new security risks, making them particularly vulnerable to jailbreak attacks. Existing approaches often rely on static CoT templates to elicit harmful outputs, but such fixed designs suffer from limited diversity, adaptability, and effectiveness. To overcome these limitations, we propose an adaptive evolutionary CoT jailbreak framework, called AE-CoT. Specifically, the method first rewrites harmful goals into mild prompts with teacher role-play and decomposes them into semantically coherent reasoning fragments to construct a pool of CoT jailbreak candidates. Then, within a structured representation space, we perform multi-generation evolutionary search, where candidate diversity is expanded through fragment-level crossover and a mutation strategy with an adaptive mutation-rate control mechanism. An independent scoring model provides graded harmfulness evaluations, and high-scoring candidates are further enhanced with a harmful CoT template to induce more destructive generations. Extensive experiments across multiple models and datasets demonstrate the effectiveness of the proposed AE-CoT, consistently outperforming state-of-the-art jailbreak methods.
AgentGR: Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendation
May 11, 2026Group Recommendation (GR) aims to suggest items to a group of users, which has become a critical component of modern social platforms. Existing GR methods focus on aggregating individual user preferences with advanced neural networks to infer group preferences. Despite effectiveness, they essentially treat group preference learning as a simple preference aggregation process, failing to capture the complex dynamics of real-world group decision-making. To address these limitations, we propose AgentGR, a novel Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendations, inspired by the semantic reasoning and human behavior simulation capabilities of LLM-driven agents. It aims to jointly capture collaborative-semantic user preferences for member-role-playing and simulate dynamic group interactions to reflect real-world group decision-making processes, thereby boosting recommendation performance. Specifically, to capture collaborative-semantic user preferences, we introduce a semantic meta-path guided chain-of-preference reasoning mechanism that integrates high-order collaborative filtering signals and textual semantics to improve user preference profiles. To model the complex dynamics of group decision-making, we first recognize group topic and leadership to explicitly model the influencing factors within the group decision processes. Building on these, we simulate group-level decision dynamics via two multi-agent simulation strategies for recommendations: a static workflow-based strategy for efficiency and a dynamic dialogue-based strategy for precision. Extensive experiments on two real-world datasets show that AgentGR significantly outperforms state-of-the-art baselines in both recommendation accuracy and group decision simulation, highlighting its potential for real-world GR applications.
Adaptive Image Zoom-in with Bounding Box Transformation for UAV Object Detection
Feb 07, 2026Detecting objects from UAV-captured images is challenging due to the small object size. In this work, a simple and efficient adaptive zoom-in framework is explored for object detection on UAV images. The main motivation is that the foreground objects are generally smaller and sparser than those in common scene images, which hinders the optimization of effective object detectors. We thus aim to zoom in adaptively on the objects to better capture object features for the detection task. To achieve the goal, two core designs are required: \textcolor{black}{i) How to conduct non-uniform zooming on each image efficiently? ii) How to enable object detection training and inference with the zoomed image space?} Correspondingly, a lightweight offset prediction scheme coupled with a novel box-based zooming objective is introduced to learn non-uniform zooming on the input image. Based on the learned zooming transformation, a corner-aligned bounding box transformation method is proposed. The method warps the ground-truth bounding boxes to the zoomed space to learn object detection, and warps the predicted bounding boxes back to the original space during inference. We conduct extensive experiments on three representative UAV object detection datasets, including VisDrone, UAVDT, and SeaDronesSee. The proposed ZoomDet is architecture-independent and can be applied to an arbitrary object detection architecture. Remarkably, on the SeaDronesSee dataset, ZoomDet offers more than 8.4 absolute gain of mAP with a Faster R-CNN model, with only about 3 ms additional latency. The code is available at https://github.com/twangnh/zoomdet_code.
HyperCOD: The First Challenging Benchmark and Baseline for Hyperspectral Camouflaged Object Detection
Jan 07, 2026RGB-based camouflaged object detection struggles in real-world scenarios where color and texture cues are ambiguous. While hyperspectral image offers a powerful alternative by capturing fine-grained spectral signatures, progress in hyperspectral camouflaged object detection (HCOD) has been critically hampered by the absence of a dedicated, large-scale benchmark. To spur innovation, we introduce HyperCOD, the first challenging benchmark for HCOD. Comprising 350 high-resolution hyperspectral images, It features complex real-world scenarios with minimal objects, intricate shapes, severe occlusions, and dynamic lighting to challenge current models. The advent of foundation models like the Segment Anything Model (SAM) presents a compelling opportunity. To adapt the Segment Anything Model (SAM) for HCOD, we propose HyperSpectral Camouflage-aware SAM (HSC-SAM). HSC-SAM ingeniously reformulates the hyperspectral image by decoupling it into a spatial map fed to SAM's image encoder and a spectral saliency map that serves as an adaptive prompt. This translation effectively bridges the modality gap. Extensive experiments show that HSC-SAM sets a new state-of-the-art on HyperCOD and generalizes robustly to other public HSI datasets. The HyperCOD dataset and our HSC-SAM baseline provide a robust foundation to foster future research in this emerging area.
Efficient Hyperspectral Image Reconstruction Using Lightweight Separate Spectral Transformers
Jan 03, 2026Hyperspectral imaging (HSI) is essential across various disciplines for its capacity to capture rich spectral information. However, efficiently reconstructing hyperspectral images from compressive sensing measurements presents significant challenges. To tackle these, we adopt a divide-and-conquer strategy that capitalizes on the unique spectral and spatial characteristics of hyperspectral images. We introduce the Lightweight Separate Spectral Transformer (LSST), an innovative architecture tailored for efficient hyperspectral image reconstruction. This architecture consists of Separate Spectral Transformer Blocks (SSTB) for modeling spectral relationships and Lightweight Spatial Convolution Blocks (LSCB) for spatial processing. The SSTB employs Grouped Spectral Self-attention and a Spectrum Shuffle operation to effectively manage both local and non-local spectral relationships. Simultaneously, the LSCB utilizes depth-wise separable convolutions and strategic ordering to enhance spatial information processing. Furthermore, we implement the Focal Spectrum Loss, a novel loss weighting mechanism that dynamically adjusts during training to improve reconstruction across spectrally complex bands. Extensive testing demonstrates that our LSST achieves superior performance while requiring fewer FLOPs and parameters, underscoring its efficiency and effectiveness. The source code is available at: https://github.com/wcz1124/LSST.
MODA: The First Challenging Benchmark for Multispectral Object Detection in Aerial Images
Dec 10, 2025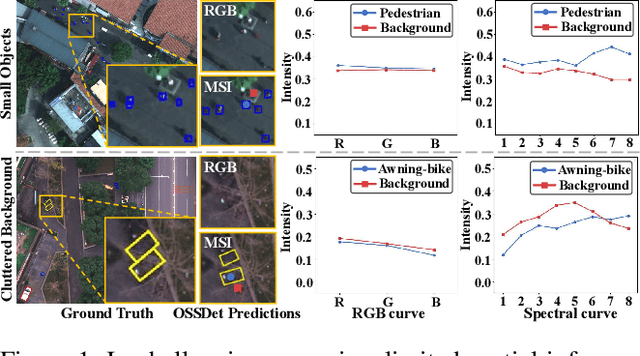


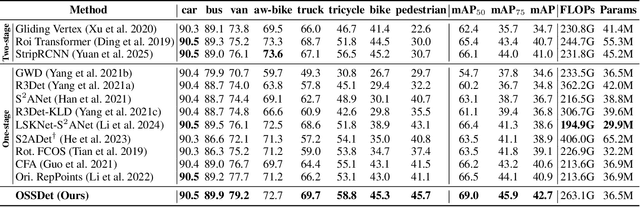
Aerial object detection faces significant challenges in real-world scenarios, such as small objects and extensive background interference, which limit the performance of RGB-based detectors with insufficient discriminative information. Multispectral images (MSIs) capture additional spectral cues across multiple bands, offering a promising alternative. However, the lack of training data has been the primary bottleneck to exploiting the potential of MSIs. To address this gap, we introduce the first large-scale dataset for Multispectral Object Detection in Aerial images (MODA), which comprises 14,041 MSIs and 330,191 annotations across diverse, challenging scenarios, providing a comprehensive data foundation for this field. Furthermore, to overcome challenges inherent to aerial object detection using MSIs, we propose OSSDet, a framework that integrates spectral and spatial information with object-aware cues. OSSDet employs a cascaded spectral-spatial modulation structure to optimize target perception, aggregates spectrally related features by exploiting spectral similarities to reinforce intra-object correlations, and suppresses irrelevant background via object-aware masking. Moreover, cross-spectral attention further refines object-related representations under explicit object-aware guidance. Extensive experiments demonstrate that OSSDet outperforms existing methods with comparable parameters and efficiency.
Learning to Control Physically-simulated 3D Characters via Generating and Mimicking 2D Motions
Dec 09, 2025Video data is more cost-effective than motion capture data for learning 3D character motion controllers, yet synthesizing realistic and diverse behaviors directly from videos remains challenging. Previous approaches typically rely on off-the-shelf motion reconstruction techniques to obtain 3D trajectories for physics-based imitation. These reconstruction methods struggle with generalizability, as they either require 3D training data (potentially scarce) or fail to produce physically plausible poses, hindering their application to challenging scenarios like human-object interaction (HOI) or non-human characters. We tackle this challenge by introducing Mimic2DM, a novel motion imitation framework that learns the control policy directly and solely from widely available 2D keypoint trajectories extracted from videos. By minimizing the reprojection error, we train a general single-view 2D motion tracking policy capable of following arbitrary 2D reference motions in physics simulation, using only 2D motion data. The policy, when trained on diverse 2D motions captured from different or slightly different viewpoints, can further acquire 3D motion tracking capabilities by aggregating multiple views. Moreover, we develop a transformer-based autoregressive 2D motion generator and integrate it into a hierarchical control framework, where the generator produces high-quality 2D reference trajectories to guide the tracking policy. We show that the proposed approach is versatile and can effectively learn to synthesize physically plausible and diverse motions across a range of domains, including dancing, soccer dribbling, and animal movements, without any reliance on explicit 3D motion data. Project Website: https://jiann-li.github.io/mimic2dm/
MMOT: The First Challenging Benchmark for Drone-based Multispectral Multi-Object Tracking
Oct 14, 2025Drone-based multi-object tracking is essential yet highly challenging due to small targets, severe occlusions, and cluttered backgrounds. Existing RGB-based tracking algorithms heavily depend on spatial appearance cues such as color and texture, which often degrade in aerial views, compromising reliability. Multispectral imagery, capturing pixel-level spectral reflectance, provides crucial cues that enhance object discriminability under degraded spatial conditions. However, the lack of dedicated multispectral UAV datasets has hindered progress in this domain. To bridge this gap, we introduce MMOT, the first challenging benchmark for drone-based multispectral multi-object tracking. It features three key characteristics: (i) Large Scale - 125 video sequences with over 488.8K annotations across eight categories; (ii) Comprehensive Challenges - covering diverse conditions such as extreme small targets, high-density scenarios, severe occlusions, and complex motion; and (iii) Precise Oriented Annotations - enabling accurate localization and reduced ambiguity under aerial perspectives. To better extract spectral features and leverage oriented annotations, we further present a multispectral and orientation-aware MOT scheme adapting existing methods, featuring: (i) a lightweight Spectral 3D-Stem integrating spectral features while preserving compatibility with RGB pretraining; (ii) an orientation-aware Kalman filter for precise state estimation; and (iii) an end-to-end orientation-adaptive transformer. Extensive experiments across representative trackers consistently show that multispectral input markedly improves tracking performance over RGB baselines, particularly for small and densely packed objects. We believe our work will advance drone-based multispectral multi-object tracking research. Our MMOT, code, and benchmarks are publicly available at https://github.com/Annzstbl/MMOT.
MCOD: The First Challenging Benchmark for Multispectral Camouflaged Object Detection
Sep 19, 2025



Camouflaged Object Detection (COD) aims to identify objects that blend seamlessly into natural scenes. Although RGB-based methods have advanced, their performance remains limited under challenging conditions. Multispectral imagery, providing rich spectral information, offers a promising alternative for enhanced foreground-background discrimination. However, existing COD benchmark datasets are exclusively RGB-based, lacking essential support for multispectral approaches, which has impeded progress in this area. To address this gap, we introduce MCOD, the first challenging benchmark dataset specifically designed for multispectral camouflaged object detection. MCOD features three key advantages: (i) Comprehensive challenge attributes: It captures real-world difficulties such as small object sizes and extreme lighting conditions commonly encountered in COD tasks. (ii) Diverse real-world scenarios: The dataset spans a wide range of natural environments to better reflect practical applications. (iii) High-quality pixel-level annotations: Each image is manually annotated with precise object masks and corresponding challenge attribute labels. We benchmark eleven representative COD methods on MCOD, observing a consistent performance drop due to increased task difficulty. Notably, integrating multispectral modalities substantially alleviates this degradation, highlighting the value of spectral information in enhancing detection robustness. We anticipate MCOD will provide a strong foundation for future research in multispectral camouflaged object detection. The dataset is publicly accessible at https://github.com/yl2900260-bit/MCOD.