 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason under Off-Policy Guidance
Apr 22, 2025Recent advances in large reasoning models (LRMs) demonstrate that sophisticated behaviors such as multi-step reasoning and self-reflection can emerge via reinforcement learning (RL) with simple rule-based rewards. However, existing zero-RL approaches are inherently ``on-policy'', limiting learning to a model's own outputs and failing to acquire reasoning abilities beyond its initial capabilities. We introduce LUFFY (Learning to reason Under oFF-policY guidance), a framework that augments zero-RL with off-policy reasoning traces. LUFFY dynamically balances imitation and exploration by combining off-policy demonstrations with on-policy rollouts during training. Notably, we propose policy shaping via regularized importance sampling to avoid superficial and rigid imitation during mixed-policy training. Remarkably, LUFFY achieves an over +7.0 average gain across six math benchmarks and an advantage of over +6.2 points in out-of-distribution tasks. It also substantially surpasses imitation-based supervised fine-tuning (SFT), particularly in generalization. Analysis shows LUFFY not only imitates effectively but also explores beyond demonstrations, offering a scalable path to train generalizable reasoning models with off-policy guidance.
Text-to-Decision Agent: Learning Generalist Policies from Natural Language Supervision
Apr 22, 2025



RL systems usually tackle generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose Text-to-Decision Agent (T2DA), a simple and scalable framework that supervises generalist policy learning with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines.
SegEarth-R1: Geospatial Pixel Reasoning via Large Language Model
Apr 13, 2025Remote sensing has become critical for understanding environmental dynamics, urban planning, and disaster management. However, traditional remote sensing workflows often rely on explicit segmentation or detection methods, which struggle to handle complex, implicit queries that require reasoning over spatial context, domain knowledge, and implicit user intent. Motivated by this, we introduce a new task, \ie, geospatial pixel reasoning, which allows implicit querying and reasoning and generates the mask of the target region. To advance this task, we construct and release the first large-scale benchmark dataset called EarthReason, which comprises 5,434 manually annotated image masks with over 30,000 implicit question-answer pairs. Moreover, we propose SegEarth-R1, a simple yet effective language-guided segmentation baseline that integrates a hierarchical visual encoder, a large language model (LLM) for instruction parsing, and a tailored mask generator for spatial correlation. The design of SegEarth-R1 incorporates domain-specific adaptations, including aggressive visual token compression to handle ultra-high-resolution remote sensing images, a description projection module to fuse language and multi-scale features, and a streamlined mask prediction pipeline that directly queries description embeddings. Extensive experiments demonstrate that SegEarth-R1 achieves state-of-the-art performance on both reasoning and referring segmentation tasks, significantly outperforming traditional and LLM-based segmentation methods. Our data and code will be released at https://github.com/earth-insights/SegEarth-R1.
DoorBot: Closed-Loop Task Planning and Manipulation for Door Opening in the Wild with Haptic Feedback
Apr 12, 2025Robots operating in unstructured environments face significant challenges when interacting with everyday objects like doors. They particularly struggle to generalize across diverse door types and conditions. Existing vision-based and open-loop planning methods often lack the robustness to handle varying door designs, mechanisms, and push/pull configurations. In this work, we propose a haptic-aware closed-loop hierarchical control framework that enables robots to explore and open different unseen doors in the wild. Our approach leverages real-time haptic feedback, allowing the robot to adjust its strategy dynamically based on force feedback during manipulation. We test our system on 20 unseen doors across different buildings, featuring diverse appearances and mechanical types. Our framework achieves a 90% success rate, demonstrating its ability to generalize and robustly handle varied door-opening tasks. This scalable solution offers potential applications in broader open-world articulated object manipulation tasks.
COSMIC: Clique-Oriented Semantic Multi-space Integration for Robust CLIP Test-Time Adaptation
Mar 30, 2025Recent vision-language models (VLMs) face significant challenges in test-time adaptation to novel domains. While cache-based methods show promise by leveraging historical information, they struggle with both caching unreliable feature-label pairs and indiscriminately using single-class information during querying, significantly compromising adaptation accuracy. To address these limitations, we propose COSMIC (Clique-Oriented Semantic Multi-space Integration for CLIP), a robust test-time adaptation framework that enhances adaptability through multi-granular, cross-modal semantic caching and graph-based querying mechanisms. Our framework introduces two key innovations: Dual Semantics Graph (DSG) and Clique Guided Hyper-class (CGH). The Dual Semantics Graph constructs complementary semantic spaces by incorporating textual features, coarse-grained CLIP features, and fine-grained DINOv2 features to capture rich semantic relationships. Building upon these dual graphs, the Clique Guided Hyper-class component leverages structured class relationships to enhance prediction robustness through correlated class selection. Extensive experiments demonstrate COSMIC's superior performance across multiple benchmarks, achieving significant improvements over state-of-the-art methods: 15.81% gain on out-of-distribution tasks and 5.33% on cross-domain generation with CLIP RN-50. Code is available at github.com/hf618/COSMIC.
One Snapshot is All You Need: A Generalized Method for mmWave Signal Generation
Mar 27, 2025Wireless sensing systems, particularly those using mmWave technology, offer distinct advantages over traditional vision-based approaches, such as enhanced privacy and effectiveness in poor lighting conditions. These systems, leveraging FMCW signals, have shown success in human-centric applications like localization, gesture recognition, and so on. However, comprehensive mmWave datasets for diverse applications are scarce, often constrained by pre-processed signatures (e.g., point clouds or RA heatmaps) and inconsistent annotation formats. To overcome these limitations, we propose mmGen, a novel and generalized framework tailored for full-scene mmWave signal generation. By constructing physical signal transmission models, mmGen synthesizes human-reflected and environment-reflected mmWave signals from the constructed 3D meshes. Additionally, we incorporate methods to account for material properties, antenna gains, and multipath reflections, enhancing the realism of the synthesized signals. We conduct extensive experiments using a prototype system with commercial mmWave devices and Kinect sensors. The results show that the average similarity of Range-Angle and micro-Doppler signatures between the synthesized and real-captured signals across three different environments exceeds 0.91 and 0.89, respectively, demonstrating the effectiveness and practical applicability of mmGen.
A Survey on Foundation-Model-Based Industrial Defect Detection
Feb 26, 2025
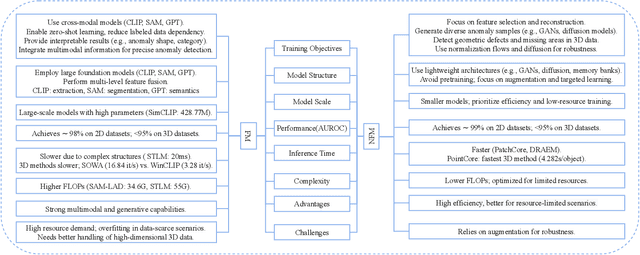
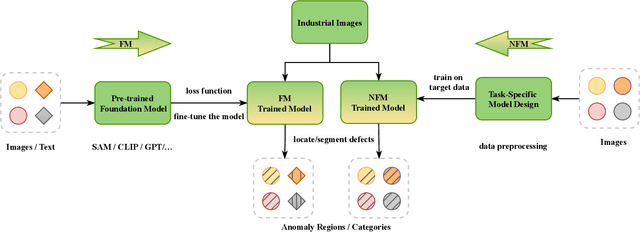
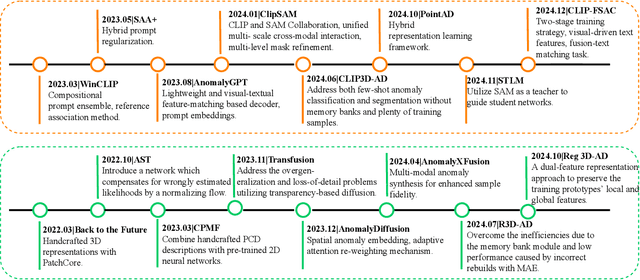
As industrial products become abundant and sophisticated, visual industrial defect detection receives much attention, including two-dimensional and three-dimensional visual feature modeling. Traditional methods use statistical analysis, abnormal data synthesis modeling, and generation-based models to separate product defect features and complete defect detection. Recently, the emergence of foundation models has brought visual and textual semantic prior knowledge. Many methods are based on foundation models (FM) to improve the accuracy of detection, but at the same time, increase model complexity and slow down inference speed. Some FM-based methods have begun to explore lightweight modeling ways, which have gradually attracted attention and deserve to be systematically analyzed. In this paper, we conduct a systematic survey with comparisons and discussions of foundation model methods from different aspects and briefly review non-foundation model (NFM) methods recently published. Furthermore, we discuss the differences between FM and NFM methods from training objectives, model structure and scale, model performance, and potential directions for future exploration. Through comparison, we find FM methods are more suitable for few-shot and zero-shot learning, which are more in line with actual industrial application scenarios and worthy of in-depth research.
JAQ: Joint Efficient Architecture Design and Low-Bit Quantization with Hardware-Software Co-Exploration
Jan 09, 2025



The co-design of neural network architectures, quantization precisions, and hardware accelerators offers a promising approach to achieving an optimal balance between performance and efficiency, particularly for model deployment on resource-constrained edge devices. In this work, we propose the JAQ Framework, which jointly optimizes the three critical dimensions. However, effectively automating the design process across the vast search space of those three dimensions poses significant challenges, especially when pursuing extremely low-bit quantization. Specifical, the primary challenges include: (1) Memory overhead in software-side: Low-precision quantization-aware training can lead to significant memory usage due to storing large intermediate features and latent weights for back-propagation, potentially causing memory exhaustion. (2) Search time-consuming in hardware-side: The discrete nature of hardware parameters and the complex interplay between compiler optimizations and individual operators make the accelerator search time-consuming. To address these issues, JAQ mitigates the memory overhead through a channel-wise sparse quantization (CSQ) scheme, selectively applying quantization to the most sensitive components of the model during optimization. Additionally, JAQ designs BatchTile, which employs a hardware generation network to encode all possible tiling modes, thereby speeding up the search for the optimal compiler mapping strategy. Extensive experiments demonstrate the effectiveness of JAQ, achieving approximately 7% higher Top-1 accuracy on ImageNet compared to previous methods and reducing the hardware search time per iteration to 0.15 seconds.
HisynSeg: Weakly-Supervised Histopathological Image Segmentation via Image-Mixing Synthesis and Consistency Regularization
Dec 30, 2024



Tissue semantic segmentation is one of the key tasks in computational pathology. To avoid the expensive and laborious acquisition of pixel-level annotations, a wide range of studies attempt to adopt the class activation map (CAM), a weakly-supervised learning scheme, to achieve pixel-level tissue segmentation. However, CAM-based methods are prone to suffer from under-activation and over-activation issues, leading to poor segmentation performance. To address this problem, we propose a novel weakly-supervised semantic segmentation framework for histopathological images based on image-mixing synthesis and consistency regularization, dubbed HisynSeg. Specifically, synthesized histopathological images with pixel-level masks are generated for fully-supervised model training, where two synthesis strategies are proposed based on Mosaic transformation and B\'ezier mask generation. Besides, an image filtering module is developed to guarantee the authenticity of the synthesized images. In order to further avoid the model overfitting to the occasional synthesis artifacts, we additionally propose a novel self-supervised consistency regularization, which enables the real images without segmentation masks to supervise the training of the segmentation model. By integrating the proposed techniques, the HisynSeg framework successfully transforms the weakly-supervised semantic segmentation problem into a fully-supervised one, greatly improving the segmentation accuracy. Experimental results on three datasets prove that the proposed method achieves a state-of-the-art performance. Code is available at https://github.com/Vison307/HisynSeg.
Lungmix: A Mixup-Based Strategy for Generalization in Respiratory Sound Classification
Dec 29, 2024Respiratory sound classification plays a pivotal role in diagnosing respiratory diseases. While deep learning models have shown success with various respiratory sound datasets, our experiments indicate that models trained on one dataset often fail to generalize effectively to others, mainly due to data collection and annotation \emph{inconsistencies}. To address this limitation, we introduce \emph{Lungmix}, a novel data augmentation technique inspired by Mixup. Lungmix generates augmented data by blending waveforms using loudness and random masks while interpolating labels based on their semantic meaning, helping the model learn more generalized representations. Comprehensive evaluations across three datasets, namely ICBHI, SPR, and HF, demonstrate that Lungmix significantly enhances model generalization to unseen data. In particular, Lungmix boosts the 4-class classification score by up to 3.55\%, achieving performance comparable to models trained directly on the target dataset.