 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
Apr 06, 2025



The advances in vision-language models (VLMs) have led to a growing interest in autonomous driving to leverage their strong reasoning capabilities. However, extending these capabilities from 2D to full 3D understanding is crucial for real-world applications. To address this challenge, we propose OmniDrive, a holistic vision-language dataset that aligns agent models with 3D driving tasks through counterfactual reasoning. This approach enhances decision-making by evaluating potential scenarios and their outcomes, similar to human drivers considering alternative actions. Our counterfactual-based synthetic data annotation process generates large-scale, high-quality datasets, providing denser supervision signals that bridge planning trajectories and language-based reasoning. Futher, we explore two advanced OmniDrive-Agent frameworks, namely Omni-L and Omni-Q, to assess the importance of vision-language alignment versus 3D perception, revealing critical insights into designing effective LLM-agents. Significant improvements on the DriveLM Q\&A benchmark and nuScenes open-loop planning demonstrate the effectiveness of our dataset and methods.
Slow-Fast Architecture for Video Multi-Modal Large Language Models
Apr 02, 2025Balancing temporal resolution and spatial detail under limited compute budget remains a key challenge for video-based multi-modal large language models (MLLMs). Existing methods typically compress video representations using predefined rules before feeding them into the LLM, resulting in irreversible information loss and often ignoring input instructions. To address this, we propose a novel slow-fast architecture that naturally circumvents this trade-off, enabling the use of more input frames while preserving spatial details. Inspired by how humans first skim a video before focusing on relevant parts, our slow-fast design employs a dual-token strategy: 1) "fast" visual tokens -- a compact set of compressed video features -- are fed into the LLM alongside text embeddings to provide a quick overview; 2) "slow" visual tokens -- uncompressed video features -- are cross-attended by text embeddings through specially designed hybrid decoder layers, enabling instruction-aware extraction of relevant visual details with linear complexity. We conduct systematic exploration to optimize both the overall architecture and key components. Experiments show that our model significantly outperforms self-attention-only baselines, extending the input capacity from 16 to 128 frames with just a 3% increase in computation, and achieving a 16% average performance improvement across five video understanding benchmarks. Our 7B model achieves state-of-the-art performance among models of similar size. Furthermore, our slow-fast architecture is a plug-and-play design that can be integrated into other video MLLMs to improve efficiency and scalability.
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
Hydra-MDP++: Advancing End-to-End Driving via Expert-Guided Hydra-Distillation
Mar 17, 2025Hydra-MDP++ introduces a novel teacher-student knowledge distillation framework with a multi-head decoder that learns from human demonstrations and rule-based experts. Using a lightweight ResNet-34 network without complex components, the framework incorporates expanded evaluation metrics, including traffic light compliance (TL), lane-keeping ability (LK), and extended comfort (EC) to address unsafe behaviors not captured by traditional NAVSIM-derived teachers. Like other end-to-end autonomous driving approaches, \hydra processes raw images directly without relying on privileged perception signals. Hydra-MDP++ achieves state-of-the-art performance by integrating these components with a 91.0% drive score on NAVSIM through scaling to a V2-99 image encoder, demonstrating its effectiveness in handling diverse driving scenarios while maintaining computational efficiency.
Hydra-NeXt: Robust Closed-Loop Driving with Open-Loop Training
Mar 15, 2025End-to-end autonomous driving research currently faces a critical challenge in bridging the gap between open-loop training and closed-loop deployment. Current approaches are trained to predict trajectories in an open-loop environment, which struggle with quick reactions to other agents in closed-loop environments and risk generating kinematically infeasible plans due to the gap between open-loop training and closed-loop driving. In this paper, we introduce Hydra-NeXt, a novel multi-branch planning framework that unifies trajectory prediction, control prediction, and a trajectory refinement network in one model. Unlike current open-loop trajectory prediction models that only handle general-case planning, Hydra-NeXt further utilizes a control decoder to focus on short-term actions, which enables faster responses to dynamic situations and reactive agents. Moreover, we propose the Trajectory Refinement module to augment and refine the planning decisions by effectively adhering to kinematic constraints in closed-loop environments. This unified approach bridges the gap between open-loop training and closed-loop driving, demonstrating superior performance of 65.89 Driving Score (DS) and 48.20% Success Rate (SR) on the Bench2Drive dataset without relying on external experts for data collection. Hydra-NeXt surpasses the previous state-of-the-art by 22.98 DS and 17.49 SR, marking a significant advancement in autonomous driving. Code will be available at https://github.com/woxihuanjiangguo/Hydra-NeXt.
Centaur: Robust End-to-End Autonomous Driving with Test-Time Training
Mar 14, 2025



How can we rely on an end-to-end autonomous vehicle's complex decision-making system during deployment? One common solution is to have a ``fallback layer'' that checks the planned trajectory for rule violations and replaces it with a pre-defined safe action if necessary. Another approach involves adjusting the planner's decisions to minimize a pre-defined ``cost function'' using additional system predictions such as road layouts and detected obstacles. However, these pre-programmed rules or cost functions cannot learn and improve with new training data, often resulting in overly conservative behaviors. In this work, we propose Centaur (Cluster Entropy for Test-time trAining using Uncertainty) which updates a planner's behavior via test-time training, without relying on hand-engineered rules or cost functions. Instead, we measure and minimize the uncertainty in the planner's decisions. For this, we develop a novel uncertainty measure, called Cluster Entropy, which is simple, interpretable, and compatible with state-of-the-art planning algorithms. Using data collected at prior test-time time-steps, we perform an update to the model's parameters using a gradient that minimizes the Cluster Entropy. With only this sole gradient update prior to inference, Centaur exhibits significant improvements, ranking first on the navtest leaderboard with notable gains in safety-critical metrics such as time to collision. To provide detailed insights on a per-scenario basis, we also introduce navsafe, a challenging new benchmark, which highlights previously undiscovered failure modes of driving models.
Token-Efficient Long Video Understanding for Multimodal LLMs
Mar 06, 2025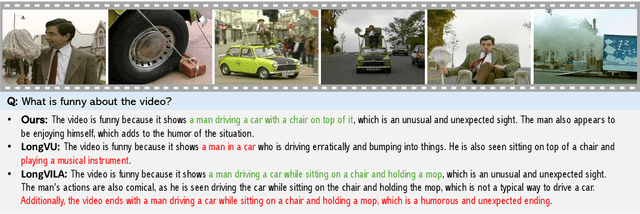
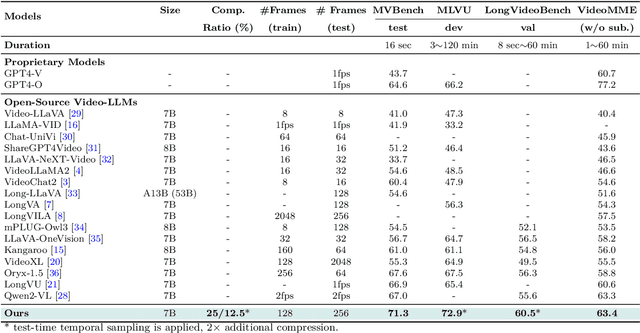
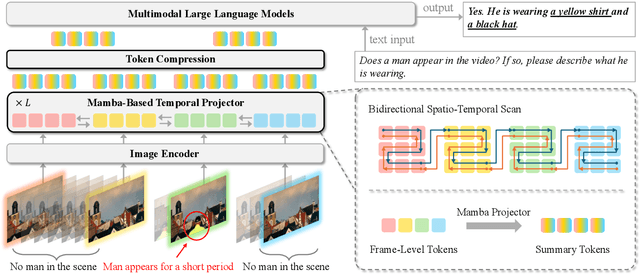
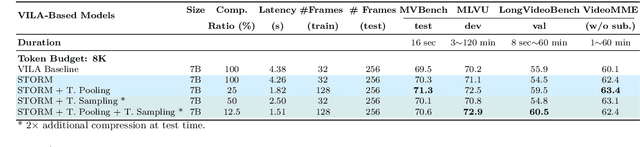
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5\% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
Enhancing Autonomous Driving Safety with Collision Scenario Integration
Mar 05, 2025Autonomous vehicle safety is crucial for the successful deployment of self-driving cars. However, most existing planning methods rely heavily on imitation learning, which limits their ability to leverage collision data effectively. Moreover, collecting collision or near-collision data is inherently challenging, as it involves risks and raises ethical and practical concerns. In this paper, we propose SafeFusion, a training framework to learn from collision data. Instead of over-relying on imitation learning, SafeFusion integrates safety-oriented metrics during training to enable collision avoidance learning. In addition, to address the scarcity of collision data, we propose CollisionGen, a scalable data generation pipeline to generate diverse, high-quality scenarios using natural language prompts, generative models, and rule-based filtering. Experimental results show that our approach improves planning performance in collision-prone scenarios by 56\% over previous state-of-the-art planners while maintaining effectiveness in regular driving situations. Our work provides a scalable and effective solution for advancing the safety of autonomous driving systems.
RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression
Feb 19, 2025



Transformer-based Large Language Models rely critically on KV cache to efficiently handle extended contexts during the decode phase. Yet, the size of the KV cache grows proportionally with the input length, burdening both memory bandwidth and capacity as decoding progresses. To address this challenge, we present RocketKV, a training-free KV cache compression strategy designed specifically to reduce both memory bandwidth and capacity demand of KV cache during the decode phase. RocketKV contains two consecutive stages. In the first stage, it performs coarse-grain KV cache eviction on the input sequence tokens with SnapKV++, a method improved upon SnapKV by introducing adaptive pooling size and full compatibility with grouped-query attention. In the second stage, it adopts a hybrid attention method to conduct fine-grain top-k sparse attention, approximating the attention scores by leveraging both head and sequence dimensional reductions. Combining these two stages, RocketKV achieves significant KV cache fetching bandwidth and storage savings while maintaining comparable accuracy to full KV cache attention. We show that RocketKV provides end-to-end speedup by up to 3$\times$ as well as peak memory reduction by up to 31% in the decode phase on an NVIDIA H100 GPU compared to the full KV cache baseline, while achieving negligible accuracy loss on a variety of long-context tasks.
AIDE: Agentically Improve Visual Language Model with Domain Experts
Feb 13, 2025



The enhancement of Visual Language Models (VLMs) has traditionally relied on knowledge distillation from larger, more capable models. This dependence creates a fundamental bottleneck for improving state-of-the-art systems, particularly when no superior models exist. We introduce AIDE (Agentic Improvement through Domain Experts), a novel framework that enables VLMs to autonomously enhance their capabilities by leveraging specialized domain expert models. AIDE operates through a four-stage process: (1) identifying instances for refinement, (2) engaging domain experts for targeted analysis, (3) synthesizing expert outputs with existing data, and (4) integrating enhanced instances into the training pipeline. Experiments on multiple benchmarks, including MMMU, MME, MMBench, etc., demonstrate AIDE's ability to achieve notable performance gains without relying on larger VLMs nor human supervision. Our framework provides a scalable, resource-efficient approach to continuous VLM improvement, addressing critical limitations in current methodologies, particularly valuable when larger models are unavailable to access.