 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers
Jul 25, 2024



Vision transformers (ViTs) have demonstrated their superior accuracy for computer vision tasks compared to convolutional neural networks (CNNs). However, ViT models are often computation-intensive for efficient deployment on resource-limited edge devices. This work proposes Quasar-ViT, a hardware-oriented quantization-aware architecture search framework for ViTs, to design efficient ViT models for hardware implementation while preserving the accuracy. First, Quasar-ViT trains a supernet using our row-wise flexible mixed-precision quantization scheme, mixed-precision weight entanglement, and supernet layer scaling techniques. Then, it applies an efficient hardware-oriented search algorithm, integrated with hardware latency and resource modeling, to determine a series of optimal subnets from supernet under different inference latency targets. Finally, we propose a series of model-adaptive designs on the FPGA platform to support the architecture search and mitigate the gap between the theoretical computation reduction and the practical inference speedup. Our searched models achieve 101.5, 159.6, and 251.6 frames-per-second (FPS) inference speed on the AMD/Xilinx ZCU102 FPGA with 80.4%, 78.6%, and 74.9% top-1 accuracy, respectively, for the ImageNet dataset, consistently outperforming prior works.
SNED: Superposition Network Architecture Search for Efficient Video Diffusion Model
May 31, 2024



While AI-generated content has garnered significant attention, achieving photo-realistic video synthesis remains a formidable challenge. Despite the promising advances in diffusion models for video generation quality, the complex model architecture and substantial computational demands for both training and inference create a significant gap between these models and real-world applications. This paper presents SNED, a superposition network architecture search method for efficient video diffusion model. Our method employs a supernet training paradigm that targets various model cost and resolution options using a weight-sharing method. Moreover, we propose the supernet training sampling warm-up for fast training optimization. To showcase the flexibility of our method, we conduct experiments involving both pixel-space and latent-space video diffusion models. The results demonstrate that our framework consistently produces comparable results across different model options with high efficiency. According to the experiment for the pixel-space video diffusion model, we can achieve consistent video generation results simultaneously across 64 x 64 to 256 x 256 resolutions with a large range of model sizes from 640M to 1.6B number of parameters for pixel-space video diffusion models.
A Video Coding Method Based on Neural Network for CLIC2024
Jan 08, 2024



This paper presents a video coding scheme that combines traditional optimization methods with deep learning methods based on the Enhanced Compression Model (ECM). In this paper, the traditional optimization methods adaptively adjust the quantization parameter (QP). The key frame QP offset is set according to the video content characteristics, and the coding tree unit (CTU) level QP of all frames is also adjusted according to the spatial-temporal perception information. Block importance mapping technology (BIM) is also introduced, which adjusts the QP according to the block importance. Meanwhile, the deep learning methods propose a convolutional neural network-based loop filter (CNNLF), which is turned on/off based on the rate-distortion optimization at the CTU and frame level. Besides, intra-prediction using neural networks (NN-intra) is proposed to further improve compression quality, where 8 neural networks are used for predicting blocks of different sizes. The experimental results show that compared with ECM-3.0, the proposed traditional methods and adding deep learning methods improve the PSNR by 0.54 dB and 1 dB at 0.05Mbps, respectively; 0.38 dB and 0.71dB at 0.5 Mbps, respectively, which proves the superiority of our method.
Agile-Quant: Activation-Guided Quantization for Faster Inference of LLMs on the Edge
Dec 09, 2023



Large Language Models (LLMs) stand out for their impressive performance in intricate language modeling tasks. However, their demanding computational and memory needs pose obstacles for broad use on edge devices. Quantization is then introduced to boost LLMs' on-device efficiency. Recent works show that 8-bit or lower weight quantization is feasible with minimal impact on end-to-end task performance, while the activation is still not quantized. On the other hand, mainstream commodity edge devices still struggle to execute these sub-8-bit quantized networks effectively. In this paper, we propose Agile-Quant, an activation-guided quantization framework for popular Large Language Models (LLMs), and implement an end-to-end accelerator on multiple edge devices for faster inference. Considering the hardware profiling and activation analysis, we first introduce a basic activation quantization strategy to balance the trade-off of task performance and real inference speed. Then we leverage the activation-aware token pruning technique to reduce the outliers and the adverse impact on attentivity. Ultimately, we utilize the SIMD-based 4-bit multiplier and our efficient TRIP matrix multiplication to implement the accelerator for LLMs on the edge. We apply our framework on different scales of LLMs including LLaMA, OPT, and BLOOM with 4-bit or 8-bit for the activation and 4-bit for the weight quantization. Experiments show that Agile-Quant achieves simultaneous quantization of model weights and activations while maintaining task performance comparable to existing weight-only quantization methods. Moreover, in the 8- and 4-bit scenario, Agile-Quant achieves an on-device speedup of up to 2.55x compared to its FP16 counterparts across multiple edge devices, marking a pioneering advancement in this domain.
SupeRBNN: Randomized Binary Neural Network Using Adiabatic Superconductor Josephson Devices
Sep 21, 2023



Adiabatic Quantum-Flux-Parametron (AQFP) is a superconducting logic with extremely high energy efficiency. By employing the distinct polarity of current to denote logic `0' and `1', AQFP devices serve as excellent carriers for binary neural network (BNN) computations. Although recent research has made initial strides toward developing an AQFP-based BNN accelerator, several critical challenges remain, preventing the design from being a comprehensive solution. In this paper, we propose SupeRBNN, an AQFP-based randomized BNN acceleration framework that leverages software-hardware co-optimization to eventually make the AQFP devices a feasible solution for BNN acceleration. Specifically, we investigate the randomized behavior of the AQFP devices and analyze the impact of crossbar size on current attenuation, subsequently formulating the current amplitude into the values suitable for use in BNN computation. To tackle the accumulation problem and improve overall hardware performance, we propose a stochastic computing-based accumulation module and a clocking scheme adjustment-based circuit optimization method. We validate our SupeRBNN framework across various datasets and network architectures, comparing it with implementations based on different technologies, including CMOS, ReRAM, and superconducting RSFQ/ERSFQ. Experimental results demonstrate that our design achieves an energy efficiency of approximately 7.8x10^4 times higher than that of the ReRAM-based BNN framework while maintaining a similar level of model accuracy. Furthermore, when compared with superconductor-based counterparts, our framework demonstrates at least two orders of magnitude higher energy efficiency.
HeatViT: Hardware-Efficient Adaptive Token Pruning for Vision Transformers
Nov 15, 2022



While vision transformers (ViTs) have continuously achieved new milestones in the field of computer vision, their sophisticated network architectures with high computation and memory costs have impeded their deployment on resource-limited edge devices. In this paper, we propose a hardware-efficient image-adaptive token pruning framework called HeatViT for efficient yet accurate ViT acceleration on embedded FPGAs. By analyzing the inherent computational patterns in ViTs, we first design an effective attention-based multi-head token selector, which can be progressively inserted before transformer blocks to dynamically identify and consolidate the non-informative tokens from input images. Moreover, we implement the token selector on hardware by adding miniature control logic to heavily reuse existing hardware components built for the backbone ViT. To improve the hardware efficiency, we further employ 8-bit fixed-point quantization, and propose polynomial approximations with regularization effect on quantization error for the frequently used nonlinear functions in ViTs. Finally, we propose a latency-aware multi-stage training strategy to determine the transformer blocks for inserting token selectors and optimize the desired (average) pruning rates for inserted token selectors, in order to improve both the model accuracy and inference latency on hardware. Compared to existing ViT pruning studies, under the similar computation cost, HeatViT can achieve 0.7%$\sim$8.9% higher accuracy; while under the similar model accuracy, HeatViT can achieve more than 28.4%$\sim$65.3% computation reduction, for various widely used ViTs, including DeiT-T, DeiT-S, DeiT-B, LV-ViT-S, and LV-ViT-M, on the ImageNet dataset. Compared to the baseline hardware accelerator, our implementations of HeatViT on the Xilinx ZCU102 FPGA achieve 3.46$\times$$\sim$4.89$\times$ speedup.
StereoVoxelNet: Real-Time Obstacle Detection Based on Occupancy Voxels from a Stereo Camera Using Deep Neural Networks
Sep 18, 2022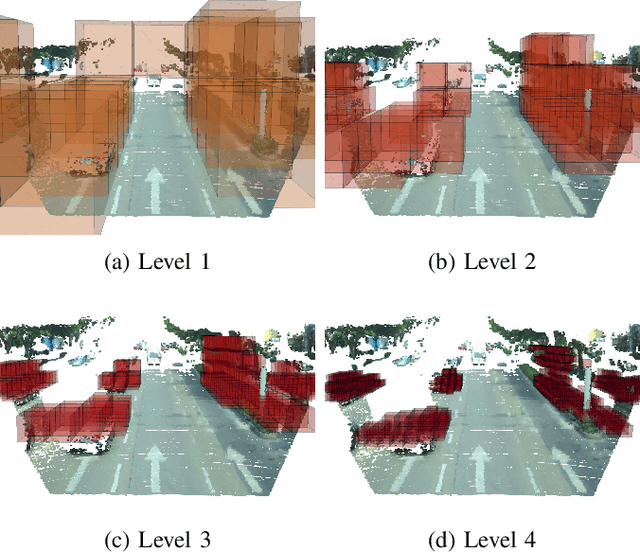

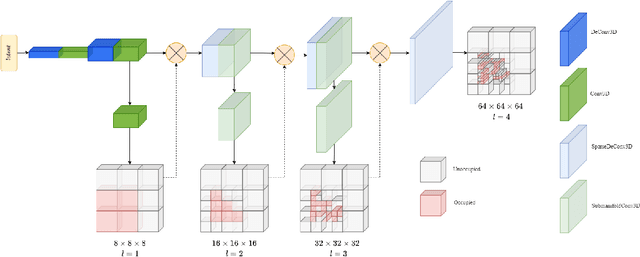

Obstacle detection is a safety-critical problem in robot navigation, where stereo matching is a popular vision-based approach. While deep neural networks have shown impressive results in computer vision, most of the previous obstacle detection works only leverage traditional stereo matching techniques to meet the computational constraints for real-time feedback. This paper proposes a computationally efficient method that leverages a deep neural network to detect occupancy from stereo images directly. Instead of learning the point cloud correspondence from the stereo data, our approach extracts the compact obstacle distribution based on volumetric representations. In addition, we prune the computation of safety irrelevant spaces in a coarse-to-fine manner based on octrees generated by the decoder. As a result, we achieve real-time performance on the onboard computer (NVIDIA Jetson TX2). Our approach detects obstacles accurately in the range of 32 meters and achieves better IoU (Intersection over Union) and CD (Chamfer Distance) scores with only 2% of the computation cost of the state-of-the-art stereo model. Furthermore, we validate our method's robustness and real-world feasibility through autonomous navigation experiments with a real robot. Hence, our work contributes toward closing the gap between the stereo-based system in robot perception and state-of-the-art stereo models in computer vision. To counter the scarcity of high-quality real-world indoor stereo datasets, we collect a 1.36 hours stereo dataset with a Jackal robot which is used to fine-tune our model. The dataset, the code, and more visualizations are available at https://lhy.xyz/stereovoxelnet/
Auto-ViT-Acc: An FPGA-Aware Automatic Acceleration Framework for Vision Transformer with Mixed-Scheme Quantization
Aug 10, 2022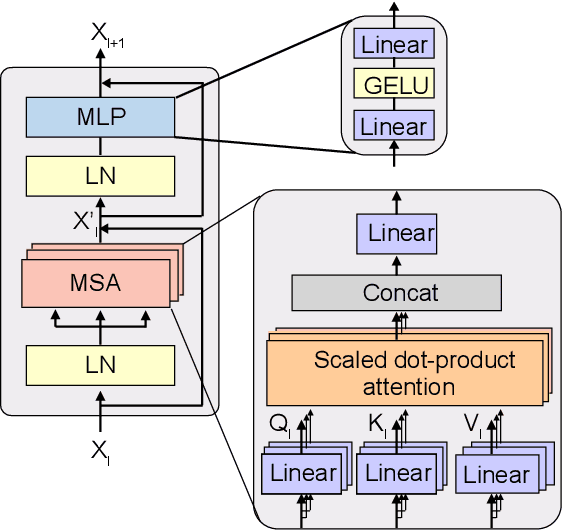
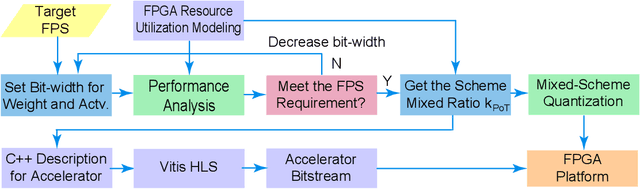
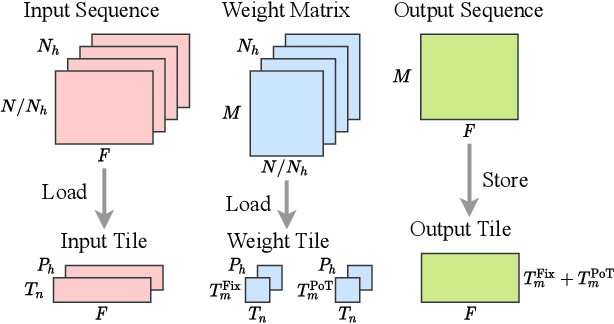
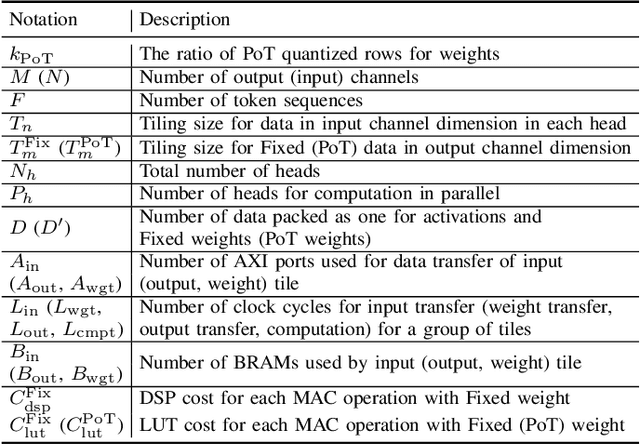
Vision transformers (ViTs) are emerging with significantly improved accuracy in computer vision tasks. However, their complex architecture and enormous computation/storage demand impose urgent needs for new hardware accelerator design methodology. This work proposes an FPGA-aware automatic ViT acceleration framework based on the proposed mixed-scheme quantization. To the best of our knowledge, this is the first FPGA-based ViT acceleration framework exploring model quantization. Compared with state-of-the-art ViT quantization work (algorithmic approach only without hardware acceleration), our quantization achieves 0.47% to 1.36% higher Top-1 accuracy under the same bit-width. Compared with the 32-bit floating-point baseline FPGA accelerator, our accelerator achieves around 5.6x improvement on the frame rate (i.e., 56.8 FPS vs. 10.0 FPS) with 0.71% accuracy drop on ImageNet dataset for DeiT-base.
FAIVConf: Face enhancement for AI-based Video Conference with Low Bit-rate
Jul 08, 2022
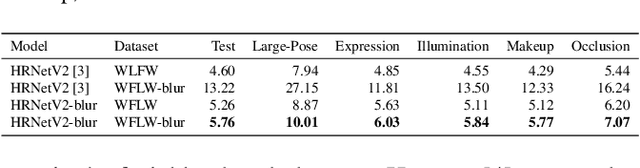
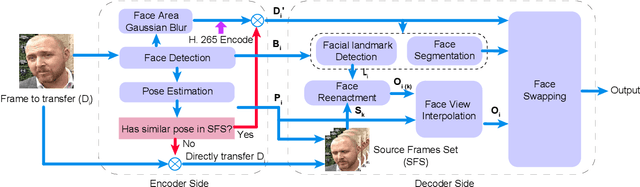
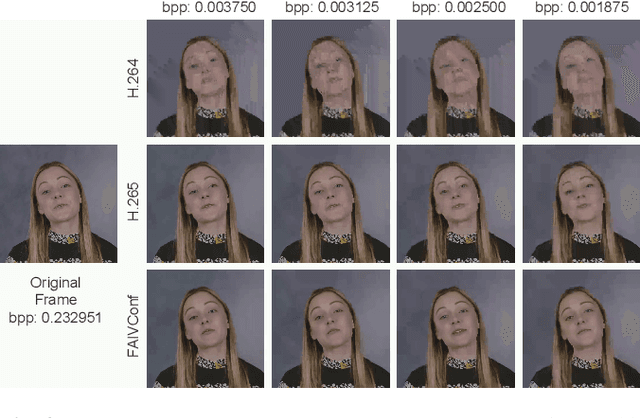
Recently, high-quality video conferencing with fewer transmission bits has become a very hot and challenging problem. We propose FAIVConf, a specially designed video compression framework for video conferencing, based on the effective neural human face generation techniques. FAIVConf brings together several designs to improve the system robustness in real video conference scenarios: face-swapping to avoid artifacts in background animation; facial blurring to decrease transmission bit-rate and maintain the quality of extracted facial landmarks; and dynamic source update for face view interpolation to accommodate a large range of head poses. Our method achieves a significant bit-rate reduction in the video conference and gives much better visual quality under the same bit-rate compared with H.264 and H.265 coding schemes.
F8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization
Feb 10, 2022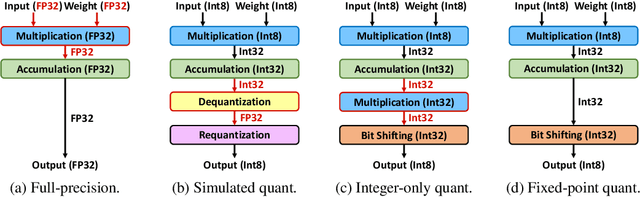
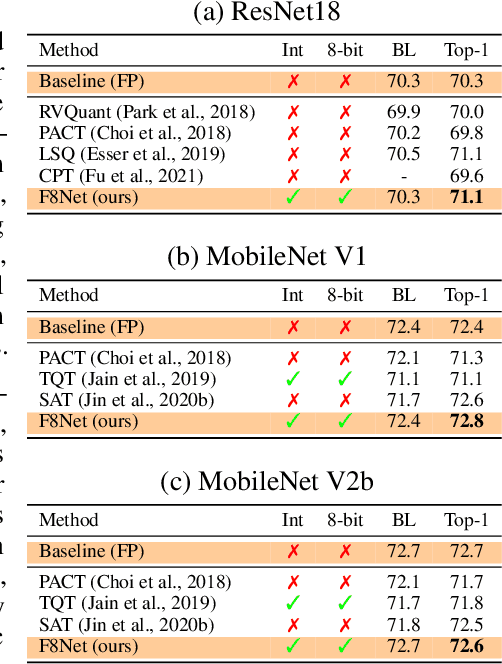
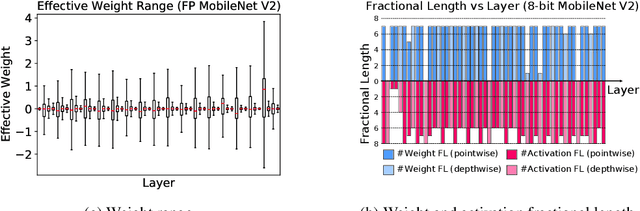
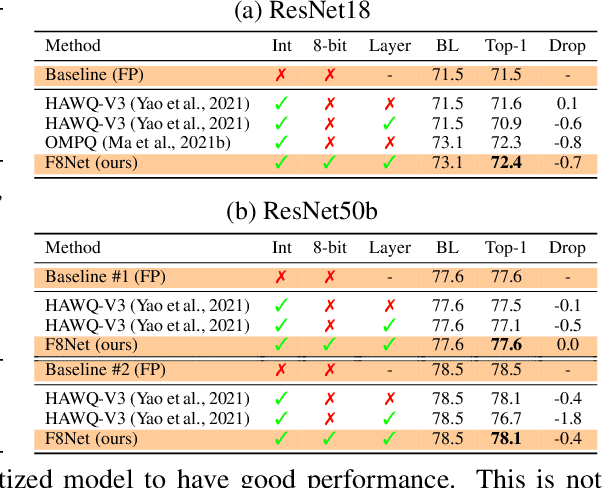
Neural network quantization is a promising compression technique to reduce memory footprint and save energy consumption, potentially leading to real-time inference. However, there is a performance gap between quantized and full-precision models. To reduce it, existing quantization approaches require high-precision INT32 or full-precision multiplication during inference for scaling or dequantization. This introduces a noticeable cost in terms of memory, speed, and required energy. To tackle these issues, we present F8Net, a novel quantization framework consisting of only fixed-point 8-bit multiplication. To derive our method, we first discuss the advantages of fixed-point multiplication with different formats of fixed-point numbers and study the statistical behavior of the associated fixed-point numbers. Second, based on the statistical and algorithmic analysis, we apply different fixed-point formats for weights and activations of different layers. We introduce a novel algorithm to automatically determine the right format for each layer during training. Third, we analyze a previous quantization algorithm -- parameterized clipping activation (PACT) -- and reformulate it using fixed-point arithmetic. Finally, we unify the recently proposed method for quantization fine-tuning and our fixed-point approach to show the potential of our method. We verify F8Net on ImageNet for MobileNet V1/V2 and ResNet18/50. Our approach achieves comparable and better performance, when compared not only to existing quantization techniques with INT32 multiplication or floating-point arithmetic, but also to the full-precision counterparts, achieving state-of-the-art performance.