 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Experts Meets In-Context Reinforcement Learning
Jun 05, 2025In-context reinforcement learning (ICRL) has emerged as a promising paradigm for adapting RL agents to downstream tasks through prompt conditioning. However, two notable challenges remain in fully harnessing in-context learning within RL domains: the intrinsic multi-modality of the state-action-reward data and the diverse, heterogeneous nature of decision tasks. To tackle these challenges, we propose \textbf{T2MIR} (\textbf{T}oken- and \textbf{T}ask-wise \textbf{M}oE for \textbf{I}n-context \textbf{R}L), an innovative framework that introduces architectural advances of mixture-of-experts (MoE) into transformer-based decision models. T2MIR substitutes the feedforward layer with two parallel layers: a token-wise MoE that captures distinct semantics of input tokens across multiple modalities, and a task-wise MoE that routes diverse tasks to specialized experts for managing a broad task distribution with alleviated gradient conflicts. To enhance task-wise routing, we introduce a contrastive learning method that maximizes the mutual information between the task and its router representation, enabling more precise capture of task-relevant information. The outputs of two MoE components are concatenated and fed into the next layer. Comprehensive experiments show that T2MIR significantly facilitates in-context learning capacity and outperforms various types of baselines. We bring the potential and promise of MoE to ICRL, offering a simple and scalable architectural enhancement to advance ICRL one step closer toward achievements in language and vision communities. Our code is available at https://github.com/NJU-RL/T2MIR.
Divide and Conquer: Grounding LLMs as Efficient Decision-Making Agents via Offline Hierarchical Reinforcement Learning
May 26, 2025While showing sophisticated reasoning abilities, large language models (LLMs) still struggle with long-horizon decision-making tasks due to deficient exploration and long-term credit assignment, especially in sparse-reward scenarios. Inspired by the divide-and-conquer principle, we propose an innovative framework **GLIDER** (**G**rounding **L**anguage Models as Eff**I**cient **D**ecision-Making Agents via Offline Hi**E**rarchical **R**einforcement Learning) that introduces a parameter-efficient and generally applicable hierarchy to LLM policies. We develop a scheme where the low-level controller is supervised with abstract, step-by-step plans that are learned and instructed by the high-level policy. This design decomposes complicated problems into a series of coherent chain-of-thought reasoning sub-tasks, providing flexible temporal abstraction to significantly enhance exploration and learning for long-horizon tasks. Furthermore, GLIDER facilitates fast online adaptation to non-stationary environments owing to the strong transferability of its task-agnostic low-level skills. Experiments on ScienceWorld and ALFWorld benchmarks show that GLIDER achieves consistent performance gains, along with enhanced generalization capabilities.
Text-to-Decision Agent: Learning Generalist Policies from Natural Language Supervision
Apr 22, 2025



RL systems usually tackle generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose Text-to-Decision Agent (T2DA), a simple and scalable framework that supervises generalist policy learning with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines.
Learning to Reason under Off-Policy Guidance
Apr 22, 2025Recent advances in large reasoning models (LRMs) demonstrate that sophisticated behaviors such as multi-step reasoning and self-reflection can emerge via reinforcement learning (RL) with simple rule-based rewards. However, existing zero-RL approaches are inherently ``on-policy'', limiting learning to a model's own outputs and failing to acquire reasoning abilities beyond its initial capabilities. We introduce LUFFY (Learning to reason Under oFF-policY guidance), a framework that augments zero-RL with off-policy reasoning traces. LUFFY dynamically balances imitation and exploration by combining off-policy demonstrations with on-policy rollouts during training. Notably, we propose policy shaping via regularized importance sampling to avoid superficial and rigid imitation during mixed-policy training. Remarkably, LUFFY achieves an over +7.0 average gain across six math benchmarks and an advantage of over +6.2 points in out-of-distribution tasks. It also substantially surpasses imitation-based supervised fine-tuning (SFT), particularly in generalization. Analysis shows LUFFY not only imitates effectively but also explores beyond demonstrations, offering a scalable path to train generalizable reasoning models with off-policy guidance.
IDAN: Image Difference Attention Network for Change Detection
Aug 17, 2022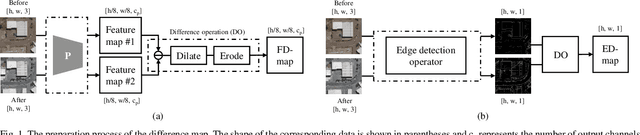
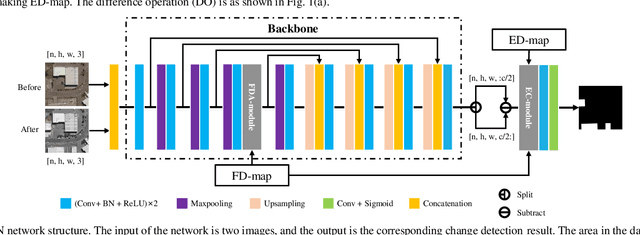
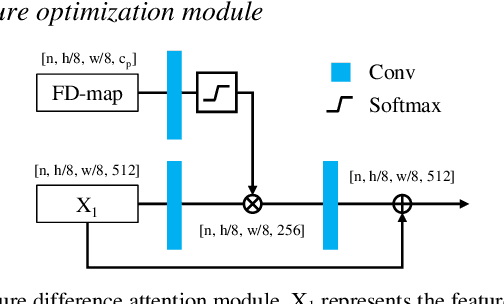
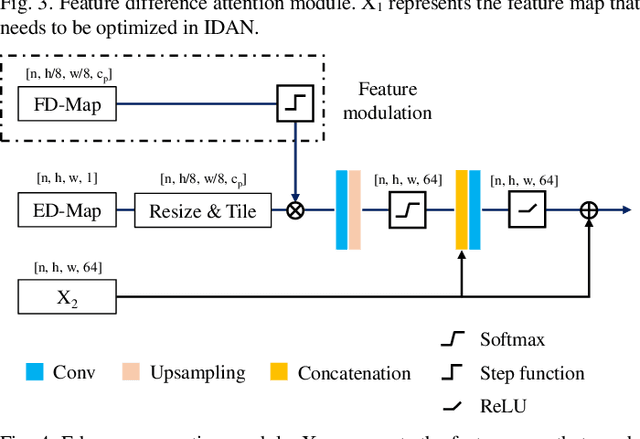
Remote sensing image change detection is of great importance in disaster assessment and urban planning. The mainstream method is to use encoder-decoder models to detect the change region of two input images. Since the change content of remote sensing images has the characteristics of wide scale range and variety, it is necessary to improve the detection accuracy of the network by increasing the attention mechanism, which commonly includes: Squeeze-and-Excitation block, Non-local and Convolutional Block Attention Module, among others. These methods consider the importance of different location features between channels or within channels, but fail to perceive the differences between input images. In this paper, we propose a novel image difference attention network (IDAN). In the image preprocessing stage, we use a pre-training model to extract the feature differences between two input images to obtain the feature difference map (FD-map), and Canny for edge detection to obtain the edge difference map (ED-map). In the image feature extracting stage, the FD-map and ED-map are input to the feature difference attention module and edge compensation module, respectively, to optimize the features extracted by IDAN. Finally, the change detection result is obtained through the feature difference operation. IDAN comprehensively considers the differences in regional and edge features of images and thus optimizes the extracted image features. The experimental results demonstrate that the F1-score of IDAN improves 1.62% and 1.98% compared to the baseline model on WHU dataset and LEVIR-CD dataset, respectively.
Road detection via a dual-task network based on cross-layer graph fusion modules
Aug 17, 2022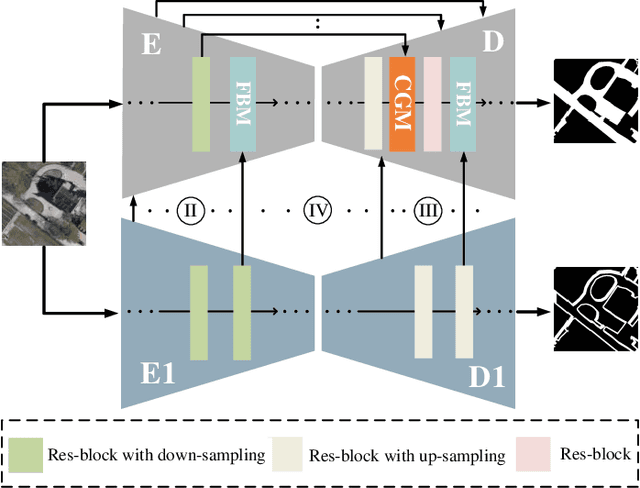
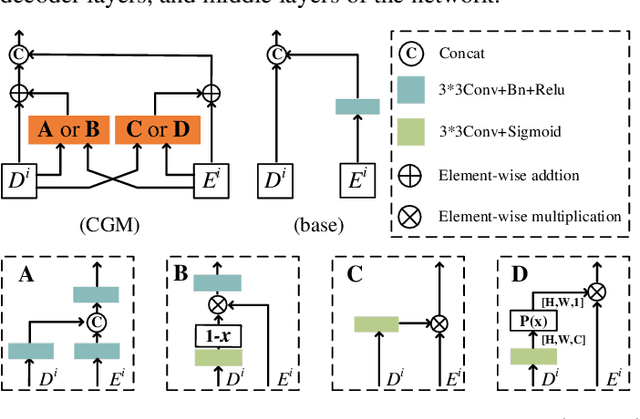
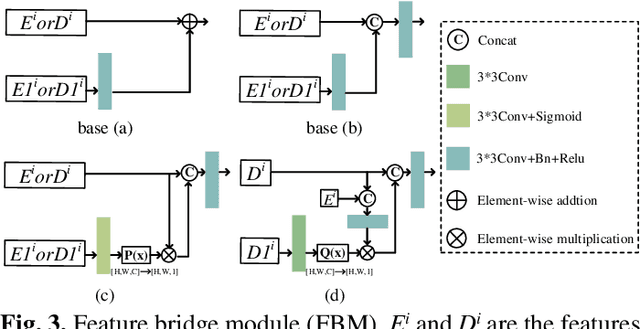
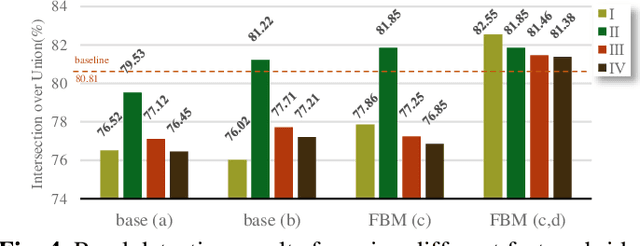
Road detection based on remote sensing images is of great significance to intelligent traffic management. The performances of the mainstream road detection methods are mainly determined by their extracted features, whose richness and robustness can be enhanced by fusing features of different types and cross-layer connections. However, the features in the existing mainstream model frameworks are often similar in the same layer by the single-task training, and the traditional cross-layer fusion ways are too simple to obtain an efficient effect, so more complex fusion ways besides concatenation and addition deserve to be explored. Aiming at the above defects, we propose a dual-task network (DTnet) for road detection and cross-layer graph fusion module (CGM): the DTnet consists of two parallel branches for road area and edge detection, respectively, while enhancing the feature diversity by fusing features between two branches through our designed feature bridge modules (FBM). The CGM improves the cross-layer fusion effect by a complex feature stream graph, and four graph patterns are evaluated. Experimental results on three public datasets demonstrate that our method effectively improves the final detection result.